As we reflect on Trino’s journey in 2021, one thing stands out. Compared to previous years we have seen even further accelerated, tremendous growth. Yes, this is what all these year-in-retrospect blog posts say, but this has some special significance to it. This week marked the one-year anniversary since the project dropped the Presto name and moved to the Trino name. Immediately after the announcement, the Trino GitHub repository started trending in number of stargazers. Up until this point, the PrestoSQL GitHub repository had only amassed 1,600 stargazers in the two years since it had split from the PrestoDB repository. However, within four months after the renaming, the number of stargazers had doubled. GitHub stars, issues, pull requests and commits started growing at a new trajectory.
At the time of writing, we just hit 4,600 stargazers on GitHub. This means, we have grown by over 3,000 stargazers in the last year, a 187% increase. While we are on the subject, let’s talk about the health of the Trino community.
2021 by the numbers #
Let’s take a look at the Trino project growth by the numbers:
- 3679 new commits 💻 in GitHub
- 3015 new stargazers ⭐ in GitHub
- 2450 new members 👋 in Slack
- 1979 pull requests merged ✅ in GitHub
- 1213 issues 📝 created in GitHub
- 988 new followers 🐦 on Twitter
- 525 average weekly members 💬 in Slack
- 491 new subscribers 📺 in YouTube
- 23 Trino Community Broadcast ▶️ episodes
- 17 Trino 🚀 releases
- 13 blog ✍️ posts
- 10 Trino 🍕 meetups
- 1 Trino ⛰️ Summit
Along with the growth we’ve seen in GitHub, we have seen a 47% growth of the Trino Twitter followers this year. The Trino Slack community, where a large amount of troubleshooting and development discussions occur, saw a 75% growth, nearing 6,000 members. Finally, the Trino YouTube channel has seen an impressive 280% growth in subscribers.
A lot of the increase on this channel was due to the Trino Community Broadcast, that brought users and contributors from the community to cover 23 episodes about the following topics:
- 7 episodes on the Trino ecosystem (dbt, Amundsen, Debezium, Superset)
- 4 episodes on the Trino project (Renaming Trino, Intro to Trino, Trinewbies)
- 4 episodes on Trino connectors (Iceberg, Druid, Pinot)
- 4 episodes on Trino internals (Distributed Hash-Joins, Dynamic Filtering, Views)
- 2 episodes on Trino using Kubernetes (Trinetes series)
- 2 episodes on Trino users (LinkedIn, Resurface)
While stargazers, subscribers, episodes, and followers tell the story of the growing awareness of the Trino project with the new name, what about the actual rate of development on the project?
At the start of the year, there were 21,924 commits. This year, we pushed 3,679 commits to the repository, sitting at over 25,600 now. Looking at the graph, this keeps us pretty consistent with 2020’s throughput.
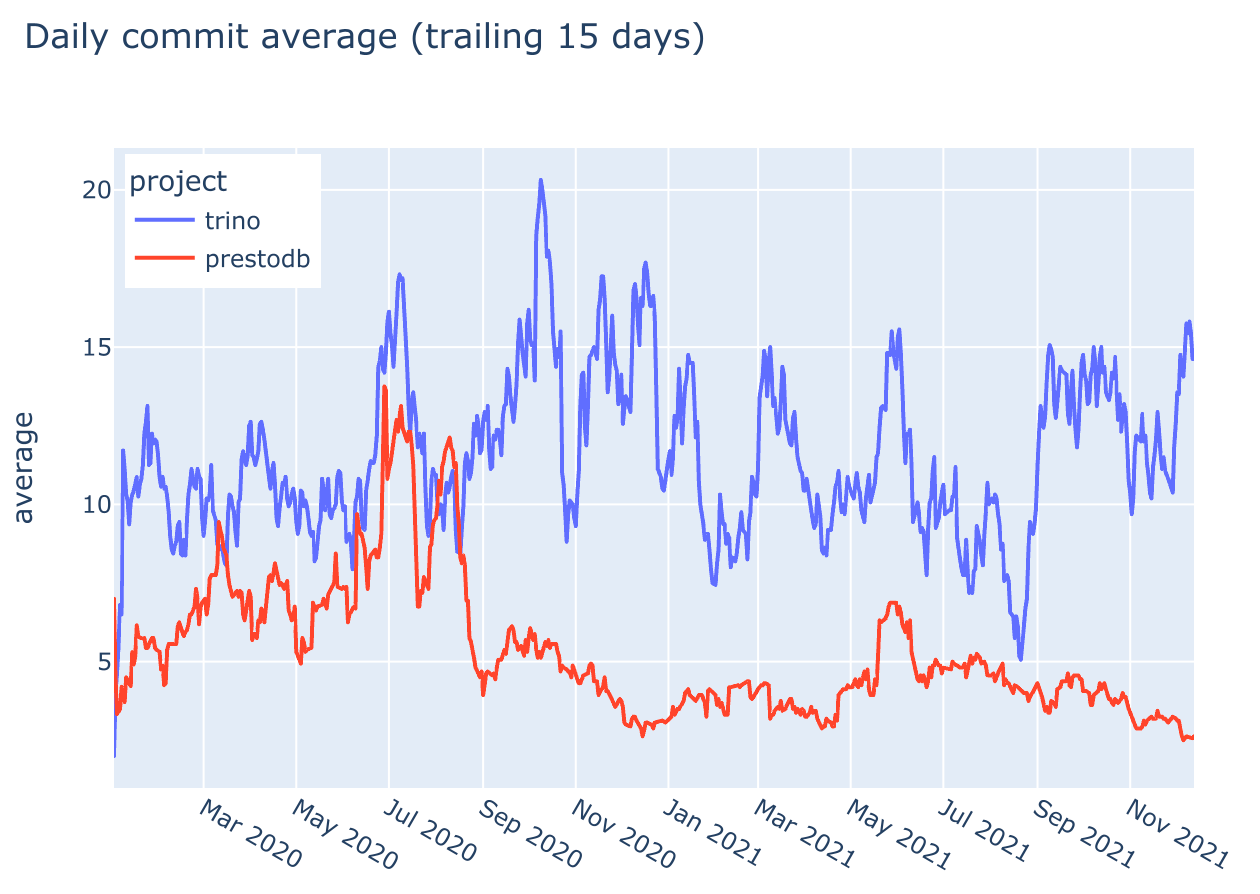
With the project’s trajectory displayed in numbers, let’s examine the top features that landed in Trino this year.
Features #
Here’s a high-level list of the most exciting features that made their way into Trino in 2021. For details and to keep up you can check out the release notes.
SQL language improvements #
SQL language support is crucial for the increasing complexities of queries and usage of Trino. In 2021 we added numerous new language features and improvements:
MATCH_RECOGNIZEa feature that allows for complex analysis across multiple rows. To learn more about this feature watch the Community Broadcast show.WINDOWclause.RANGEandROWSkeyword for usage within a window function.- Time travel support and syntax, like
FOR VERSION AS OFandFOR TIMESTAMP AS OF. UPDATEis supported.- Subquery expressions that return multiple columns. Example:
SELECT x = (VALUES (1, 'a')). - Add support for
ALTER MATERIALIZED VIEW…RENAME TO… - from_geojson_geometry/to_geojson_geometry functions.
- contains function for checking if a CIDR contains an IP address.
listaggfunction returns concatenated values seperated by a specified separator.- soundex function that checks phonetic similarity of two strings.
- format_number function.
SET TIME ZONEto set the current time zone for the session.- Arbitrary queries in
SHOW STATS. CURRENT_CATALOGandCURRENT_SCHEMAsession functions.TRUNCATE TABLEwhich allows for a more efficient delete.DENYstatement, which enables you to remove a user or groups access via SQL.IN <catalog>clause toCREATE ROLE,DROP ROLE,GRANT ROLE,REVOKE ROLE, andSET ROLEto specify the target catalog of the statement instead of using the current session catalog.
Query processing improvements #
- Added support for automatic query retries (this feature is very experimental with some limitations for now).
- Transparent query retries.
- Updated the behavior of
ROWtoJSONcast to produceJSONobjects instead ofJSONarrays. - Column and table lineage tracking in
QueryCompletedEvent.
Performance improvements #
Improved performance for the following operations:
- Querying Parquet data for files containing column indexes.
- Reading dictionary-encoded Parquet files.
- Queries using
rank()window function. - Queries using
sum()andavg()for decimal types. - Queries using
GROUP BYwith single grouping column. - Aggregation on decimal values.
- Evaluation of the
WHEREandSELECTclause. - Computing the product of decimal values with precision larger than 19.
- Queries that process row or array data.
- Queries that contain a
DISTINCTclause. - Reduced memory usage and improved performance of joins.
ORDER BY LIMITperformance was improved when data was pre-sorted.- Node-local Dynamic Filtering
Security #
Added the following improvements and features relevant for authentication, authorization and integration with other security systems:
- Automatic configuration of TLS for secure internal communication.
- Handling of Server Name Indication (SNI) for multiple TLS certificates. This removes the need to provision per-worker TLS certificates.
- Access control for materialized views.
- OAuth2/OIDC opaque access tokens.
- Configuring HTTP proxy for OAuth2 authentication.
- Configuring multiple password authentication plugins.
- Hiding inaccessible columns from
SELECT *statement.
Data Sources #
BigQuery connector #
- Added
CREATE TABLEandDROP TABLEsupport. - Added support for case insensitive name matching for BigQuery views.
- Support reading
bignumerictype whose precision is less than or equal to 38. - Added support for
CREATE SCHEMAandDROP SCHEMAstatements. - Improved support for BigQuery datetime and timestamp types.
Cassandra connector #
- Mapped Cassandra
uuidtype to Trinouuid. - Added support for Cassandra
tupletype. - Changed minimum number of speculative executions from two to one.
- Support for reading user-defined types.
Clickhouse connector #
- Added ClickHouse connector.
- Improved performance of aggregation queries by computing aggregations within
ClickHouse. Currently, the following aggregate functions are eligible for
pushdown:
count,min,max,sumandavg. - Added support for dropping columns.
- Map ClickHouse
UUIDcolumns asUUIDtype in Trino instead ofVARCHAR.
HDFS, S3, Azure and cloud object storage systems #
A core use case of Trino uses the Hive and Iceberg connectors to connect to a data lake. These connectors differ from most as Trino is the sole query engine as opposed to the client calling another system. Here are some changes that for these connectors:
- Enabled Glue statistics to support better query planning when using AWS.
UPDATEsupport for ACID tables- A lot of Hive view improvements.
- Parquet column indexes.
target_max_file_sizeconfiguration to control the file size of data written by Trino.- Streaming uploads to S3 by default to improve performance and reduce disk usage.
- Improved performance for tables with small files and partitioned tables.
- Transparent redirection from a Hive catalog to Iceberg catalog if the table is an Iceberg table.
- Updated to Iceberg 0.11.0 behavior for transforms of dates and timestamps before 1970.
- Added procedure
system.flush_metadata_cache()to flush metadata caches. - Avoid generating splits for empty files.
- Sped up Iceberg query performance when dynamic filtering can be leveraged.
- Increased Iceberg performance when reading timestamps from Parquet files.
- Improved Iceberg performance for queries on nested data through dereference pushdown.
- Added support for
INSERT OVERWRITEoperations on S3-backed tables. - Made the Iceberg
uuidtype available. - Trino views made available in Iceberg.
Elasticsearch connector #
- Added support for reading fields as
jsonvalues. - Fixed failure when documents contain fields of unsupported types.
- Added support for
scaled_floattype. - Added support for assuming an IAM role.
- Added retry requests with backoff when Elasticsearch is overloaded.
- Better support for Elastic Cloud.
MongoDB connector #
- Added
timestamp_objectid()function. - Enabled
mongodb.socket-keep-aliveconfig property by default. - Add support for
jsontype. - Support reading MongoDB
DBReftype. - Allow skipping creation of an index for the
_schemacollection, if it already exists. - Added support to redact the value of
mongodb.credentialsin the server log. - Added support for dropping columns.
MySQL connector #
- Added support for reading and writing
timestampvalues with precision higher than three. - Added support for predicate pushdown on
timestampcolumns. - Exclude an internal
sysschema from schema listings.
Pinot connector #
- Updated Pinot connector to be compatible with versions >= 0.8.0 and drop support for older versions.
- Added support for pushdown of filters on
varbinarycolumns to Pinot. - Fixed incorrect results for queries that contain aggregations and
INandNOT INfilters over varchar columns. - Fixed failure for queries with filters on
realordoublecolumns having+Infinityor-Infinityvalues. - Implemented aggregation pushdown.
- Allowed HTTPS URLs in
pinot.controller-urls.
Phoenix connector #
- Phoenix 5 support was added.
- Reduced memory usage for some queries.
- Improved performance by adding ability to parallelize queries within Trino.
Features added to various connectors #
In addition to the above some more features were added that apply to connectors that use common code. These features improve performance using:
- Statistical aggregate function pushdown
- TopN pushdown and join pushdown
- Improved planning times by reducing number of connections opened
- Improved performance by improving metadata caching hit rate
- Rule based identifier mapping support
- DELETE, non-transactional inserts and write-batch-size
- Metadata cache max size
- TRUNCATE TABLE
- Improved handling of Gregorian - Julian switch for date type
- Ensured correctness when pushing down predicates and topN to remote system that is case-insensitive or sorts differently from Trino.
Runtime improvements #
There are a lot of performance improvements to list from the release notes. Here are a few examples:
- Improved coordinator CPU utilization.
- Improved query performance by reducing CPU overhead of repartitioning data across worker nodes.
- Reduced graceful shutdown time for worker nodes.
Everything else #
- HTTP Event listener
- Added support for ARM64 in the Trino Docker image.
- Added
clearcommand to the Trino CLI to clear the screen. - Improved tab completion for the Trino CLI.
- Custom connector metrics.
- Fixed many, many, many bugs!
Trino Summit #
In 2021 we also enjoyed a successful inaugural Trino Summit, hosted by Starburst, with well over 500 attendees. There were wonderful talks given at this event from companies like Doordash, EA, LinkedIn, Netflix, Robinhood, Stream Native, and Tabular. If you missed this event, we have the recordings and slides available.
As a teaser, the event started with Commander Bun Bun playing guitar to AC/DC’s, “Back In Black”.
Renaming from PrestoSQL to Trino #
As mentioned above, we renamed the project this year. What followed, was an
outpouring of support and shock from the larger tech community. Community
members immediately got to work. The project had to change the namespace
practically overnight from the io.prestosql namespace to io.trino and a
migration blog post
was published. Due to the hasty nature of the Linux Foundation to enforce the
Presto trademark, users had to adapt quickly.
This confused many in the community,
especially once the ownership of old PrestoSQL accounts were taken down by the
Linux Foundation. The https://prestosql.io site had broken documentation links,
JDBC urls had to change from jdbc:presto to jdbc:trino, header protocol
names had to be changed from prefix X-Presto- to X-Trino-, and various other
user impacting changes had to be made in the matter of weeks. Even the legacy
Docker images were removed from the prestosql/presto Docker repository,
causing disruptions for many users who immediately had to upgrade to the
trinodb/trino Docker repository.
We reached out to multiple projects to update compatibility to Trino.
- DBeaver
- QueryBook
- Homebrew
- dbt
- sqlalchemy
- sqlpad
- Apache Superset
- Redash
- Awesome Java
- Awesome For Beginners
- Airflow
- trino-gateway
- Metabase
- and so much more…
Despite the breaking changes, once the immediate hurdles fell behind, not only was the community excited and supportive about the brand change, but particularly they were all loving the new mascot. Our adorable bunny was soon after named Commander Bun Bun by the community.
2022 Roadmap: Project Tardigrade #
One of the interesting developments that came out of Trino Summit was a feature Trino co-creator, Martin, talked about in the State of Trino presentation. He proposed adding granular fault-tolerance and features to improve performance in the core engine. While Trino has been proven to run batch analytics workloads at scale, many have avoided long-running batch jobs in fear of a query failure. The fault-tolerance feature introduces a first step for the Trino project to gain first-class support for long-running batch queries at massive scale.
The granular fault-tolerance is being thoughtfully crafted to maintain the speed advantage that Trino has over other query engines, while increasing the resiliency of queries. In other words, rather than when a query runs out of resources or fails for any other reason, a subset of the query is retried. To support this intermediate stage data is persisted to replicated RAM or SSD.

The project to introduce granular fault-tolerance into Trino is called Project Tardigrade. It is a focus for many contributors now, and we will introduce you to details in the coming months. The project is named after the microscopic Tardigrades that are the worlds most indestructible creatures, akin to the resiliency we are adding to Trino’s queries. We look forward to telling you more as features unfold.
Along with Project Tardigrade will be a series of changes focused around faster performance in the query engine using columnar evaluation, adaptive planning, and better scheduling for SIMD and GPU processors. We also will be working on dynamically resolved functions, MERGE support, Time Travel queries in data lake connectors, Java 17, improved caching mechanisms, and much much more!
Conclusion #
In summary, living this first year under the banner of Trino was nothing short of a wild endeavor. Any engineer knows that naming things is hard, and renaming things is all the more difficult.
As we head into 2022, we can be certain of one thing. Trino will be reaching into newer areas of development and breaking norms just as it did as Presto in previous eras. The adoption of native fault-tolerance to a lightning fast query engine will bring Trino to a new level of adoption. Keep your eyes peeled for more about Project Tardigrade.
Along with Project Tardigrade, we are looking forward to another year filled with features, issues, and suggestions from our amazing and passionate community. Thank you all for an incredible year. We can’t wait to see what you all bring in 2022!