Audio
Video
Video sections
- Concept of the week: What is Trino? (1023s)
- PR of the week: PR 8821 Add HTTP/S query event logger (3515s)
- Question of the week: Does the Hive connector depend on the Hive runtime? (3763s)
Release 364
Release 364 is just around the corner, here is Manfred’s release preview:
ALTER MATERIALIZED VIEW ... RENAME TO- A whole bunch of performance improvements
- Elasticsearch connector no longer fails if fields with unsupported types exist
- Hive connector has optimize procedure now!
- Parquet and Avro fixes and improvements
Concept of the week: What is Trino?
Trino is the project created by Martin Traverso, Dain Sundstrom, David Phillips, and Eric Hwang in 2012 to replace the 300PB Hive data warehouse at Facebook. The goal of Trino is to run fast ad-hoc analytics queries over big data file systems like HDFS and object stores like S3.
An initially unintended but now characteristic feature of Trino is its ability to execute federated queries over various distributed data sources. This includes, but is not limited to: Accumulo, BigQuery, Apache Cassandra, ClickHouse, Druid, Elasticsearch, Google Sheets, Apache Iceberg, Apache Hive, JMX, Apache Kafka, Kinesis, Kudu, MongoDB, MySQL, Oracle, Apache Phoenix, Apache Pinot, PostgreSQL, Prometheus, Redis, Redshift, SingleStore (MemSQL), Microsoft SQL Server.
How does Trino query across everything from data lakes, SQL, and NoSQL databases at unprecedented speeds? It helps to start by going over Trino’s architecture:
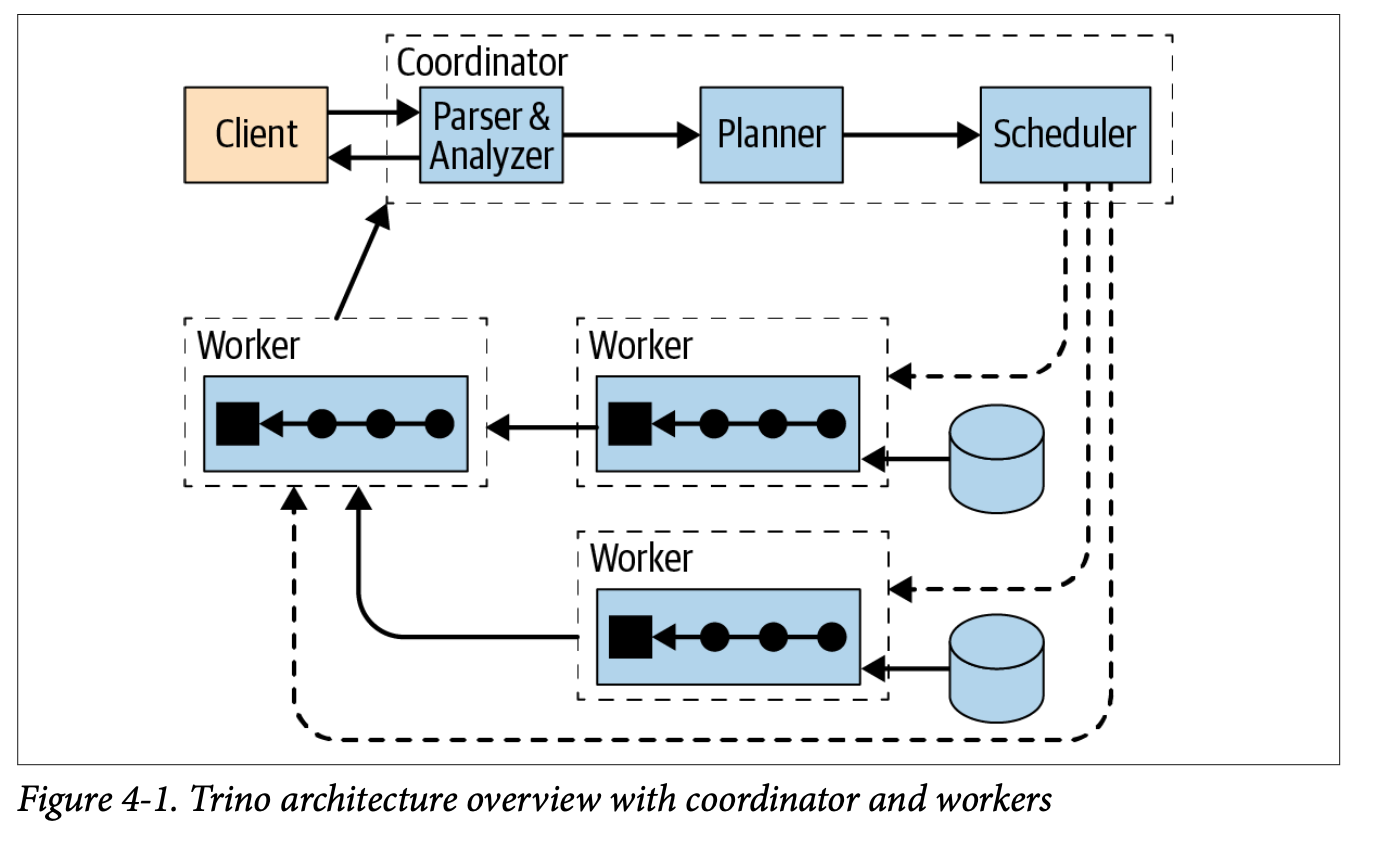
Source: Trino: The Definitive Guide.
Trino consists of two types of nodes, coordinator and worker nodes. The coordinator plans, and schedules the processing of SQL queries. The queries are submitted by users directly or with connected SQL reporting tools. The workers actually carry out more of the processing by reading the data from the source or performing various operations within the task(s) they are assigned.
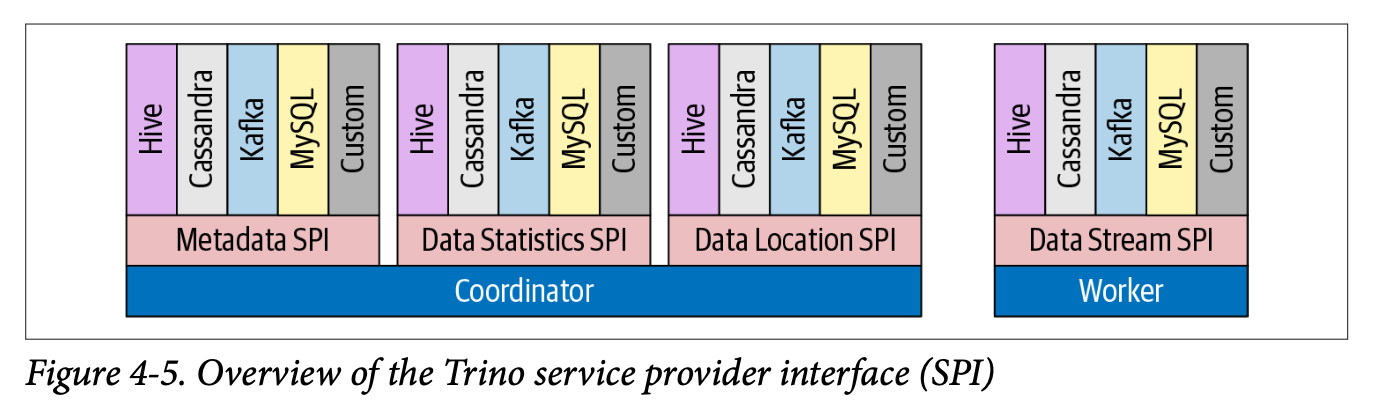
Source: Trino: The Definitive Guide.
Trino is able to query over multiple data types by exposing a common interface called the SPI (Service Provider Interface) that enables the core engine to treat the interactions with each data source the same. Each connector must then implement the SPI which includes exposing metadata, statistics, data location, and establishing one or more connections with an underlying data source.
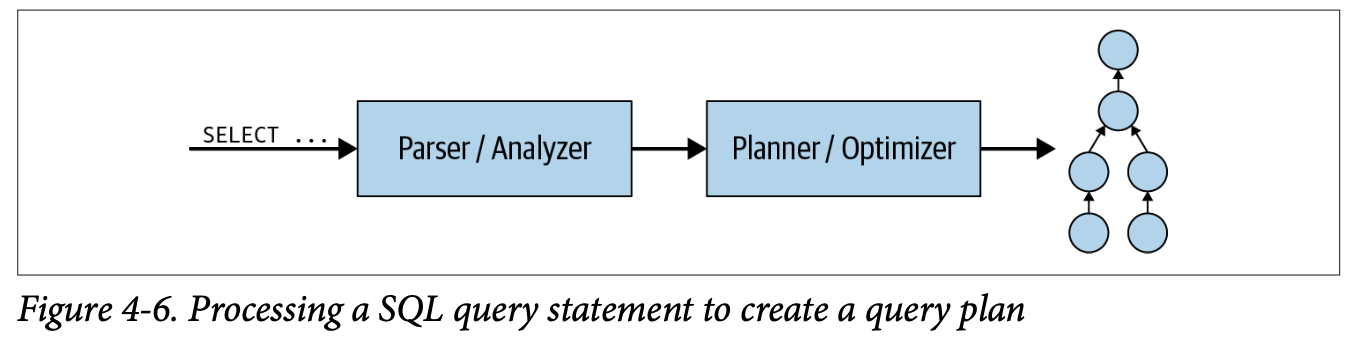
Source: Trino: The Definitive Guide.
Many of these interfaces are used in the coordinator during the analysis and
planning phases. The analyzer, for example, uses the metadata SPI to make sure
the table in the FROM clause actually exists in the data source.
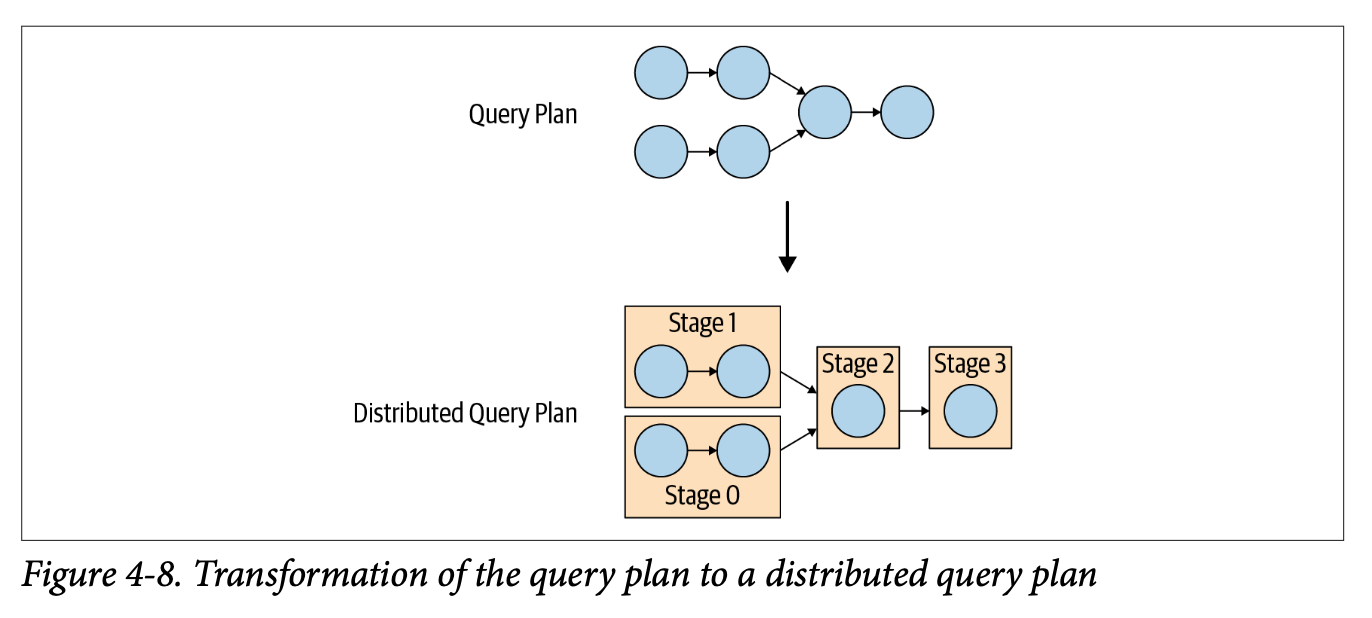
Source: Trino: The Definitive Guide.
Once a logical query plan is generated, the coordinator then converts this to a distributed query plan that maps actions into stages that contain tasks to be run on nodes. Stages model the sequence of events and a directed acyclic graph (DAG).
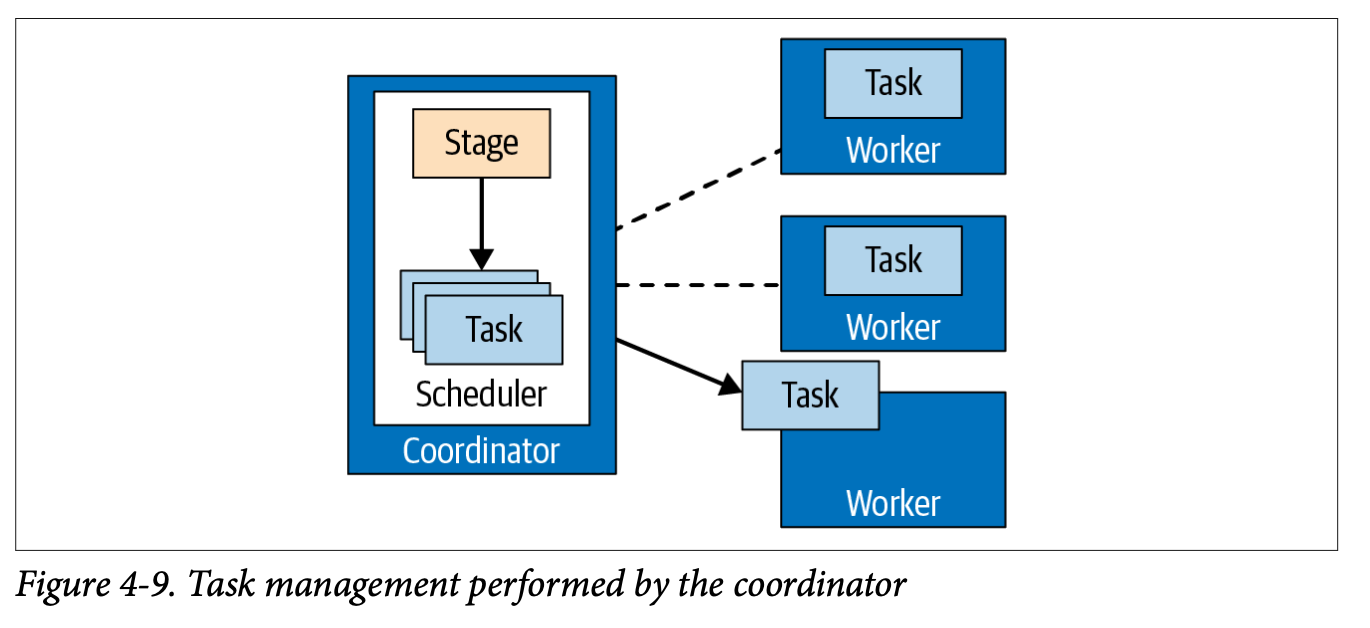
Source: Trino: The Definitive Guide.
The coordinator then schedules tasks over the worker nodes as efficiently as possible, depending on the physical layout and distribution of the data.
Source: Trino: The Definitive Guide.
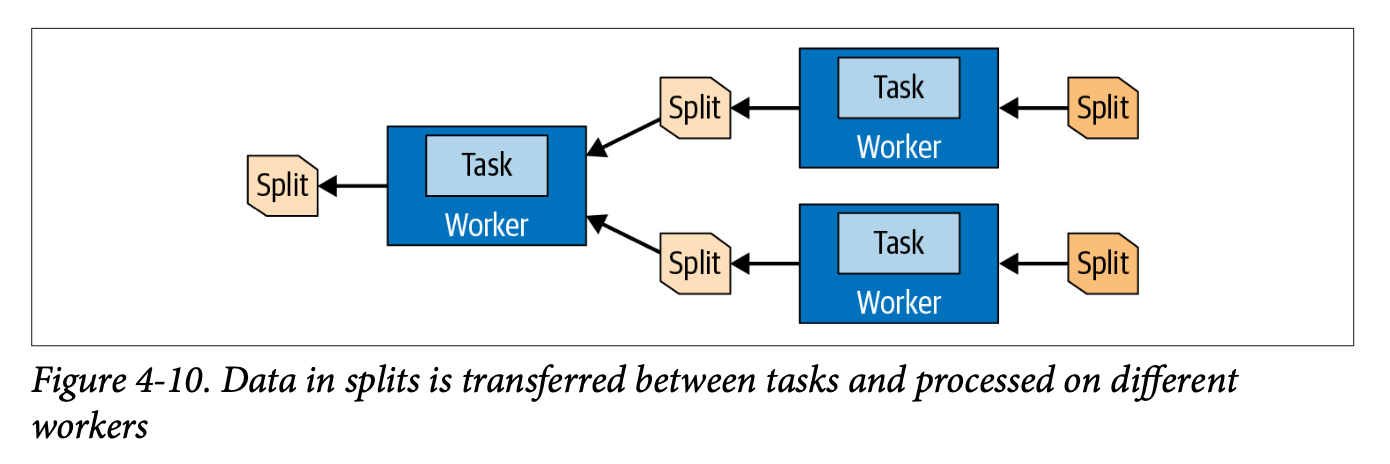
Data is split and distributed across the worker nodes to provide inter-node parallelism.
Source: Trino: The Definitive Guide.
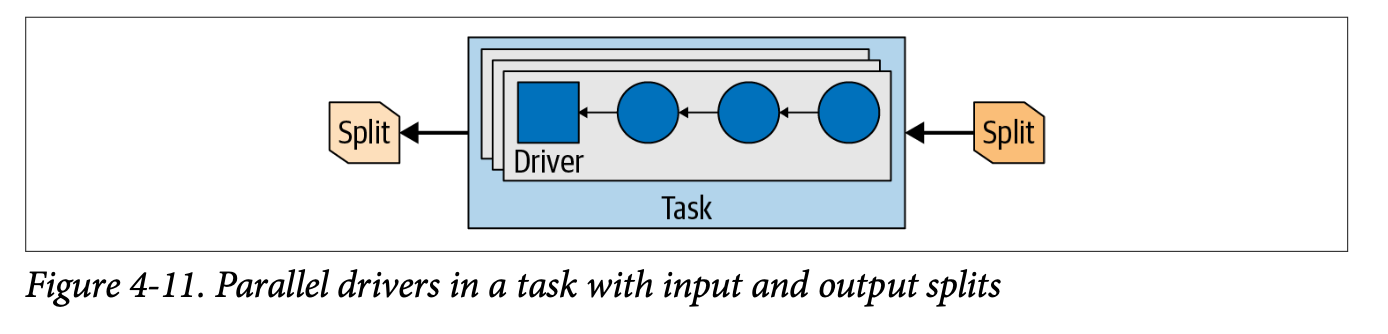
Once this data arrives to the worker node, it is further divided and processed in parallel. Workers submit the processed data back to coordinator. Finally, the coordinator provides the results of the query to the user.
PR 8821 Add HTTP/S query event logger
Pull request 8821 enables Trino cluster owners to log query processing metadata by submitting it to an HTTP endpoint. This may be used for usage monitoring and alarming, but it might also be used to extract analytics on cluster usage, such as tables/column usage metrics.
Query events are serialized to JSON and sent to the provided address over HTTP or over HTTPS. Configuration allows selecting which events should be included.
Thanks for the contribution mosiac1 and others at Bloomberg!
Read the docs to learn more about this exciting feature!
Question of the week: Does the Hive connector depend on the Hive runtime?
This week’s question covers a lot of the confusion around the Hive connector. In short, the answer is that the Hive runtime is not required. There’s more information available in the Intro to the Hive Connector blog.
Videos
Trino Meetup groups
- Virtual
- East Coast (US)
- West Coast (US)
- Mid West (US)
If you want to learn more about Trino, check out the definitive guide from OReilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.