Audio
Video
Video sections
- Concept of the month: High availability with Trino (1223s)
- PR of the month: PR 8956 Add support for external db for schema management in MongoDB connector (3849s)
- Bonus PR of the month: PR 8202 Metadata for alias in elasticsearch connector only uses the first mapping (4515s)
- Demo of the month: Trino Fiddle: A tool for easy online testing and sharing of Trino SQL problems and their solutions (5528s)
- Question of the month: Does Trino support CarbonData? (5889s)
Guests
- Ramesh Bhanan, Vice President, at Goldman Sachs (@ramesh-bhanan-byndoor).
- Sambit Dikshit, Managing Director, Tech Fellow at Goldman Sachs (@sambitdixit).
- Siddhant Chadha, Senior Data Engineer at Goldman Sachs (@siddhant-chadha).
- Suman Baliganahalli Narayan Murthy, Vice President at Goldman Sachs (@suman-b-n).
- Sumit Halder, Vice President at Goldman Sachs (@sumit-halder).
Releases 369, 370, and 371
Trino 369
- Experimental support for task level retries.
- Support for groups in OAuth2 claims.
- Column comments in ClickHouse connector.
- Write Bloom filters in ORC files.
- Procedure for optimizing Iceberg tables.
Trino 370
- Add CLI support for ARM64.
- Improved performance for ORC.
- Improved performance for map and row types.
- Reduced latency for OAuth2.0 authentication.
Trino 371
- Support for secrets and user group selector in resource group manager.
- Support AWS role session name in S3 security mapping configuration.
- Many bug fixes.
Notes from Manfred
- Add support for using PostgreSQL and Oracle as backend database for resource groups.
- Remove
spill-order-by,spill-window-operator, andquery.max-total-memory-per-node. - Add support for
ALTER MATERIALIZED VIEW ... SET PROPERTIESin the engine. - Prevent hanging query execution on failures with phased execution policy.
- Support for renaming schemas in PostgreSQL and Redshift connectors.
- Lots of improvements on Clickhouse connector, thanks Yuya!
- Update to newer ClickHouse version removed support for Altinity 20.3.
$propertiestable and other hidden tables in Iceberg connector, including docs.- Automatically adjust
ulimitsetting when using the RPM package. - Docker images changes to UBI.
- Remove support/need for
allow-drop-tablecatalog property in JDBC connectors. - A bunch of SPI changes.
- DML with Iceberg connector with fault tolerant mode and more Tardigrade improvements.
- Drop support for Kudu 1.13.0.
More detailed information is available in the Trino 369, Trino 370, and Trino 371 release notes.
Concept of the month: High availability with Trino
Goldman Sachs uses Trino to reduce last-mile ETL, and provide a unified way of accessing data through federated joins. Making a variety of data sets from different sources available in one spot for our data science team was a tall order. Data must be quickly accessible to data consumers, and systems like Trino must be reliable for users to trust this singular access point for their data.
In order for analysts and data scientists to use these services, they first need to trust in the system. It was vital to Goldman Sachs that Trino has high availability. In the event of any failure, another Trino cluster is available to process requests.
Integrating Trino into the Goldman Sachs internal ecosystem
Before high availability was a concern, the team had to first integrate Trino to meet their requirements. This included integrating with internal security systems, observability systems, and credential stores. It also meant adding integration with their governance services that manage cataloguing services and data discovery engines. Finally, while many of the Trino connectors that the team intended to use exist, there were many missing features and performance enhancements that would lead to a better user experience and more adoption. The team has since taken it upon themselves to work on these features and contribute them back to Trino. We will cover some of these contributions in the PR segment of this show.
Achieving scaling and high availability
Once the team had much of Trino running for some initial use cases, the next step was to improve support for more simultaneous use cases and highly concurrent workloads. The team wanted trust in the system and so as they scaled the ability to run blue-green deployments, enable resources isolation, and have highly available clusters through failures became much more pertinant.
Trino ecosystem at Goldman Sachs
Here is an overview of the Goldman Sachs ecosystem. It showcases the preexisting services that needed to connect to Trino, the catalogs supported, and the method in which Goldman Sachs achieves high availability through supporting multiple clusters in various groups.
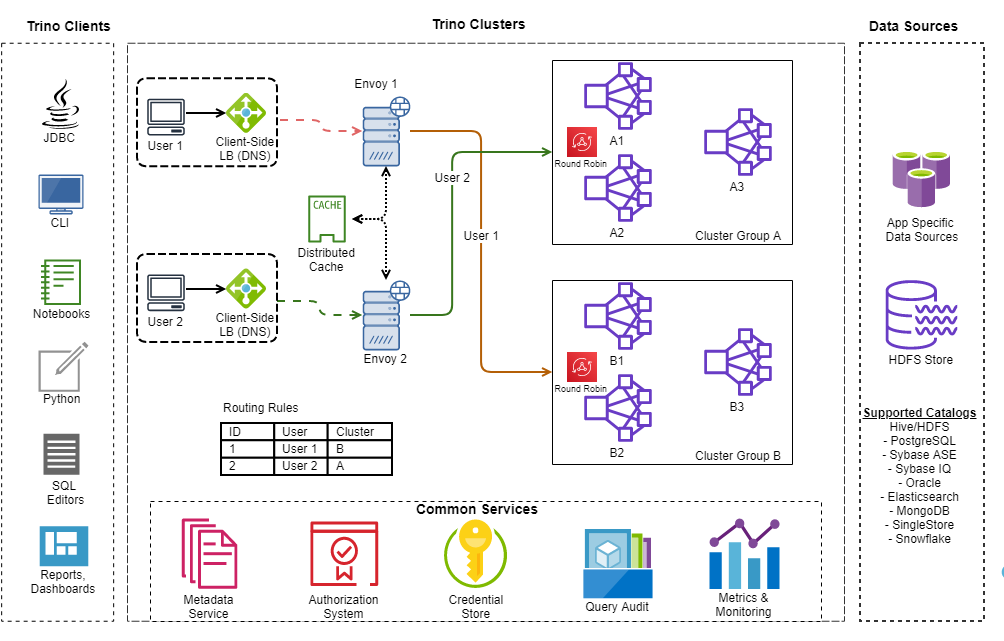
Source: Goldman Sachs Blog
Dynamic query routing
In order to ensure that all the clusters receive an even distribution the team created services that enable dynamic query routing across the different cluster groups.
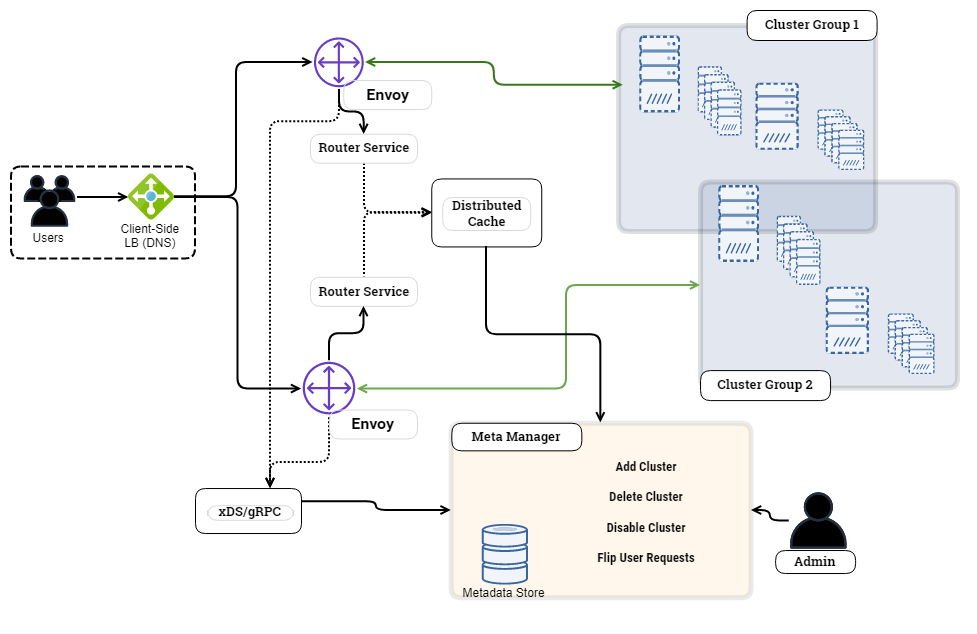
Source: Goldman Sachs Blog
Query routing components
- Envoy Proxy - open source edge and service proxy that provides features such as routing, traffic management, load balancing, external authorization, rate limiting, and more.
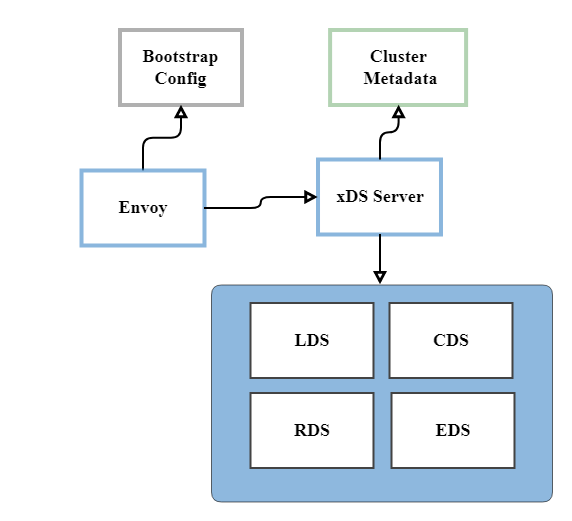
Source: Goldman Sachs Blog
- Cluster Groups - cluster group is a set of various Trino clusters that can be assigned traffic by the
- Cluster Metadata Service - a service that provides the Envoy routers with all the cluster related configurations
- Router Service
- Envoy Control Plane - The Envoy Control Plane is an xDs gRPC-based service, that is responsible for providing dynamic configurations to Envoy.
- Upstream Cluster Selection - Envoy provides HTTP filters to parse and modify
both request and response headers. We use a custom Lua filter to parse the
request and extract the
x-trino-userheader. Then, we call the router service, which returns the upstream cluster address.
PR of the month: PR 8956 Add support for external db for schema management in MongoDB connector
This month’s PR of the month comes from today’s guest Siddhant to solve this issue related to the MongoDB connector.
Siddhant created the issue in response to the common problem that MongoDB connector users face when they don’t have write capability in the Mongo system. Since MongoDB has no implicit schema, Trino uses a schema definition that is written to a special MongoDB database. This PR enables users without write access to create an external location to store their schema to avoid this issue.
Thanks Siddhant for raising this issue, as it’s a common issue beginners using the MongoDB connector face commonly.
Bonus PR of the month: PR 8202 Metadata for alias in Elasticsearch connector only uses the first mapping
This bonus PR of the month comes from another one of today’s guests, Suman. It solves multiple issues, meaning this feature is in high demand!
The problem brought up by these issues also have to do with how we are mapping schemas over NoSQL databases that don’t implicitely have a schema. In this case Elasticsearch stores it’s schema in an object called a mapping. This mapping can be strict or dynamic for various portions of the document that gets inserted. The object that correlates to a table in Elasticsearch is called an index. To keep Elasticsearch fast, multiple indexes are created periodically to support a given document type similar to partitioning in a database. In general, these index follow a very common mapping for a given type, but the reality is that Elasticsearch allows you to vary from the mapping. Trino currently simplifies the way this is done by only reading the first mapping and assuming that all indexes and documents follow this schema. This pull request addresses this issue by scanning a much larger sample of mappings and merging the schema to handle any conflicts. It then goes further to cache these merged mappings for a given amount of time.
Thanks for all of your continued work on this Suman! It will help a lot!
Demo of the month: Trino Fiddle: A tool for easy online testing and sharing of Trino SQL problems and their solutions
This months demo showcases a tool that Brian modified from SQL Fiddle tool called Trino Fiddle. This tool will allow Trino users to share problems and answer questions that other Trino users are facing.
Question of the month: Does Trino support CarbonData?
This month’s question of the month comes from Mahebub Sayyed on Trino Forum. Mahebub asks, “Does Trino support CarbonData?”
The answer is a little tricky, but it can be done!
CarbonData currently maintains a connector called carbondata-presto that works with an older version of Trino, version 333 (an io.prestosql version before the rename). Someone has already opened a PR to update this connector to a current Trino version that they worked on in the middle of 2021 and hasn’t made much progress recently.
That being said, you could build and use the Trino version of the connector this person was working on, and see if it works for you. If you are running on a version of Trino that is older than 351, you should be able to use the existing carbondata-presto connector.
If anyone feels motivated, it would be wonderful if you could help get this contributed to the CarbonData project, or even work with them to have it land in the Trino project!
Events, news, and various links
Blogs and resources
- Enabling Highly Available Trino Clusters at Goldman Sachs
- Video: Building a Federated Cost-Effective Highly Efficient Query Platform
- Goldman Sachs Developer Blog
- Goldman Sachs Careers Page
- Follow @GSDeveloper on Twitter
Trino Meetup groups
- Virtual
- East Coast (US)
- West Coast (US)
- Mid West (US)
If you want to learn more about Trino, check out the definitive guide from OReilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.