A pivotal summer
18 Jul 2026 | Martin Traverso
Last month we called Trino 482 the summer of grammar release, because it closed so many small gaps in Trino’s dialect of SQL at once. Those additions were mostly about breadth: a long list of standard predicates and forms, each a modest convenience on its own.
Trino 483 keeps the season going, but the character is different. This release
lands a handful of larger, more powerful additions instead of a dozen small gaps.
They change the shape of the queries you write rather than just tidying them
up. One of them, PIVOT, is big enough to carry the release on its own. As
before, every example is live. Hit Run and watch Trino 483 evaluate it.

Trino's summer of grammar
26 Jun 2026 | Martin Traverso, Mateusz Gajewski
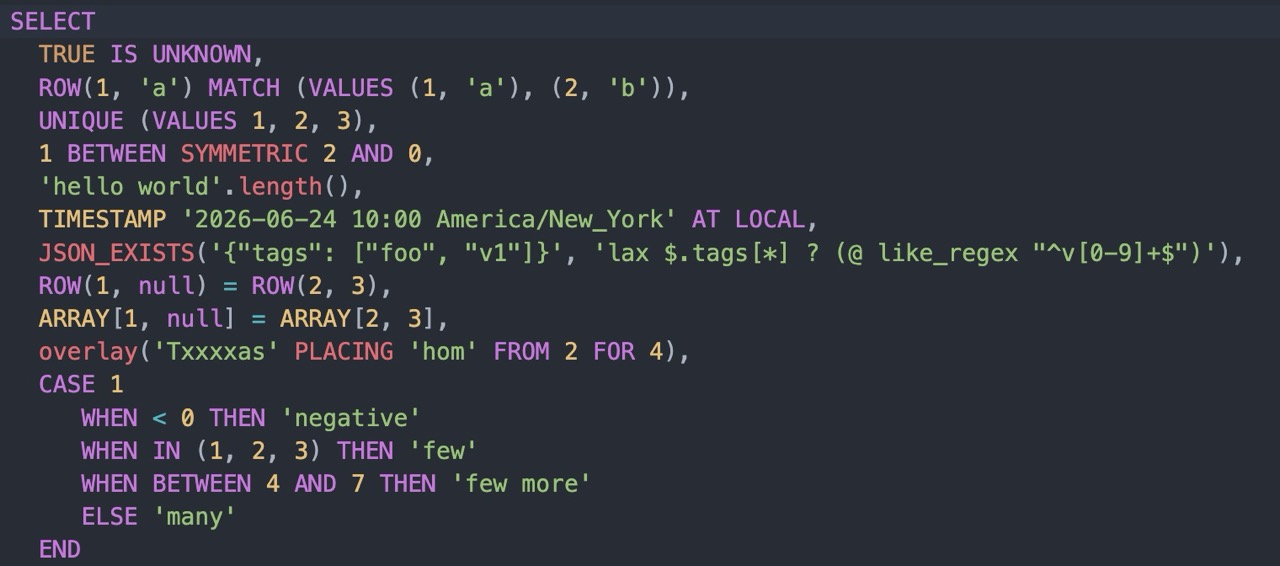
What a query engine runs, before anything else, is a language. And like any language, SQL is defined by its grammar: the predicates, operators, and forms you’re allowed to write down. Trino has always spoken SQL fluently, but the ISO 9075 standard is a big book, and there have always been a few corners of it we hadn’t gotten around to implementing yet.
Trino 482 closes a remarkable number of those gaps in a single release. So many, in fact, that we started calling it the summer of grammar. This post walks through the new language features, and because reading SQL is never quite as convincing as running it, every example below is live. Hit Run and watch Trino 482 evaluate it for real.
Introducing the NUMBER data type
25 Mar 2026 | Piotr Findeisen, Starburst Data
One of Trino’s core strengths is breaking down data silos—enabling data engineers to query diverse data sources through a single SQL interface. However, when those sources use high-precision numeric types beyond Trino’s 38-digit DECIMAL limit, that promise breaks down. Users faced an impossible choice: skip the columns entirely and lose access to critical data, or accept lossy rounding that compromises data integrity.
This challenge required a new approach: a dedicated data type for high-precision, variable-scale decimals.

Recent
Core Principles and Design Practices of OLAP Engines
27 Mar 2025 | Yiteng Xu, Yingju Gao, Manfred Moser
Yiteng Xu and Yingju Gao are proudly announcing the new book “Core Principle and Design Practices of OLAP Engines” from China Machine Press. This is great news for the Trino...
Twenty four
03 Mar 2025 | Manfred Moser, Mateusz Gajewski
Six month ago we adopted Java 23 as requirement, following our standard procedure to upgrade with each Java version as soon as it becomes available. This allows us to take...
Out with the old file system
10 Feb 2025 | Manfred Moser, David Phillips, Mateusz Gajewski
What a long journey it has been! From the start Trino supported querying Hive data and used libraries from the Hive and Hadoop ecosystem. With the release of Trino 470...
Trino in 2024 and beyond
07 Jan 2025 | Manfred Moser
Wow, what an amazing year 2024 was for Trino! Martin Traverso presented about the achievements and progress of the project at the recent Trino Summit 2024. Let me dive deeper...
Trino Summit 2024 resources
18 Dec 2024 | Manfred Moser, Monica Miller, Anna Schibli
What a view we had at the summit! Over 700 live attendees enjoyed the sessions and learned more about Trino-related use cases and projects. Now it is time for the...
The long journey to Apache Ranger
02 Dec 2024 | Manfred Moser
Apache Ranger has arrived! With the new Trino 466 you all get another jam-packed release of Trino awesomeness. One of the goodies is a new plugin for access control for...
The glorious lineup for Trino Summit 2024
22 Nov 2024 | Manfred Moser, Monica Miller, Anna Schibli
We just wrapped up our mini training series SQL basecamps before Trino Summit, and now Trino Summit 2024 is less than three busy weeks away. It’s a good thing that...
View the SQL basecamps before Trino Summit
21 Nov 2024 | Manfred Moser
Trino Summit is inching closer fast, and we are busy with all the preparation. Nevertheless, we thought we bring you some more SQL and Trino-related training. The two live classes...
Trino and Javascript?! YES!
18 Nov 2024 | Manfred Moser
Trino is written in Java. Trino contributors and maintainers are often veterans in the Java ecosystem and community, and Trino is very modern when it comes to Java. For example,...