Trino is known for being the fastest SQL on Hadoop engine, and our custom ORC reader implementation is a big reason for this speed – now it is even faster!
Why is this important? #
For the TPC-DS benchmark, the new reader reduced the global query time by ~5% and CPU usage by ~9%, which improves user experience while reducing the cost.
What improved? #
ORC uses a two step system to decode data. The first step is a traditional compression algorithm like gzip that generically reduces data size. The second step has data type specific compression algorithms that convert the raw bytes into values (e.g., text, numbers, timestamps). It is this latter step that we improved.
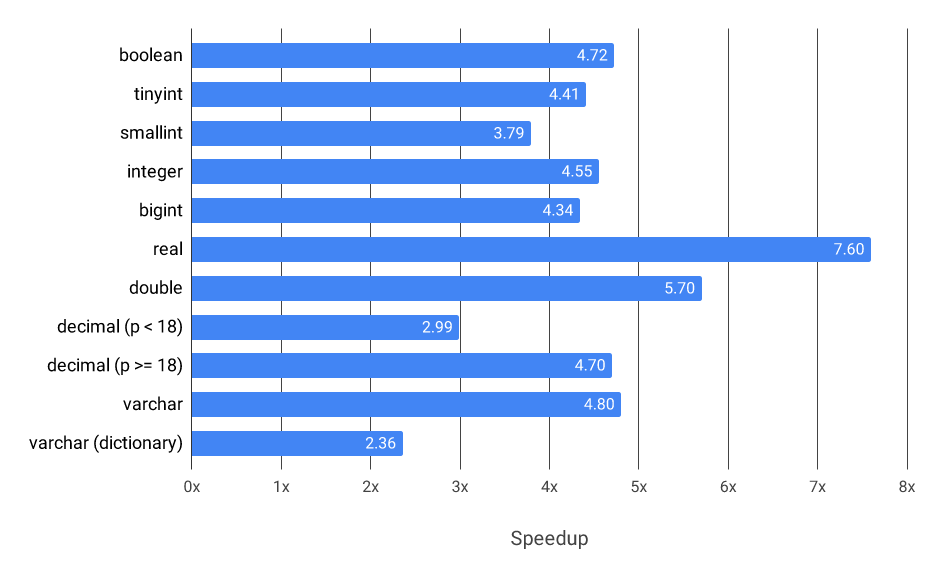
How much faster is the decoder? #

Why exactly is this faster? #
Explaining why the new code is faster requires a brief explanation of the existing code. In the old code, a typical value reader looked like this:
if (dataStream == null) {
presentStream.skip(nextBatchSize);
return RunLengthEncodedBlock.create(type, null, nextBatchSize);
}
BlockBuilder builder = type.createBlockBuilder(null, nextBatchSize);
if (presentStream == null) {
for (int i = 0; i < nextBatchSize; i++) {
type.writeLong(builder, dataStream.next());
}
}
else {
for (int i = 0; i < nextBatchSize; i++) {
if (presentStream.nextBit()) {
type.writeLong(builder, dataStream.next());
}
else {
builder.appendNull();
}
}
}
return builder.build();
This code does a few things well. First, for the all values are null case, it returns a run length encoded block which has custom optimizations throughout Trino (this optimization was recently added by Praveen Krishna). Secondly, it separates the unconditional no nulls loop from the conditional mixed nulls loop. It is common to have a column without nulls, so it makes sense to split this out, since unconditional loops are faster than conditional loops.
On the downside, this code has several performance issues:
- Many data encodings can be efficiently read in bulk, but this code reads one value at a time.
- In some cases, the code can be called with different type instances, which result in slow dynamic dispatch call sites in the loop.
- Value reading in the null loop is conditional, which is expensive.
Optimize for bulk reads #
As you can see from the code above, Trino is always loading values in batches (typically 1024). This makes the reader and the downstream code more efficient as the overhead of processing data is amortized over the batch, and in some cases data can be processed in parallel. ORC has a small number of low level decoders for booleans, numbers, bytes and so on. These encodings are optimized for each data type, which means each must be optimized individually. In some cases, the decoders already had internal batch output buffers, so the optimization was trivial. In another equally trivial case, we changed the float and double stream decoders from loading a value byte at a time to bulk loading an entire array of values directly from the input and improved the performance more than 10x.
Some changes, however, were significantly more complex. One example is the boolean reader, which was changed from decoding a single bit at a time to decoding 8 bits at a time. This sounds simple, but in practice doing this efficiently is complex, since reads are not aligned to 8 bits, and there is the general problem of forming JVM friendly loops. For those interested, the code is here.
Avoid dynamic dispatch in loops #
This is the kind of problem that is not obvious when reading code, and it is
easily missed in benchmarks. The core problem happens when you have a loop
containing a method call whose target class can vary over the lifetime of the
execution. For example, this simple loop from above may or may not be fast,
depending on how many different classes it sees for type across multiple
executions:
for (int i = 0; i < nextBatchSize; i++) {
type.writeLong(builder, dataStream.next());
}
Most of the ORC column readers can only be called with a single type
implementation, but the LongStreamReader is called with BIGINT, INTEGER,
SMALLINT, TINYINT and DATE types. This causes the JVM to generate a dynamic
dispatch in the core of the loop. Besides the obvious extra work to select the
target code and branch prediction problems, dynamic dispatch calls are normally
not inlined, which disables many powerful optimizations in the JVM. The good news
is that the fix is trivial:
if (type instanceof BigintType) {
BlockBuilder builder = type.createBlockBuilder(null, nextBatchSize);
for (int i = 0; i < nextBatchSize; i++) {
type.writeLong(builder, dataStream.next());
}
return builder.build();
}
if (type instanceof IntegerType) {
BlockBuilder builder = type.createBlockBuilder(null, nextBatchSize);
for (int i = 0; i < nextBatchSize; i++) {
type.writeLong(builder, dataStream.next());
}
return builder.build();
}
...
The hard part is knowing that this is a problem. The existing benchmarks for ORC only tested a single type at a time, which allowed the JVM to inline the target method and produce much more optimal code. In this case, we happen to know that the code is being invoked with multiple types, so we updated the benchmark to warm up the JVM with multiple types before benchmarking.
For more information on this kind of optimization, I suggest reading Aleksey Shipilëv’s blog posts on JVM performance. Specifically, The Black Magic of (Java) Method Dispatch.
Improve null reading #
With the above improvements, we were getting great performance of 0.5ns to 3ns
per value for most types without nulls, but the benchmarks with nulls were taking
an additional ~6ns per value. Some of that is expected, since we must decode the
additional present boolean stream, but booleans decode at a rate of ~0.5ns per
value, so that isn’t the problem. Martin Traverso
and I built and benchmarked many different implementations, but we only found one
with really good performance.
The first implementation we built was simply to bulk read a null array, bulk read the values packed into the front of an array, and then spread the nulls across the array:
// bulk read and count null values
boolean[] isNull = new boolean[nextBatchSize];
int nullCount = presentStream.getUnsetBits(nextBatchSize, isNull);
// bulk read non-values into an array large enough for full results
long[] result = new long[nextBatchSize];
dataStream.next(longNonNullValueTemp, nextBatchSize - nullCount);
// copy non-null values into output position (in reverse order)
int nullSuppressedPosition = nextBatchSize - nullCount - 1;
for (int outputPosition = isNull.length - 1; outputPosition >= 0; outputPosition--) {
if (isNull[outputPosition]) {
result[outputPosition] = 0;
}
else {
result[outputPosition] = result[nullSuppressedPosition];
nullSuppressedPosition--;
}
}
This is better because it always bulk reads the values, but there is still a ~4ns
per value penalty for nulls. We haven’t been able to explain why it happens, but
we’ve observed that the number drops dramatically after we adjusted the code to
assign to result[outputPosition] outside the if block. We can’t do that
in-place, as in the snippet above, so we introduce a temporary buffer:
// bulk read and count null values
boolean[] isNull = new boolean[nextBatchSize];
int nullCount = presentStream.getUnsetBits(nextBatchSize, isNull);
// bulk read non-values into a temporary array
dataStream.next(tempBuffer, nextBatchSize - nullCount);
// copy values into result
long[] result = new long[isNull.length];
int position = 0;
for (int i = 0; i < isNull.length; i++) {
result[i] = tempBuffer[position];
if (!isNull[i]) {
position++;
}
}
With this change, the null penalty drops to ~1.5ns per value, which is reasonable given that just reading the null flag counts ~0.5ns per value. There are two downsides to this approach. Obviously, there is an extra temporary buffer, but since the reader is single threaded, we can reuse it for the whole file read. Secondly, the null values are no longer zero. This should not be a problem for correctly written code, but could potentially trigger latent bugs. We did find another approach that left the nulls unset, but it was a bit slower and required another temp buffer, so we settled on this approach.
How much will my setup improve? #
We tested the performance using the standard TPC-DS and TPC-H benchmarks on zlib compressed ORC files:
| Benchmark | Duration | CPU |
|---|---|---|
| TPC-DS | 5.6% | 9.3% |
| TPC-H | 4.5% | 8.3% |
There are a number of reasons you may get a larger or smaller win:
- The exact queries matter: In the benchmarks above, some queries saved more than 20% CPU and others only saved 1%.
- The compression matters: In our tests we used zlib, which is the most expensive compression supported by ORC. Compression algorithms that use less CPU (e.g., Zstd, LZ4, or Snappy) will generally see larger relative improvements.
- This improvement is only in Trino 309+, so if you are using an earlier version you will need to upgrade. Also, if you are still using Facebook’s version of Presto, you can either upgrade to Trino 309+ or wait to see if they backport it.