
Community, noun: “A feeling of fellowship with others, as a result of sharing common attributes, interests, and goals”
The fun picture you see here was taken at the first lecture of the First international Presto summit in Israel last month.
The atmosphere in the room during the various presentations was unique. It’s as if you could physically feel the brainpower of 250 engineers fascinated by technology in one room.
We would like to share with you a bit of the content that was discussed during the conference. Enjoy the read and the videos!
Presto Software Foundation presentation #

The day started with Dain Sundstrom, Martin Traverso, and David Phillips, Presto founders who gave us a great panoramic view on Presto Software Foundation, past, present, and future roadmap.
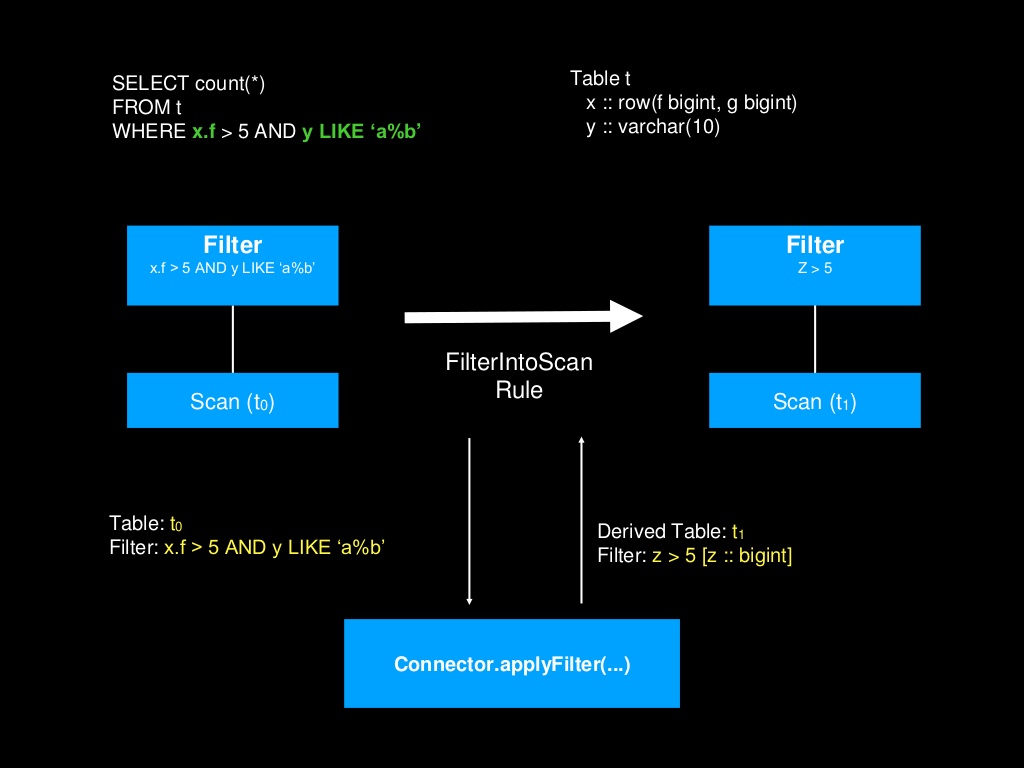
The Presto founders presented in their talk the following topics:
- Presto foundation creation
- ORC improvements
- The complex pushdown algorithm in details
- The opensource roadmap strategy and more
You can find the entire video of the presentation here and the slides here.
Varada presentation #
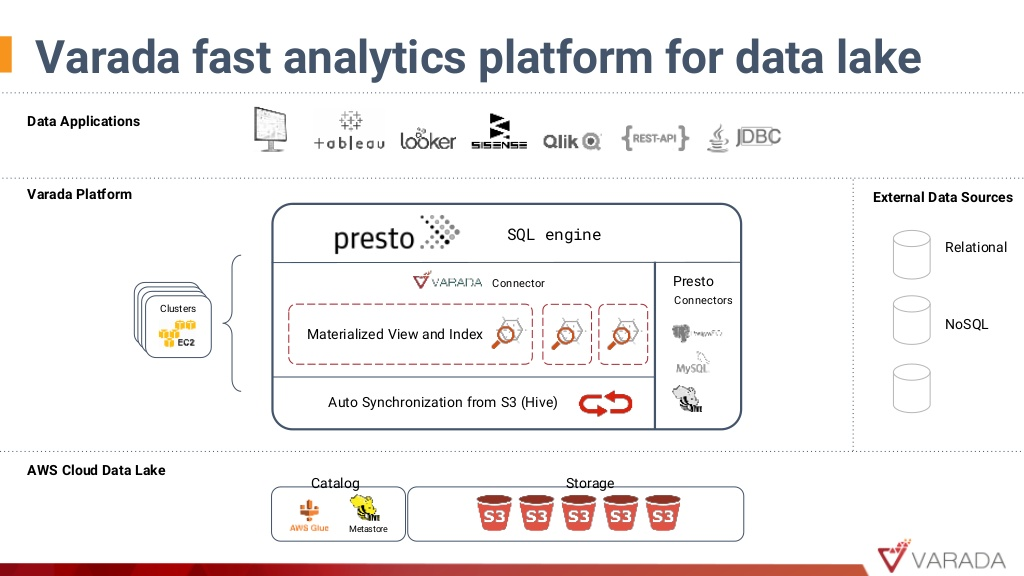
David Krakov, co-founder and CTO at Varada explained how Varada is an example of how Presto can be leveraged to create a new innovative technology that allows interactive analytics on top of a data lakes extracted sets, or in other words Presto for apps.
David presented the three axes of innovation that the Varada team created, to achieve an indexed big data on a distributed platform:
- SSD and NVMeF distributed calculation
- All dimensions are indexed in the ingest process
- Synchronization
- Fully automated copy management directly connected to the raw data in the data lake.
You can find the video of the presentation here and the slides here.
WiX open sourcing Quix #
The big announcement of the conference came from Valery Florov of Wix. As a web-scale data-driven company, with 150M users, Wix has more than 1000 users of Presto, and over 100K daily queries.
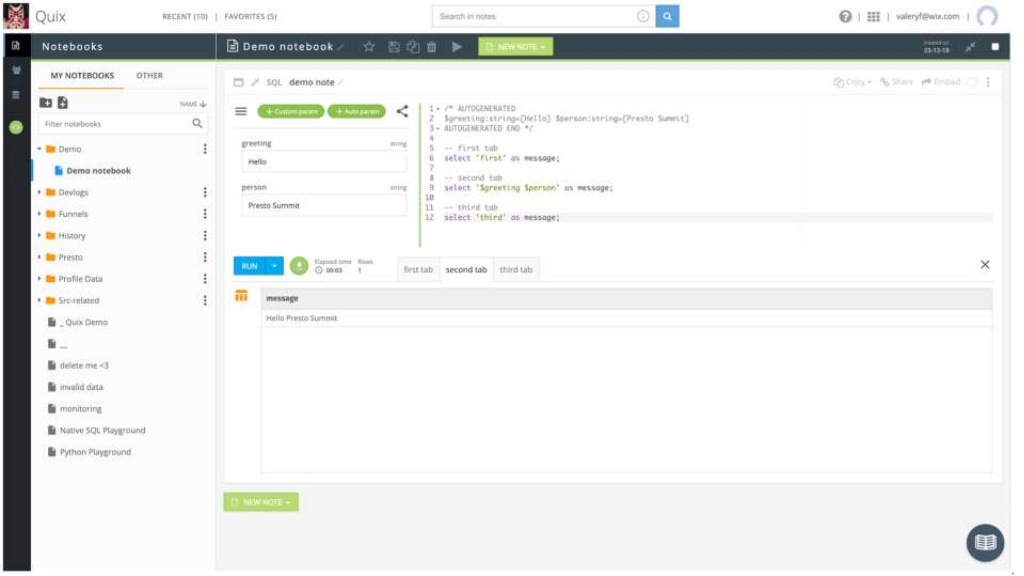
All those queries come through a unified front end for data discovery, transformation, and query: the Quix IDE. Quix is simultaneously: A notebook manager for users to write and share executable notes
- Dataset explorer showing catalogs and metadata
- Feature-rich SQL query editor
- Job scheduler for ETL jobs
- Wix has open-sourced most of Quix, available under an MIT license at https://github.com/wix-incubator/quix
As a Presto centric company Wix has developed few more exciting enhancements:
- HBase + Parquet interleaving to mix compacted historic data and latest 14 days
- One SQL - a query rewriter that unifies usage of Presto and BigQuery to one SQL
- ActiveDirectory data security layer to control access to data
- Google Drive integration - run Presto SQL directly on Google Sheets. This is one of the coolest connectors to be created and generated a lot of excitement. Can’t wait for Wix to open source this one as well!
See more in the video, slides, source code.
Ironsource - Analyzing data at a petabyte scale. #
Ironsource is the ad network of choice for the gaming industry. Supplying solutions for application developers, customer engagement solutions and Ad monetization. Ironsource collects terabytes of events on a daily basis.
In his talk, Or Koren, head of the data team at Ironsource, shared their journey from terabyte scale to petabyte scale. In his talk Or showed how their entire interactive analytics platform was rebuilt to be based on Presto, and the huge savings they got from it including new business insights coming from their data science teams and the data analyst team.
 |
 |
The before and after slides that Or presented in a very clear way the reduction in cost and the increase in efficiency that the use of Presto brought to Ironsource.
See Or’s slides here and the talk video.
Datorama on mutable data at scale #
A charismatic presenter, Alexey Finkelstein from Salesforce Datorama had the room rolling with laughter more than once, and on a topic of no laughter: managing mutable data with Presto. Datorama provides a marketing intelligence platform. It has 30,000 customers, who can interactively interact with 1.5PB of data available for interactive queries.
Datorama provides for that a “data lake as a service”, called a DatoLake. Files on data lakes by their nature are not transactionally updatable on a row level, but the users of Datorama require the ability to delete/update specific rows in a transactional manner.

To solve this Datorma has embarked on a journey. Based on partitioning the data by a version number (such as 20190101_009), and rebuilding a partition based on updates. There were 3 attempts to the journey and learning on each step:
- At first, using an external Postgres metastore to store the versions, swapping in the metastore and using that as part of a sub-query to Presto to use the correct version. This approach did not pushdown partition pruning.
- Next, moving the metastore query to happen before query generation, and be dynamically generate the right filter at each sub-query. This approach required two-pass processing for each query and did not support direct SQL to clients.
- And finally, swapping the partition in the Hive Metastore in a transactional manner directly in the Hive Metastore database (MySQL), and refresh the Presto hive cache. With this approach, queries do not need to know about the version change and full separation of the mutability logic from the query is achieved.
See much more details in the video, slides.
Varada, Join Optimization and Dynamic filtering #
Roman Zeyde is Varada’s Presto architect. Roman has a unique algorithmic background being a Talpiot graduate and an ex-Googler.
Roman’s talk discussed a new approach to make Joins work faster. Varada will contribute Roman’s work on dynamic filtering back to the community. Stay tuned :)
The talk went over the following major topics:
- Presto Cost Based Optimizer feature as a basis for Join optimization
- Join optimzation strategies
- Dynamic filtering in the application for join optimization

Q&A session #
The event finished by an hour-long Q&A session led by Demi Ben-Ari, VP R&S at Panorays and co-founder of Big Things, an Israeli Meetup group having 5000 people listed, all fans of Big data technologies.

See you all in the Second international Presto Conference in Tel Aviv!