Queries involving IN and NOT IN over a subquery are much faster in
Presto 312.
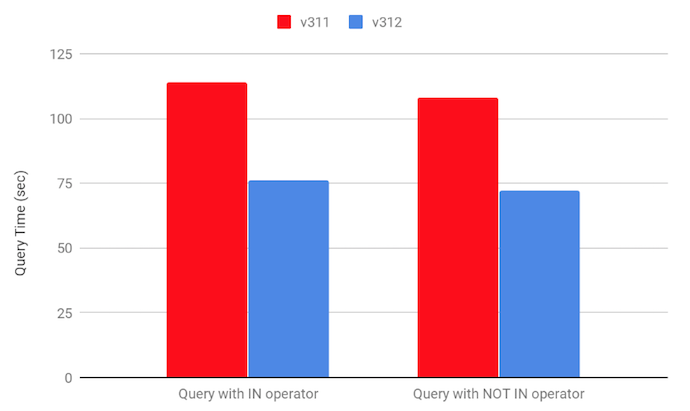
We ran the benchmark above with 3 workers (r3.2xlarge) and 1 coordinator (r3.xlarge) on TPC-DS scale 1000 stored in ORC format using the following queries:
SELECT count(*)
FROM store_sales
WHERE store_sales.ss_customer_sk IN (
SELECT c_customer_sk FROM customer
)
SELECT count(*)
FROM store_sales
WHERE store_sales.ss_store_sk NOT IN (
SELECT s_store_sk
FROM store
WHERE s_hours <> '8AM-4PM'
)
What was the improvement? #
We found that the optimization to use precomputed hashes, which is enabled by
default, was missing in SemiJoin operator. Hash values were precomputed at the leaf
stages but they were not being used in the SemiJoin operator leading to re-calculation
of the hash values at this operator. Since queries involving IN and NOT IN over a
subquery use SemiJoin operator, the fix to use precomputed hash in SemiJoin operator
improves the performance of such queries significantly.
How does optimize-hash-generation optimization work #
Presto divides a query plan into parts called Stages which can be run in parallel on multiple nodes, each node working on different set of data. There are two types of stages:
- Leaf Stages: these are the stages that are at the leaf of the Query Plan and read data from a datasource, like a Hive Table.
- Intermediate Stages: these are the stages other than the leaf stages and process data from other upstream stages.
The Exchange operator shuffles and transfers the output from upstream stages to the
intermediate stages. For certain operators like GROUP BY and JOIN, output data of
the leaf stage is partitioned by the values of a column and the shuffle operation ensures
that a particular partition is always processed by the same task of the Intermediate stage.
This partitioning requires calculation of a hash on that column’s values during exchange
and later in the intermediate stage same hash is needed during the execution of GROUP BY
or JOIN operation. To prevent redundant calculations, Presto calculates this hash value
in the leaf stage, uses it in Exchange operator and makes it available in the output to let
GROUP BY or JOIN operations use it in the intermediate stage.
Consider this query to count the number of stores per city:
SELECT count(*), city
FROM stores
GROUP BY city
The query plan (simplified) and its division into stages looks like below:
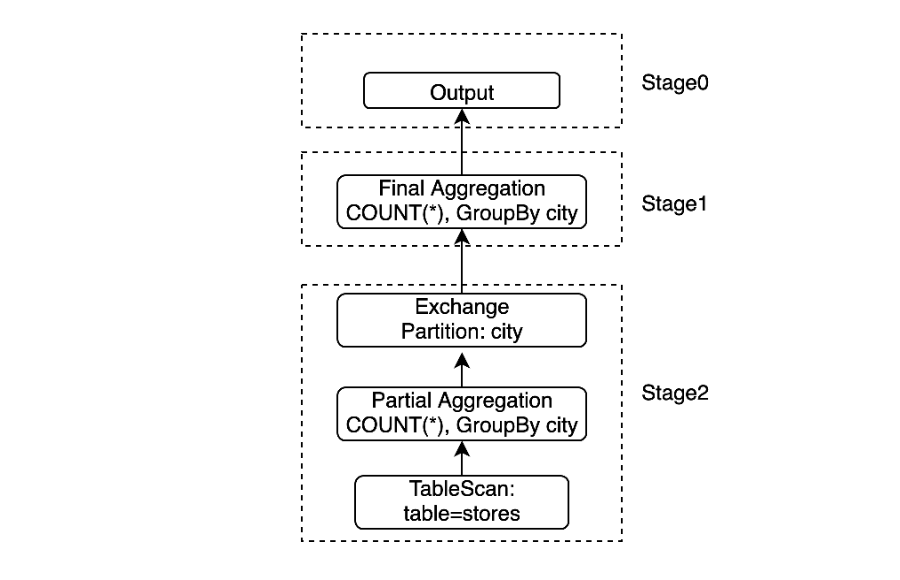
The leaf stage (Stage2) reads the table from a data source, feeds the partially
aggregated data to Stage1 where final aggregation happens, and finally, the result is available
via Stage0.
Each row produced by Stage2, needs to be partitioned by the value of city column in it to ensure
data for same city is processed by the same task of Stage1. After the exchange, when a row is consumed
in Stage1, it needs to be hashed again to find a group for the row so that the final aggregation
accumulates results for each city in it’s corresponding group bucket. Double hash calculations on
the values of city column is prevented by doing this calculation once while reading the data and then
using it in both Exchange and Final Aggregation operations which reduces CPU usage of the query.
Additionally, pushing this calculation into leaf stage which is better parallelized when there is
a large number of splits for this stage, improves query latency.
How to get this fix? #
This fix is available in Presto version 312 and above. The optimize-hash-generation setting is enabled
by default so the fix will be in action as soon as you upgrade your Presto installation.