Optimizers are all about doing work in the most cost-effective manner and avoiding unnecessary work.
Some SQL constructs such as ORDER BY do not affect query results in many situations, and can negatively
affect performance unless the optimizer is smart enough to remove them.
Until very recently, Presto would insert a sorting step for each ORDER BY clause in a query. This, combined
with users and tools inadvertently using ORDER BY in places that have no effect, could result in severe
performance degradation and waste of resources. We finally fixed this in
Presto 312!
Quoting from the SQL specification (ISO 9075 Part 2):
A
<query expression>can contain an optional<order by clause>. The ordering of the rows of the table specified by the<query expression>is guaranteed only for the<query expression>that immediately contains the<order by clause>.
This means, a query engine is free to ignore any ORDER BY clause that doesn’t fit that context. Let’s consider
some examples where the clause is irrelevant.
INSERT INTO some_table
SELECT * FROM another_table
ORDER BY field
While this query has the semblance of creating a sorted table, that’s not so. Tables in SQL are inherently
unordered. Once the data is written, there’s no guarantee it will come out sorted when read. This is
particularly true for a parallel, distributed query engine like Presto that reads and processes data using
many threads simultaneously. Note that some storage engines may store data sorted, but that is not controlled
during data insertion. Executing the ORDER BY just causes the query to perform poorly due to reduced
parallelism in the merging step of a distributed sort, and consumes more CPU and memory to sort the data.
SELECT *
FROM some_table
JOIN (SELECT * FROM another_table ORDER BY field) u
ON some_table.key = u.key
In this case, whether the tables involved in the join are sorted doesn’t matter, since Presto is going to
build a hash lookup table out of one of them to execute the join operation. As in the previous example
preserving the ORDER BY just causes the query to perform poorly.
When does ORDER BY matter? Since it is “guaranteed only for the <query expression> that immediately
contains the <order by clause>”, only operations that are part of the same <query expression> are
sensitive to it.
A query expression is a block with the following structure:
<query expression> ::=
[ <with clause> ]
<query expression body>
[ <order by clause> ]
[ <result offset clause> ]
[ <fetch first clause> ]
where <query expression body> devolves into one of the set operations (UNION, INTERSECT, EXCEPT),
a SELECT construct, VALUES or TABLE clause.
The only operations that occur after an ORDER BY are FETCH FIRST (a.k.a., LIMIT) and OFFSET. So,
unless a subquery contains one of these two clauses, the query engine is free to remove the ORDER BY
clause without breaking the semantics dictated by the specification.
Here’s an example where the clause is meaningful:
SELECT *
FROM some_table
WHERE field = (
SELECT a
FROM another_table
ORDER BY b
LIMIT 1)
Other databases tackle this in a variety of ways. MariaDB
and Hive 3.0
will ignore redundant ORDER BY clauses. SQL Server, on the other hand, will produce an error:
The ORDER BY clause is invalid in views, inline functions, derived tables, subqueries, and common table expressions, unless TOP or FOR XML is also specified.
What’s the catch? #
It is a common mistake for users to think the ORDER BY clause has a meaning in the language regardless of where it
appears in a query. The fact that, for implementation reasons, in some cases ORDER BY is significant for Presto
complicates matters. We often see users rely on this when formulating queries where aggregation or window functions
are sensitive to the order of their inputs:
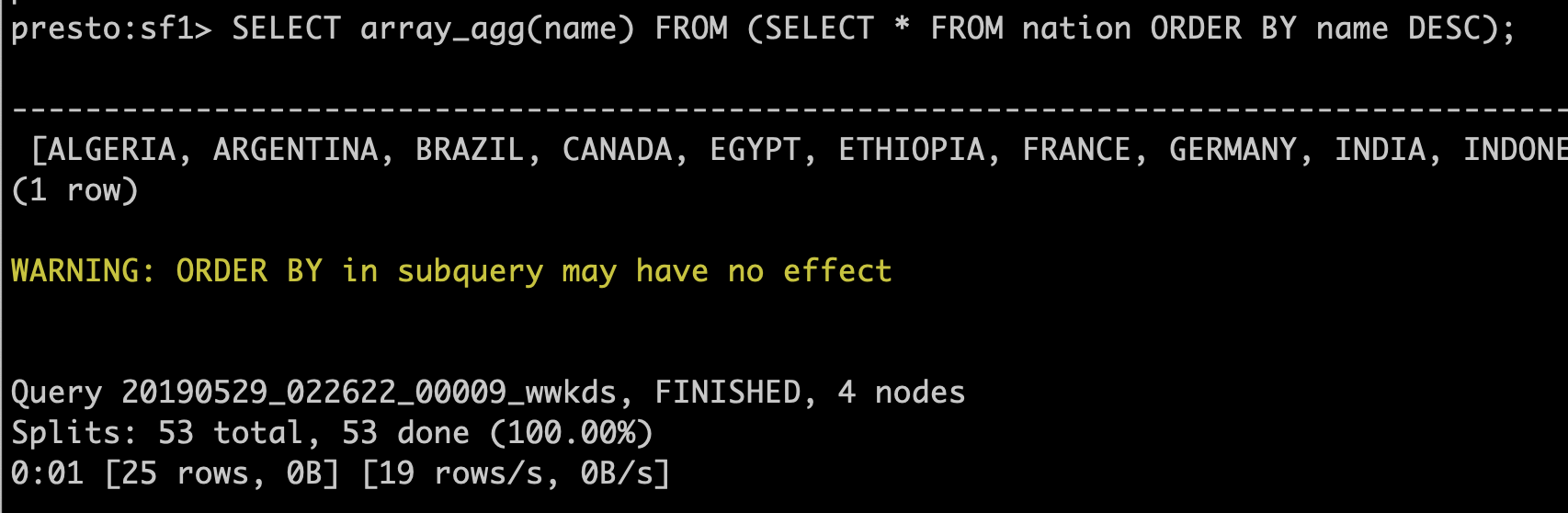
SELECT array_agg(name) FROM (
SELECT *
FROM nation
ORDER BY name DESC
)
SELECT *, row_number() OVER ()
FROM (
SELECT *
FROM nation
ORDER BY name DESC
)
The Right Way™ of doing this in SQL is to use the aggregation or window-specific ORDER BY clause. For the
examples above:
SELECT array_agg(name ORDER BY name DESC)
FROM nation
SELECT *, row_number() OVER (ORDER BY name DESC)
FROM nation
In order to ease the transition, the new behavior can be turned off globally via the optimizer.skip-redundant-sort
configuration option or on a per-session basis via the skip_redundant_sort session property.
These options will be removed in a future version.
Additionally, any time Presto detects a redundant ORDER BY clause, it will warn users about it: