Hive ACID and transactional tables are supported in Presto since the 331 release. Hive ACID support is an important step towards GDPR/CCPA compliance, and also towards Hive 3 support as certain distributions of Hive 3 create transactional tables by default.
In this blog post we cover the concepts of Hive ACID and transactional tables along with the changes done in Presto to support them. We also cover the performance tests on this integration and look at the future plans for this feature.
How to use Hive ACID and transactional tables in Presto #
Hive transactional tables are readable in Presto without any need to tweak configs, you only need to take care of these requirements:
- Use Presto version 331 or higher
- Use Hive 3 Metastore Server. Presto does not support Hive transactional tables created with Hive before version 3.
Note that Presto cannot create or write to Hive transactional tables yet. You can create and write to Hive transactional tables via Hive or via Spark with Hive ACID Data Source plugin and use Presto to read these tables.
What is Hive ACID and Hive transactional tables #
Hive transactional tables are the tables in Hive that provide ACID semantics. This excerpt from Hive documentation covers ACID traits well:
“ACID stands for four traits of database transactions: Atomicity (an operation either succeeds completely or fails, it does not leave partial data), Consistency (once an application performs an operation the results of that operation are visible to it in every subsequent operation), Isolation (an incomplete operation by one user does not cause unexpected side effects for other users), and Durability (once an operation is complete it will be preserved even in the face of machine or system failure). These traits have long been expected of database systems as part of their transaction functionality.“
Need for Hive ACID and transactional tables #
In any organisation, there is always a need to update or delete existing entries in tables e.g., a user writes or updates the review for an item purchased a week back or a transaction status is changed after a day, etc.. With regulations like GDPR/CCPA updates/deletes become even more frequent as the users can ask the organisation to delete the data on them, and organisations are obligated to fulfill these requests.
The standard practice to update data has been to overwrite the partition or table with the updated data but this is inefficient and unreliable. It takes a lot of resources to overwrite all of the existing data to update a few entries, but more importantly there are issues around isolation when reads on old data are going on and the overwrite starts deleting that data. To solve these issues several solutions have been developed, many of them are covered in this blog post, and Hive ACID is one of them.
Concepts of Hive ACID and transactional tables #
Several concepts like transactions, WriteIds, deltas, locks, etc. are added in Hive to achieve ACID semantics. To understand the changes done in Presto to support Hive ACID and transactional tables, covered in the next section, it is important to understand these concepts first. So let’s look at them in detail.
Types of Hive transactional tables #
There are two types of Hive transactional tables: Insert-Only transactional tables and CRUD transactional tables. Following table compares the two:
| Type of transactional table | Hive DML Operations Supported | Input Formats supported | Synthetic columns in file? | Additional Table Properties |
|---|---|---|---|---|
| Insert-Only Transactional Tables | INSERT | All input formats | No | 'transactional'='true', 'transactional_properties'='insert_only' |
| CRUD Transactional Tables | INSERT, UPDATE, DELETE | ORC | Yes | 'transactional'='true' |
Hive Transactions #
Hive transactional tables should be accessed under Hive Transactions only. Note that these transactions are different from Presto transactions and are managed by Hive. Running DML queries under separate transactions helps in atomicity. Each transaction is independent and when rolled back will not have any impact on the state of the table.
WriteIds #
DML queries under a transaction write to a unique location under partition/table described in detail later in “New Sub-Directories” section. This location is derived by WriteId allocated to the transaction. This provides Isolation of DML queries and such queries can run in parallel, whenever they can, without interfering with each other.
Valid WriteIds #
Read queries under a transaction get a list of valid WriteIds that belong to the transactions which were successfully committed. This ensures Consistency by making results of committed transactions available to all the future transactions and also provides Isolation as DML and read queries can run in parallel with read queries not reading partial data written by DML queries.
New Sub-Directories #
Results of a DML queries are written to a unique location derived from WriteId of the transaction. These unique locations are delta directories under partition/table location. Apart from the WriteId, this unique location is made up of the DML operation and depending on the operation type there can be two types of delta directories:
- Delete Delta Directory: This delta directory is created for results of
DELETE statements and is named
delete_delta_<writeId>_<writeId>under partition/table location. - Delta Directory: This type is created for the results of INSERT statements
and is named
delta_<writeId>_<writeId>under partition/table location.
Apart from delta directories, there is another sub-directory that is now added
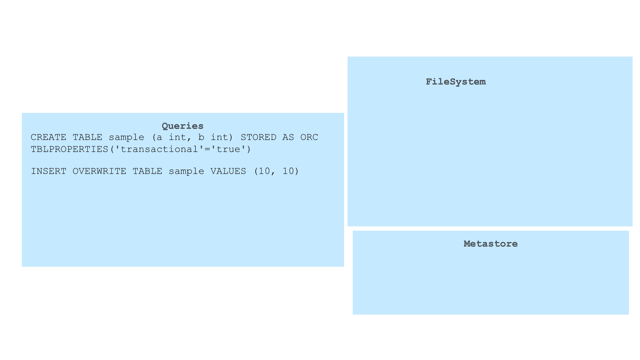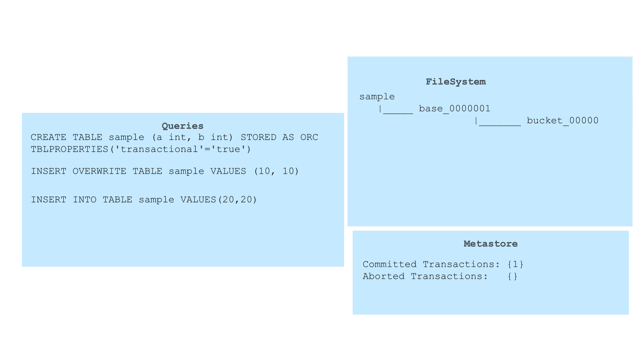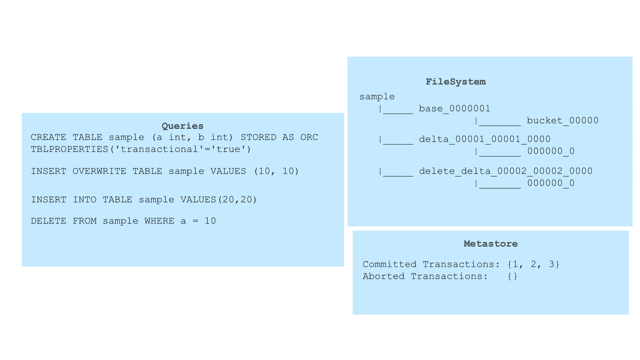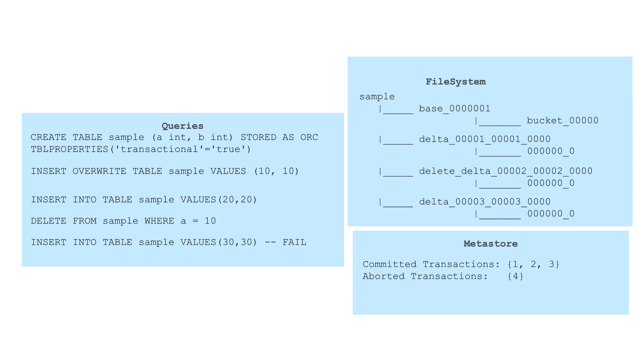
called “Base directory” and is named as base_<writeId> under partition/table
location. This type of directory is created by INSERT OVERWRITE TABLE query or
by major compaction which is described later.
The following animation shows how these new sub-directories are created in the
filesystem along with transaction management at metastore with different
queries:
RowID #
To uniquely identify each row in the table, a synthetic rowId is created and
added to each row. RowIds are added to CRUD transactional tables only because it
is used in case of DELETE statements only. When a DELETE is performed, the
rowIds of the rows that it would delete are written into the delete_delta
directory and subsequents reads will read all but these rows.
RowId is made of 5 entries today: operation, originalTransaction, bucket,
rowId, currentTransaction but operation and currentTransaction fields
are redundant now.
RowId is added in the root STRUCT of ORC and hence the schema of ORC files is
different from the schema defined in the table, e.g.:
Schema of CRUD transactional Hive Table:
n_nationkey : int,
n_name : string,
n_regionkey : int,
n_comment : string
Schema of ORC file for this table:
struct {
operation : int,
originalTransaction : bigint,
bucket : int,
rowId : bigint,
currentTransaction : bigint,
row : struct {
n_nationkey : int,
n_name : string,
n_regionkey : int,
n_comment : string
}
}
Note that one level of nesting of table schema, like the inner struct above, is applicable to flat Hive tables too. The two level nesting of data columns is added for Orc files of CRUD transactional tables to keep rowId columns isolated from data columns.
Compactions #
The working described above with delta and delete_delta directories for each
transaction makes the DML queries execute fast but have
the following impact on read queries:
- Many delta directories with small data in each directory will slow down execution of read queries. This is a known problem around small files where engines end up spending more time opening files than actually processing the data.
- Cross referencing all
delete_deltadirectories to remove all deleted rows slows down the reads.
To solve these problems, Hive compacts delta directories asynchronously at two levels:
- Minor Compaction: This compaction combines active
deltadirectories into onedeltadirectory and activedelete_deltadirectories into onedelete_deltadirectory thereby decreasing the number of small files. Limiting scope of this compaction to combining onlydeltadirectories keeps it fast. Minor compaction is automatically triggered as soon as active delta directories count reaches 10 (configurable). This compaction creates new delta directories likedelta_<start_write_id>_<end_write_id>where [start_write_id, end_write_id] gives the range of existing delta directories that we compacted. Similar naming convention is used fordelete_deltadirectory. - Major Compaction: Minor compaction does not work on merging base,
deltaanddelete_deltadirectories as that requires rewriting of data with only the non-deleted rows, hence time consuming. This work is handled by a separate, less frequent and longer running, compaction called Major compaction. Major compaction is triggered when the total size of delta directories reaches 10% (configurable) of the base directory size. This compaction creates a new Base directory.
Locks #
Hive uses shared locks to control what operations can run in parallel on partition/table. For example, DML queries take a write-lock on partitions they are modifying while read queries take a read-lock on partitions they are reading. The read-locks taken by read queries prevents Hive from cleaning up the delta directories that have been compacted while they are being read by the query.
Changes in Presto to support Hive ACID and transactional ables #
At high level, there are changes at two places in Presto to support Hive ACID and transactional tables: In split generation logic that runs in coordinator and in ORC reader that is used in workers.
Split generation #
- Hive ACID State is setup in
SemiTransactionalHiveMetastore.beginQuery, only for Hive transactional tables:- A new Hive transaction is opened per Query
- A shared read-lock is obtained from Metastore server for the partitions read in the query
- A Heartbeat mechanism is set up to inform the Metastore server about
liveliness periodically. Frequency of heartbeats is figured out from the
Metastore server but can be overridden with
hive.transaction-heartbeat-intervalproperty.
BackgroundSplitLoaderis set up with valid WriteIds for the partitions as provided by Metastore serverBackgroundSplitLoader.loadPartitionsis called in an Executor to create splits for each partition:- ACID sub-directories:
base,deltaanddelete_deltadirectories are figured out by listing the partition location DeleteDeltaLocations, a registry ofdelete_deltadirectories, is created. It contains minimal information through whichdelete_deltadirectory paths can be recreated at workers.- HiveSplits are created with each location of base and delta directories.
Each HiveSplit contains the
DeleteDeltaLocations - If the table is Insert-Only transactional table then
DeleteDeltaLocationsis empty and the HiveSplit is same as the HiveSplit on flat/non-transactional Hive table
- ACID sub-directories:
Reading Hive transactional data in workers #
The HiveSplit generated during the split generation phase make their way to worker nodes where OrcPageSourceFactory is used to create PageSource for TableScan operator.
- Insert-Only transactional tables are read in the same way a non-transactional
tables are read,
OrcPageSourceis created for their splits which reads the data for the split and makes it available to TableScanOperator - CRUD transactional tables need special handling during reads because the file
schema does not match the table for them due to the synthetic RowId column added
which introduces additional Struct nesting as mentioned earlier:
- RowId columns are added to the list of columns to be read from file
- ORC reader is setup by accessing column name from the file instead of
using the column indexes from table schema, equivalent to forcing
hive.orc.use-column-names=truefor CRUD transactional tables OrcRecordReaderis created for the ORC file of the splitOrcDeletedRowsis created fordelete_deltalocations, if any.OrcPageSouceis created that returns rows fromOrcRecordReaderwhich are not present inOrcDeletedRows. This cross referencing of deleted rows is done lazily for eachBlockof thePageonly when thatBlockis needed to be read from the PageSource. This works well with the lazy materialization logic of Presto to skip over Blocks if a predicate does not apply to thePageat all.
Performance numbers #
Each Insert on Hive transactional table can create additional splits for delta
directories and each delete can create delete_delta directories that adds
additional work of cross referencing deleted rows while reading the split. To
measure the impact of these operations on reads from Presto we ran the following
performance tests where multiple Hive transactional tables are created with
varying number of Insert and Delete operations and runtime of different
read-focused Presto queries were recorded:
| Table Type | Description | delta directories | delete_delta directories |
|---|---|---|---|
| Flat | TPCDS store_sales scale 3000 table, 8.6B rows | 0 | 0 |
| Only Base | Hive transactional store_sales scale 3000 table: 8.6B rows | 0 | 0 |
| Base + 1-Delete | Derived from “Only Base” with rows having customer_id=100 deleted by 1 DELETE query: 347 deleted entries | 0 | 1 |
| Base + 1-Delete + 1-Insert | Derived from “Base + 1 Delete” with deleted rows added back by 1 INSERT query: 347 deleted entries + 347 inserted entries | 1 | 1 |
| Base + 5-Deletes | Derived from “Only Base” with rows for 5 customer_ids deleted by 5 DELETE queries: 1355 rows deleted | 0 | 5 |
| Base + 5-Deletes + 5-Inserts | Derived from “Base + 1 Delete” with deleted rows added back by 5 INSERT queries: 1355 deleted entries + 1355 inserted entries | 5 | 5 |
Following is the result of these tests, ran on a cluster with 5 c3.4xlarge
machines on AWS:
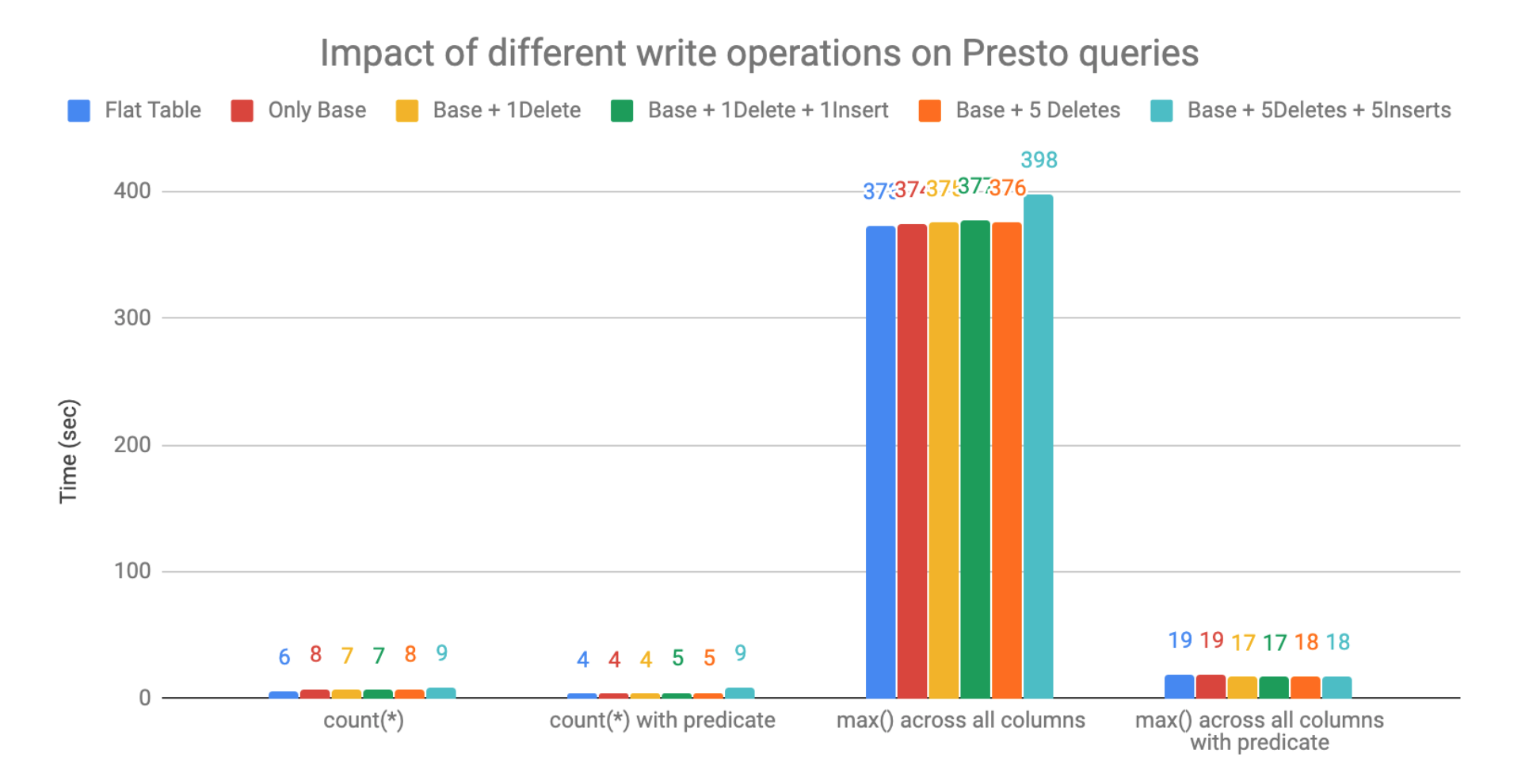
It was seen that there is an impact of deleted rows on read performance, which is expected as the work for the reader increases in this case. But with predicates in place, this impact was reduced as the amount of data to be read goes down.
Ongoing and Future work #
There has been ongoing work on the Hive ACID integration and some improvements are planned in future, notably:
- Bucketed Hive transactional table support has been added (#1591)
- Support for original files is in progress (#2930), this will allow Presto to read the Hive tables that were converted to transactional table at some point after having non-transactional data
- Write support will be taken up in future (#1956)
- There is ongoing work on Hive side for ACID on Parquet format. Once that lands, Presto’s implementation will be extended to support Parquet too.
Acknowledgements and Conclusion #
Thanks to the folks who helped out in the development of this feature: Abhishek Somani provided continuous guidance on internals of Hive ACID, Dain helped out with simplifying ORC reader and along with Piotr helped in code refinement and with multiple rounds of reviews.
While we continue development on this feature to get full fledged support including writes, you can start using it on Hive transactional tables which do not have files in flat format. If you have such tables and want to use Presto with them then you can apply this fix to your Presto installation or you can trigger a major compaction on all partitions to migrate full table into CRUD transactional table format.