Presto 334 adds significant performance improvements for queries accessing nested fields inside struct columns. They have been optimized through the pushdown of dereference expressions. With this feature, the query execution prunes structural data eagerly, extracting the necessary fields.
Motivation #
RowType is a built-in data type of Presto, storing the in-memory
representation of commonly used nested data types of the connectors, eg.
STRUCT type in Hive. Datasets often contain wide and deeply nested structural
columns, i.e. a struct column having hundreds of fields, with the fields being
nested themselves.
Although such RowType columns can contain plenty of data, most of the
analytical queries access just a few fields out of it. Without dereference
pushdown, Presto scans the whole column, and shuffles all that data around
before projecting the necessary fields. This suboptimal execution causes higher
CPU usage, higher memory usage and higher query latencies, than required. The
unnecessary operations get even more expensive with wider/deeper structs and
more complex query plans.
LinkedIn’s data ecosystem makes heavy usage of nested columns. It is common to have 2-3 levels of nesting, and up to 50 fields in most of our tracking tables. Because of the query execution inefficiency for nested fields, ETL pipelines were set up at LinkedIn to copy the nested columns as a set of top-level columns corresponding to subfields. This step added overhead in our ingestion process and delayed data availability for analytics. It also caused ORC schemas to be inconsistent with the rest of the infrastructure, making it harder to migrate from existing flows on row-oriented formats.
Similarly, Lyft’s schemas make heavy use of nested data to decompose a ride into its routes, riders, segments, modes, and geo-coordinates. Prior to the performance improvements, analytical queries would either need to be run on clusters with very long timeouts, or the data would have to be flattened before being analyzed, adding an extra ETL step. Not only would this be costly, it would also cause the original schema to diverge in our data warehouse making it more difficult for data scientists to understand.
The dereference pushdown optimization in Presto is having a massive impact on the ingestion story at both LinkedIn and Lyft. Nested data is now being made available faster for consumption with a consistency of structure across all stores, while maintaining performance parity for analytical queries.
Example #
Say we have a Hive table jobs, with a struct-typed column job_info in the
schema. The column job_info is wide and deeply nested, i.e. ROW(company
varchar, requirements ROW(skills array(...), education ROW(...), salary ...) ,
...). Most queries would access a small percentage of data from this struct
using the dereference projection (the . operation). Consider such a query Q
below.
SELECT A.appid id, J.job_info.company c
FROM applications A JOIN jobs J
ON A.jobid = J.jobid
LIMIT 100
It should suffice to scan only one field company from J.job_info for
executing this query. But, without dereference pushdown, Presto scans and
shuffles everything from job_info, only to project a single field at the end.
Solution: Pushdown of Dereference Expressions #
With dereference pushdown, Presto optimizes queries by extracting the sufficient
fields from a ROW as early as possible. This is enforced by modifying the
query plan through a set of optimizers, and can be broadly divided into two
parts.
First, dereference projections are extracted in the query plan and pushed as close to the table scan as possible. This happens independent of what the connector is. Secondly, there is a further improvement for Hive tables. The Hive Connector and ORC/Parquet readers have been optimized to scan only the sufficient subfield columns.
Pushdown of predicates on the subfields is also a crucial optimization. For
example, if a query has filters on subfields (i.e. a.b > 5), they should be
utilized by ORC/Parquet readers while scanning files. The pushdown helps with
the pruning of files, stripes and row-groups based on column-level statistics.
This optimization is achieved as a byproduct of the above two optimizations.
With the dereference pushdown, queries observe significant performance gains in terms of CPU/memory usage and query runtime, roughly proportional to the relative size of nested columns compared to the accessed fields.
Pushdown in Query Plan #
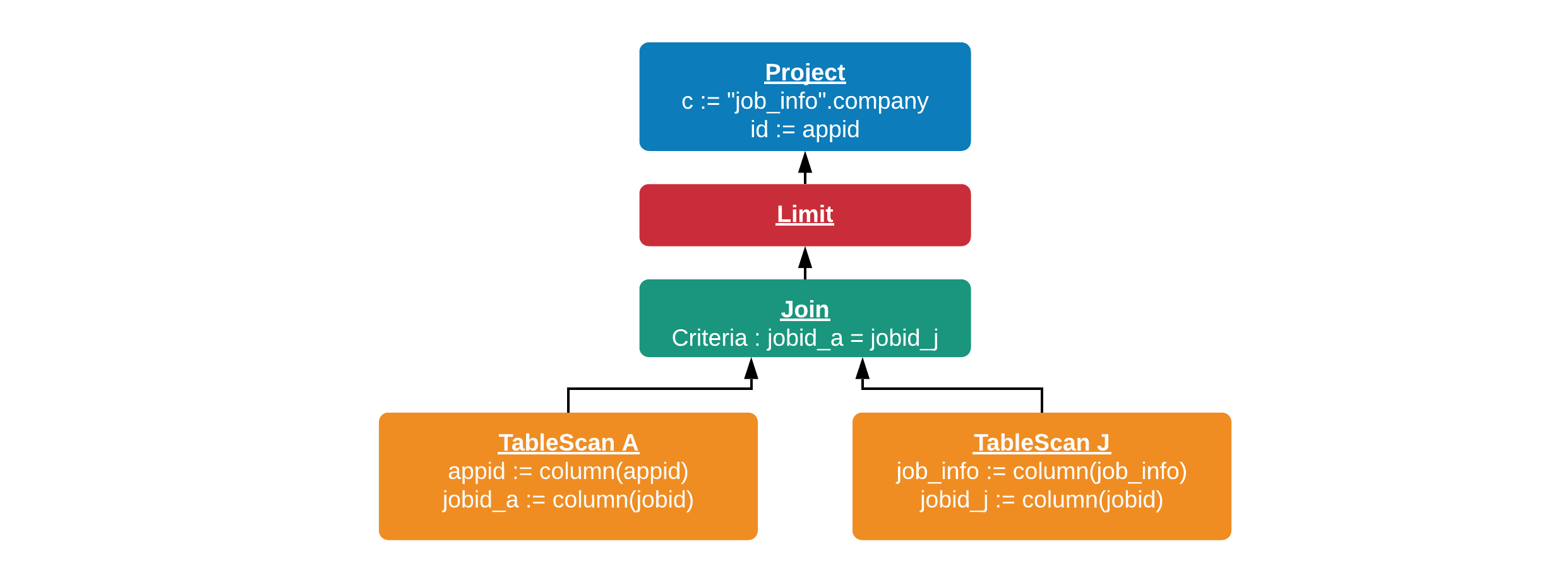
The goal here is to execute dereference projections as early as possible. This usually means performing them right after the table scans.
A projection operation that performs dereferencing on input symbols (i.e.
job_info.company) reduces the amount of data going up the plan tree. Pushing
dereference projections down means that we are pruning data early. It reduces
the amount of data being processed and shuffled in query execution. For the
example query Q, the query plan looks like the following when dereference
pushdown is enabled.
![]()
The projection job_info.company now directly follows the scan of jobs table,
avoiding the propagation the job_info through Limit and Join nodes. Note
that all of job_info is still being scanned, and pruning it in the reader
requires connector-dependent optimizations.
Pushdown in the Hive Connector #
In columnar formats like ORC and Parquet, the data is laid out in a columnar
fashion even for subfields. If we have a column STRUCT(f1, f2, f3), the
subfields f1, f2 and f3 are stored as independent columns. An optimized
query engine should only scan the required fields through its ORC reader,
skipping the rest. This optimization has been added for Hive connector.
Dereference projections above a TableScanNode are pushed down in the Hive
connector as “virtual” (or “projected”) columns. The query plan is modified to
refer to these new columns. For the query Q, jobs table would be scanned
differently with this optimization, as shown below. The projection is now
embedded in the Hive connector. Here, job_info#company can be thought of as
a virtual column representing the subfield job_info.company.
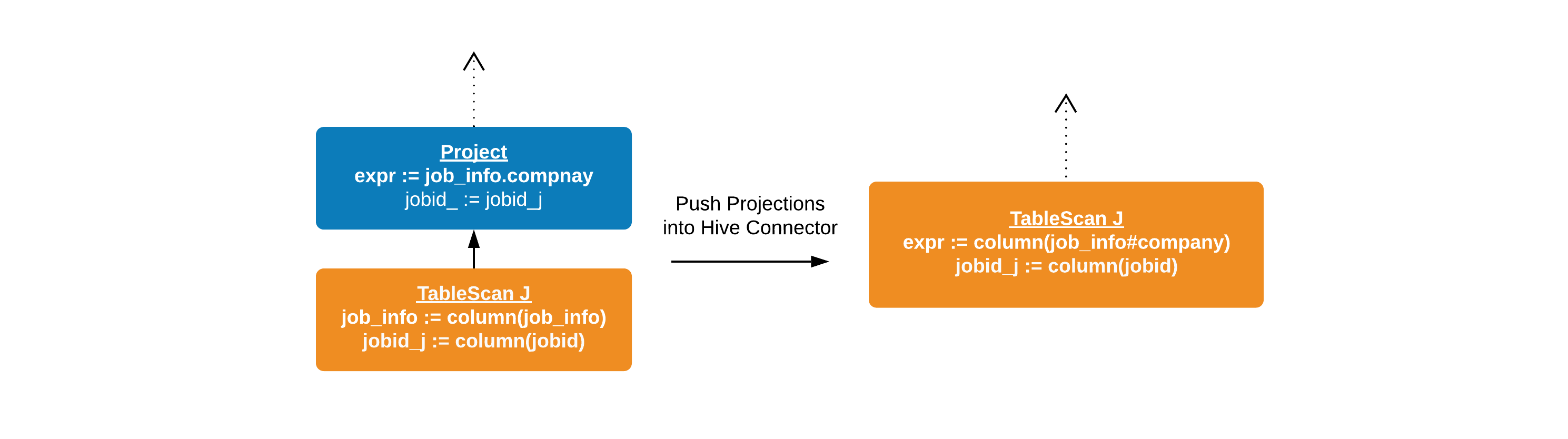
The Hive connector handles the projections before returning columns to Presto’s engine. It provides the required virtual columns to format-specific readers. ORC and Parquet readers optimize their scans based on subfields required, increasing their read throughput. Subfield pruning is not possible for row-oriented format readers (e.g. AVRO). For them, Hive connector performs adaptation to project the required fields.
Pushdown of Predicates on Subfields #
Columnar formats store per-column statistics in the data files, which can be
used by the readers for filtering. eg. if a query contains filter y = 5 for a
top-level column y, Presto’s ORC reader can skip ORC stripes and files by
looking at the upper and lower bounds for y in the statistics.
The same concept of predicate-based pruning can work for filters involving
subfields, since the statistics are also stored for subfield columns. i.e.
Presto’s ORC/Parquet reader should be able to filter based on a constraint like
x.f1 = 5 for more optimal scans. Good news! In the final optimized plan,
predicates on a subfield are pushed down to the hive connector as a constraint
on the corresponding virtual column, and later used for optimizing the scan.
The complete logic is a bit complicated to explain here, but can be illustrated
through the following example.
Given an initial plan with a predicate on a dereferenced field (x.f1 = 5), a
chain of optimizers transform it to a more optimal plan with reader-level
predicates. In the future, the same optimization will be added to the Parquet
reader.
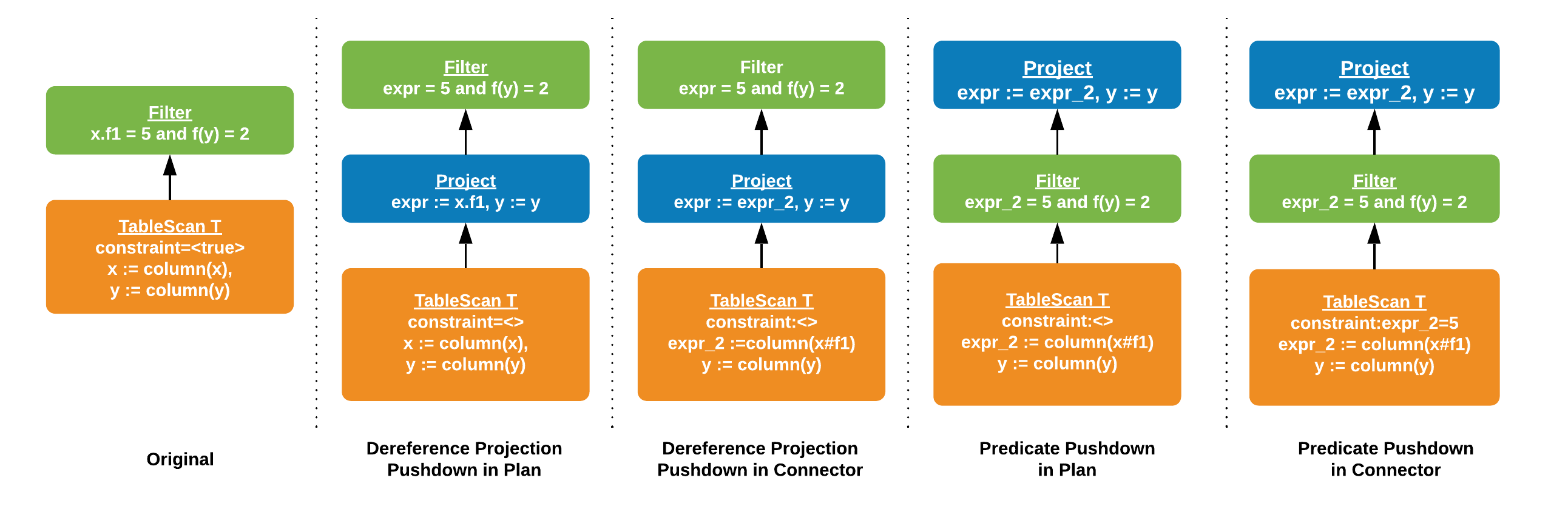
In the final plan, Hive connector knows to scan the column y and the subfield
x.f1. It also takes advantage of the “virtual” column constraint x#f1 = 5
for reader-level pruning.
Performance Improvement #
Dereference pushdown improves performance for queries accessing nested fields in multiple ways. First, it increases the read throughput for table scans, reducing the CPU time. The pruning of fields during the scan also means lesser data to process for all downstream operators and tasks. So the early projections result in more optimal execution for any operations that involve shuffle or copy of data. Moreover, for ORC/Parquet, the read performance improves in the case of selective filters on subfields.
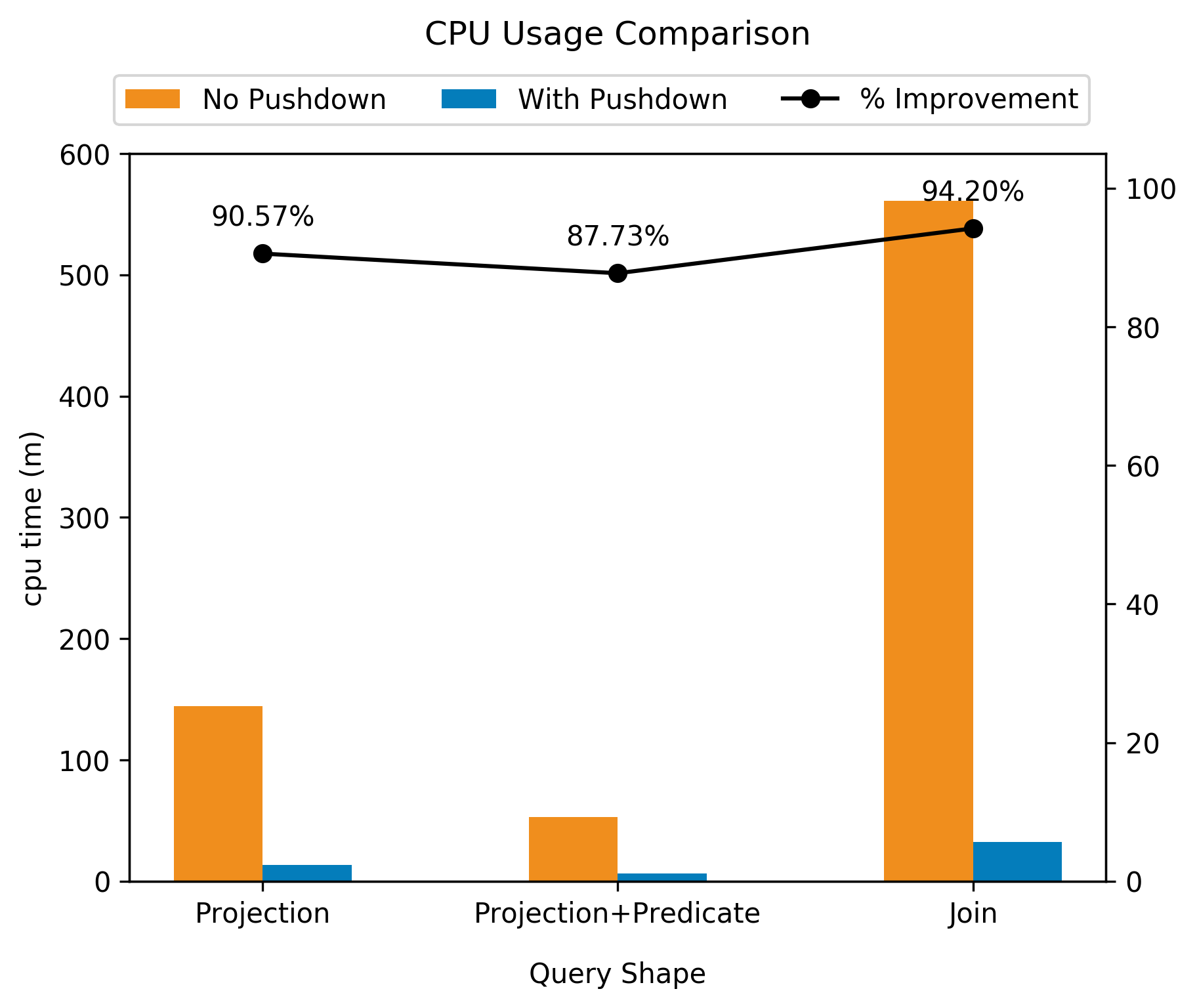
Below are some experimental results on a production dataset at LinkedIn which
contains 3 STRUCT columns, having ~20-30 small subfields in each. The
example queries used in the analysis access only a few subfields. The queries
have been listed as their approximate query shape for the sake of brevity. The
plots compare CPU usage, peak memory usage and averaged query wall time.
 |
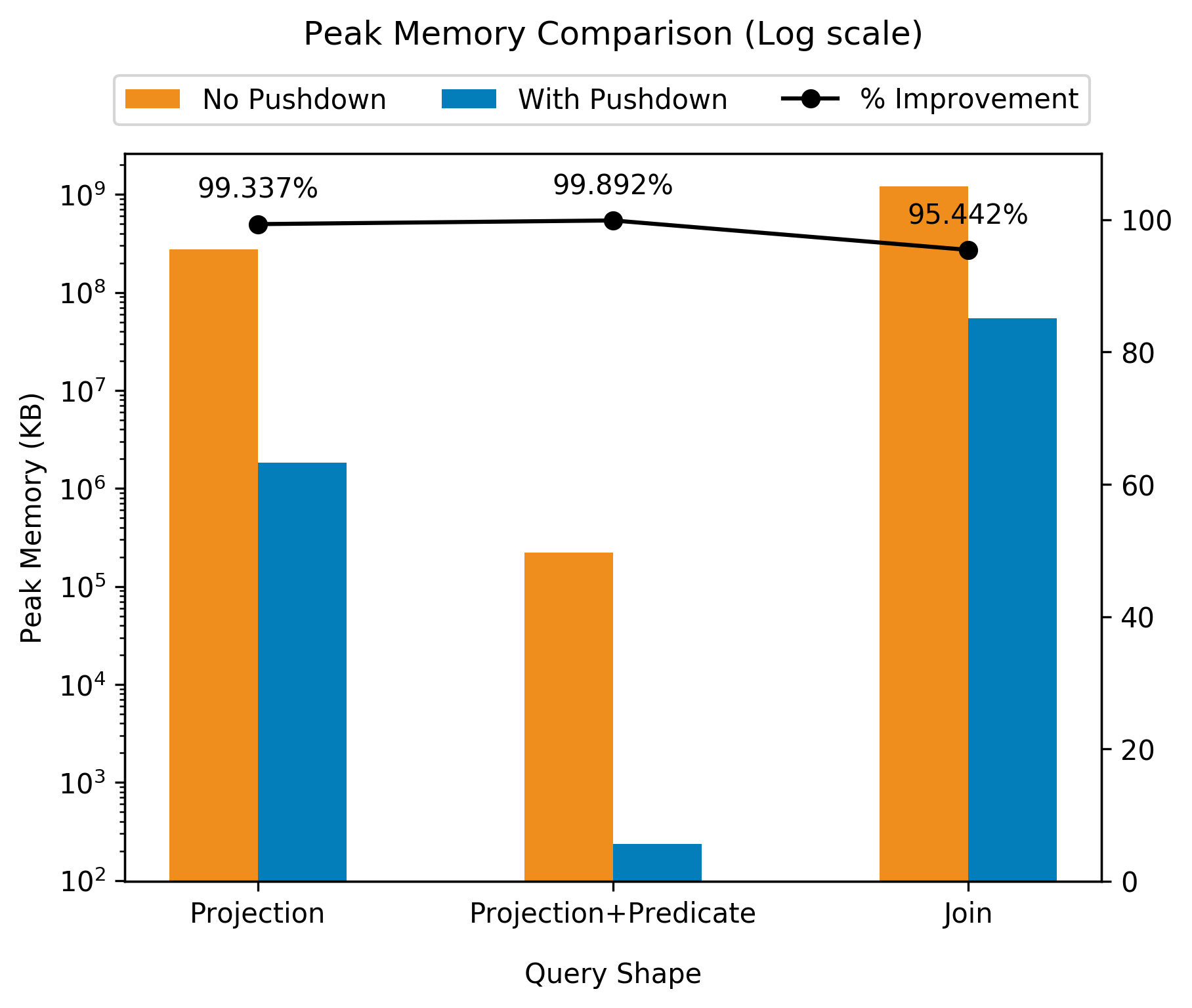 |
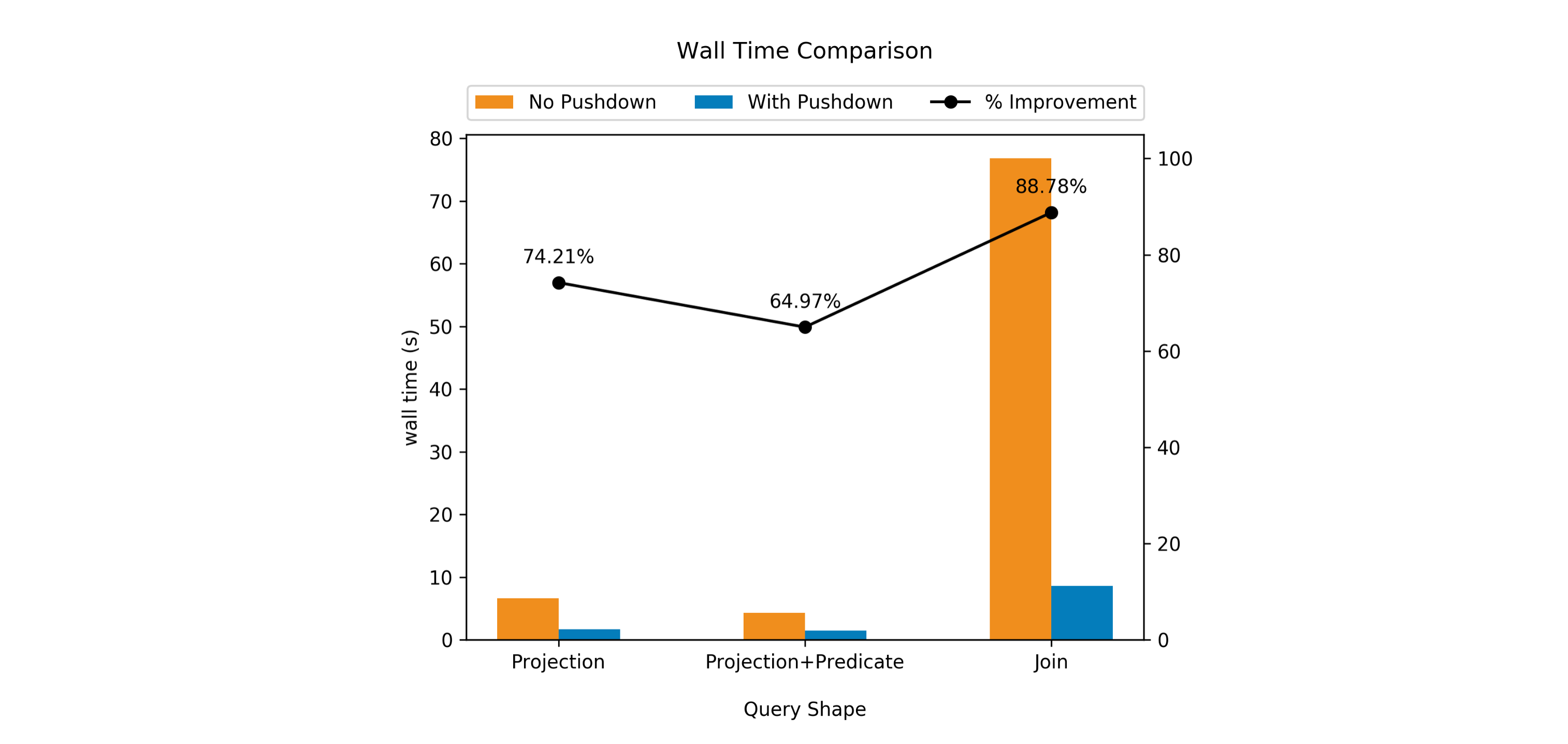
CPU usage and peak memory usage show orders-of-magnitude improvement in
presence of dereference pushdown. Query wall times also reduce considerably,
and this improvement is more drastic for the relatively complex JOIN query,
as expected.
Please note that these are not benchmarks! The performance improvement you’ll
see will vary depending on how many columns are contained in your nested data
versus how many you’ve referenced. At Lyft we saw improvements of 50x for some
queries!
Future Work #
The pushdown of dereference expressions can be extended to arrays. i.e.
dereference operations applied after unnesting an array should also get pushed
down to the readers. For example, using our jobs table from before, our
jobs.job_info structure may contain a repeating structure such as
required_skills. With the following query, the entire required_skills
structure would be read even though only a small part of it is being referenced.
SELECT S.description
FROM jobs J
CROSS JOIN UNNEST (job_info.required_skills) S
WHERE S.years_of_experience >= 2
The work for this improvement is being tracked in this issue.
Similar to Hive Connector, connector-level dereference pushdown can be extended to other connectors supporting nested types.
Another future improvement will be the pushdown of predicates on subfields for data stored in Parquet format. Although the pruning of nested fields occurs with Parquet, the predicates are not yet pushed down into the reader.
Conclusion #
Pushing down dereference operations in the query provides massive performance gains, especially while operating on large structs. At LinkedIn and Lyft, this feature has shown great impact for analytical queries on nested datasets.
We’re excited for the Presto community to try it out. Feel free to dig into this github issue for technical details. Please reach out to us on Slack for further disucssions or reporting issues.