TL;DR: The Hive connector is what you use in Trino for reading data from object storage that is organized according to the rules laid out by Hive, without using the Hive runtime code.
One of the most confusing aspects when starting Trino is the Hive connector. Typically, you seek out the use of Trino when you experience an intensely slow query turnaround from your existing Hadoop, Spark, or Hive infrastructure. In fact, the genesis of Trino, formerly known as Presto, came about due to these slow Hive query conditions at Facebook back in 2012.
So when you learn that Trino has a Hive connector, it can be rather confusing since you moved to Trino to circumvent the slowness of your current Hive cluster. Another common source of confusion is when you want to query your data from your cloud object storage, such as AWS S3, MinIO, and Google Cloud Storage. This too uses the Hive connector. If that confuses you, don’t worry, you are not alone. This blog aims to explain this commonly confusing nomenclature.
Hive architecture #
To understand the origins and inner workings of Trino’s Hive connector, you first need to know a few high level components of the Hive architecture.
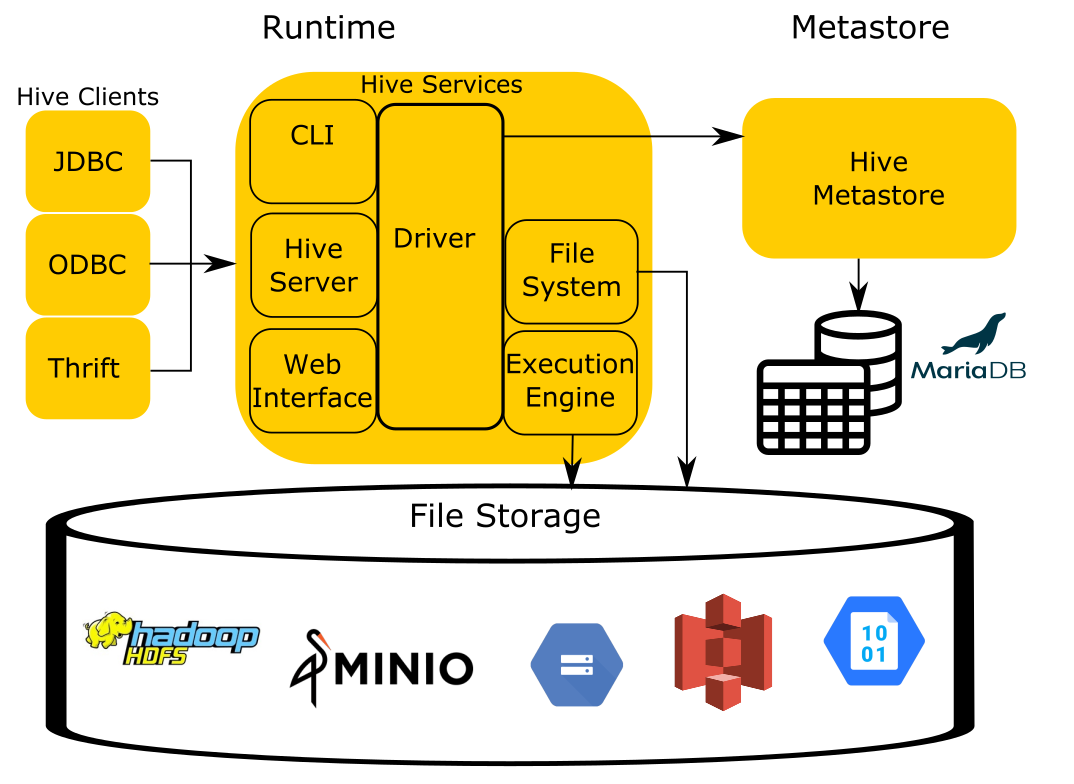
You can simplify the Hive architecture to four components:
The runtime contains the logic of the query engine that translates the SQL -esque Hive Query Language(HQL) into MapReduce jobs that run over files stored in the filesystem.
The storage component is simply that, it stores files in various formats and index structures to recall these files. The file formats can be anything as simple as JSON and CSV, to more complex files such as columnar formats like ORC and Parquet. Traditionally, Hive runs on top of the Hadoop Distributed Filesystem (HDFS). As cloud-based options became more prevalent, object storage like Amazon S3, Azure Blob Storage, Google Cloud Storage, and others needed to be leveraged as well and replaced HDFS as the storage component.
In order for Hive to process these files, it must have a mapping from SQL tables in the runtime to files and directories in the storage component. To accomplish this, Hive uses the Hive Metastore Service (HMS), often shortened to the metastore to manage the metadata about the files such as table columns, file locations, file formats, etc…
The last component not included in the image is Hive’s data organization specification. The documentation of this element only exists in the code in Hive and has been reverse engineered to be used by other systems like Trino to remain compatible with other systems.
Trino reuses all of these components except for the runtime. This is the same approach most compute engines take when dealing with data in object stores, specifically, Trino, Spark, Drill, and Impala. When you think of the Hive connector, you should think about a connector that is capable of reading data organized by the unwritten Hive specification.
Trino runtime replaces Hive runtime #
In the early days of big data systems, many expected query turnaround to take a long time due to the high volume of unstructured data in ETL workloads. The primary goal in early iterations of these systems was simply throughput over large volumes of data while maintaining fault-tolerance. Now, more businesses want to run fast interactive queries over their big data instead of running jobs that take hours and produce possibly undesirable results. Many companies have petabytes of data and metadata in their data warehouse. Data in storage is cumbersome to move and the data in the metastore takes a long time to repopulate in other formats. Since only the runtime that executed Hive queries needs replacement, the Trino engine utilizes the existing metastore metadata and files residing in storage, and the Trino runtime effectively replaces the Hive runtime responsible for analyzing the data.
Trino Architecture #
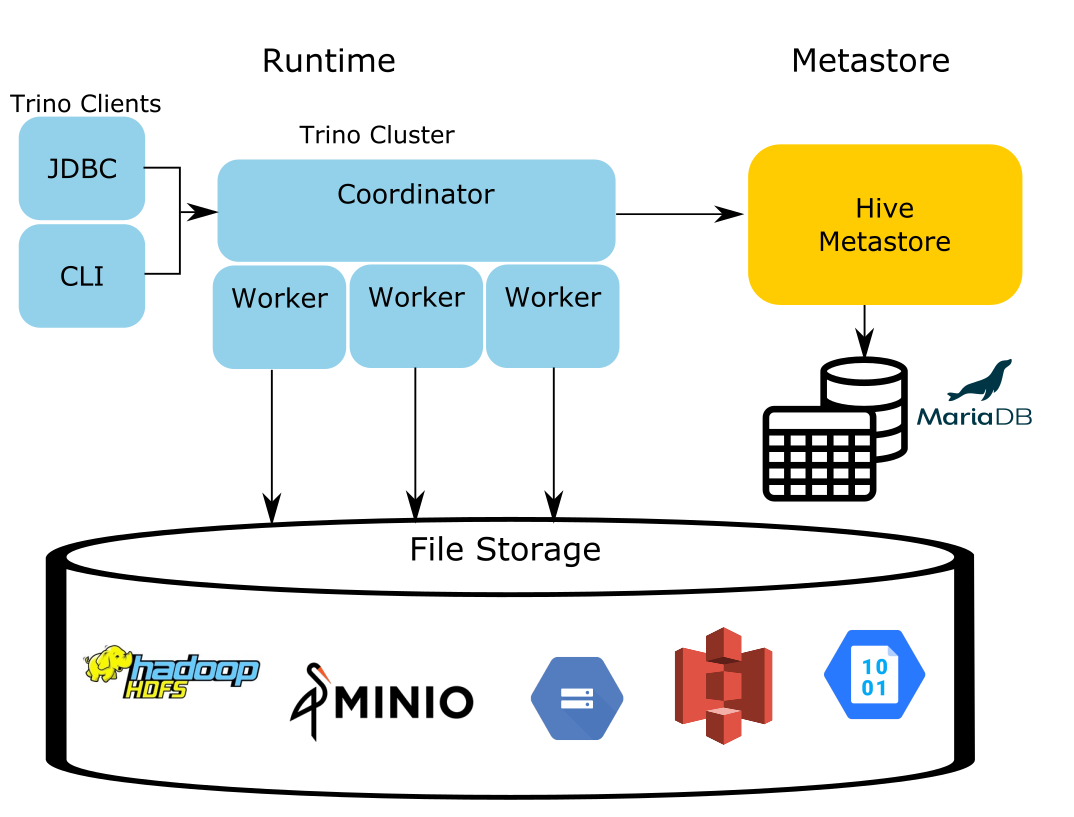
The Hive connector nomenclature #
Notice, that the only change in the Trino architecture is the runtime. The HMS still exists along with the storage. This is not by accident. This design exists to address a common problem faced by many companies. It simplifies the migration from using Hive to using Trino. Regardless of the storage component used the runtime makes use of the HMS and that is the reason this connector is the Hive connector.
Where the confusion tends to come from, is when you search for a connector from the context of the storage systems you want to query. You may not even be aware the metastore is a necessity or even exists. Typically, you look for an S3 connector, a GCS connector or a MinIO connector. All you need is the Hive connector and the HMS to manage the metadata of the objects in your storage.
The Hive Metastore Service #
The HMS is the only Hive process used in the entire Trino ecosystem when using the Hive connector. The HMS is actually a simple service with a binary API using the Thrift protocol. This service makes updates to the metadata, stored in an RDBMS such as PostgreSQL, MySQL, or MariaDB. There are other compatible replacements of the HMS such as AWS Glue, a drop-in substitution for the HMS.
Getting started with the Hive Connector on Trino #
To drive this point home, I created a tutorial that showcases using Trino and looking at the metadata it produces. In the following scenario, the docker environment contains four docker containers:
trino- the runtime in this scenario that replaces Hive.minio- the storage is an open-source cloud object storage.hive-metastore- the metastore service instance.mariadb- the database that the metastore uses to store the metadata.
You can play around with the system and optionally view the configurations. The
scenario asks you to run a query to populate data in MinIO and then see the
resulting metadata populated in MariaDB by the HMS. The next step asks you to
run queries over the mariadb database which holds the generated
metadata from the metastore.
If you have any questions or run into any issues with the example, you can find us on slack on the #dev or #general channels.
Have fun!
