At QazAI, we build data lakes as a service for companies. In the original architecture, we get raw data in S3, transform the S3 data with Hive, and then delivered the data to business units via our datamart built on Clickhouse (for optimal delivery speeds). Over time, we were dragged down by the slower speeds and high costs of running Hive, and started shopping for a faster and cheaper open source engine to do our ETL data transformations.
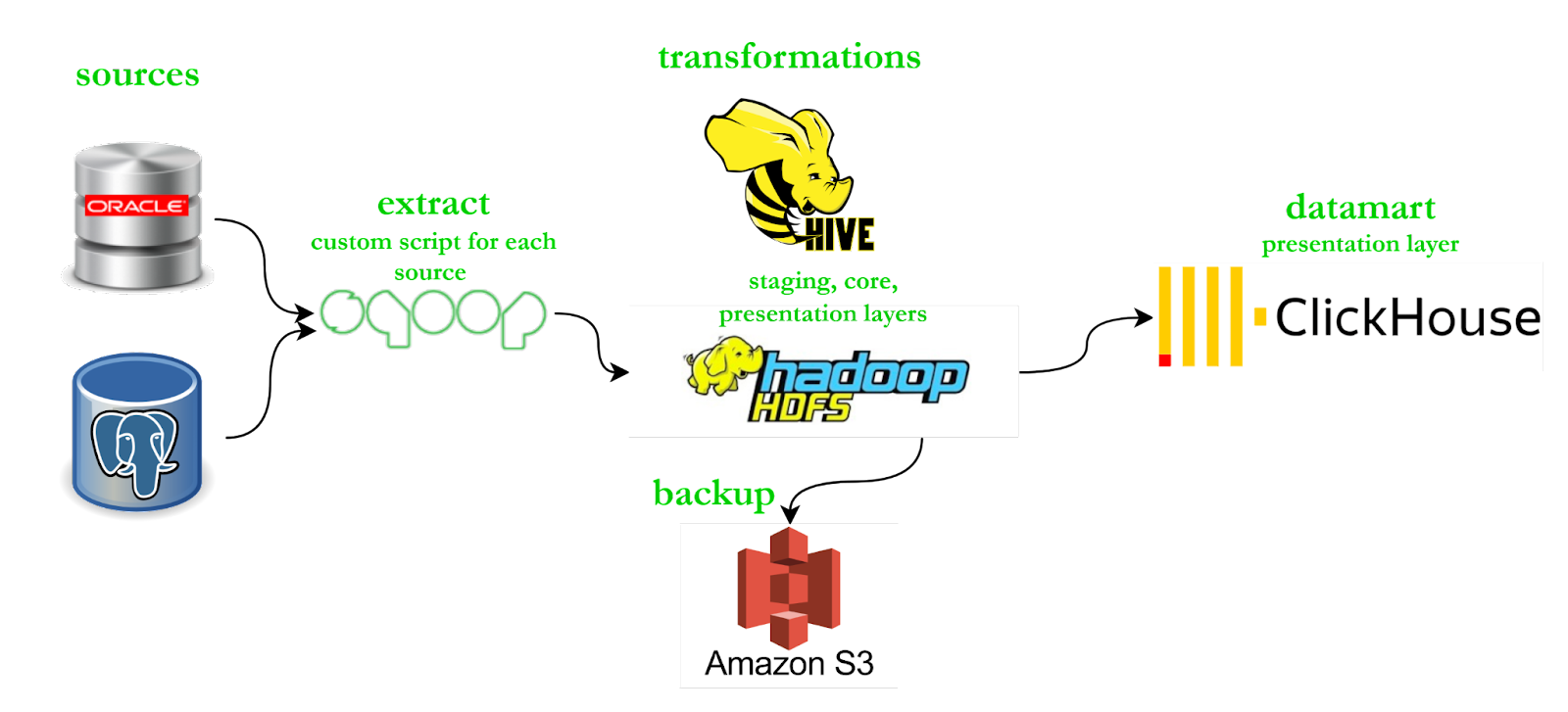
This diagram shows our existing stack. The big problem to solve was that the Hadoop cluster was extremely inefficient. This leads to slow queries, and up to 10x higher costs.
Like many others, I was initially drawn to Trino to run analytics over Hive tables because of its speed, but found many other advantages as well. Key among them are the following characteristics.
Speed #
Queries ran 10 to 100 times faster, compared to our old stack. It was fantastic, simply beyond our expectations.
Standard SQL #
Standard SQL dialect that everyone already knew. Data analysts loved getting to use a dialect they were already familiar with.
Federated analytics #
Ability to connect with other databases and run federated queries. After I had connected all the available data sources, I showed the results to the data analysts. They were simply amazed, some were shocked when the ‘join’ operation between the tables of various databases had been completed successfully. To emphasize - this saved days of work. You could join data from other data sources straight away, avoiding the need to create a staging layer in the data warehouse.
Simplicity of setup #
Trino just works out of the box. This is what makes it great. As open source users, we’re used to going through a complicated software setup process. But with Trino, there’s no need to deploy anything else. You simply install packages from the open source repository, and things work. It’s magical. To top that off, Trino feels like a commercial product with its detailed documentation and active Slack community that is willing to help you out on everything.
Exploring Trino as an option for ETL #
A great number of connectors, standard SQL, high processing speed - all these advantages raise an obvious question: ‘Why not use Trino for ETL processes as well?
At QazAI, the key blocker to using Trino for ETL was that Trino doesn’t have fault tolerance. As a result, our pipelines did not have reliable landing times, and required a lot of manual monitoring.
This is precisely what made Project Tardigrade so exciting for us. Proving that Trino is indeed a true community-driven project, Trino community members have embarked on the Tardigrade project. The main feature of this technology is the ability to divide the query into phases, and restart the failed phases. We’ve been running tests to explore this. The ETL pipeline on Trino running on 5 bare metal nodes is 20 times faster compared to ETL running on the stack consisting of Sqoop, HDFS, Hive, and custom Python scripts.
Testing Trino for ETL #
Let’s play a bit with the rental database called DVD.
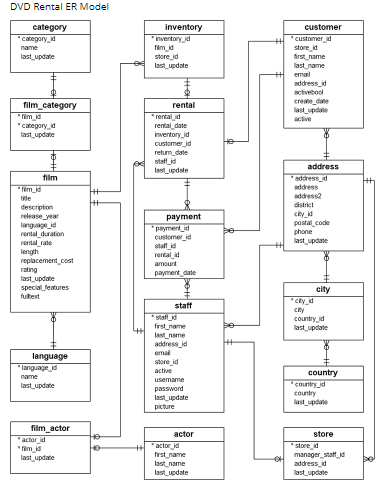
For instance, we create the database shown above in PostgreSQL and work with the rental table.
First, we move the table from PostgreSQL to our warehouse in HDFS and Hive.
CREATE TABLE hive.test.dvd_rental
WITH (format = 'PARQUET')
AS (SELECT
rental_id,
cast(rental_date AS timestamp) AS rental_date,
inventory_id,
cast(customer_id AS integer) AS customer_id,
cast(return_date AS timestamp) AS return_date,
cast(staff_id AS integer) AS staff_id,
cast(last_update AS timestamp) AS last_update
FROM postgresqldvd.public.rental)
Now we perform the same operation but we use the table of Iceberg format on S3 with hidden partitioning.
CREATE TABLE iceberg2.ice.dvd_rental
WITH (partitioning = ARRAY['month(rental_date)', 'bucket(inventory_id, 10)'],
format = 'PARQUET')
AS (SELECT
rental_id,
rental_date,
inventory_id,
cast(customer_id AS integer) AS customer_id,
return_date,
cast(staff_id AS integer) AS staff_id,
last_update
FROM postgresqldvd.public.rental)
Now we perform the same operation:
CREATE TABLE hive.test.dvd_staff
WITH (format = 'PARQUET')
AS (SELECT
staff_id,
first_name,
last_name,
cast(address_id AS integer) AS address_id,
email,
cast(store_id AS integer) AS store_id,
active,
username,
password,
cast(last_update AS timestamp) AS last_update,
picture
FROM postgresqldvd.public.staff)
CREATE TABLE hive.test.dvd_customer
WITH (format = 'PARQUET')
AS (SELECT
customer_id,
cast(store_id AS integer) AS store_id,
first_name,
last_name,
email,
cast(address_id AS integer) AS address_id,
activebool,
create_date,
cast(last_update AS timestamp) AS last_update,
active
FROM postgresqldvd.public.customer)
Great. What if there is a need to enrich the data with the employees’ and clients’ names? To do this, we create a table, move it to the core layer, and then apply denormalization.
Here we move the measurements table.
CREATE TABLE hive.test.dvd_staff
WITH (format = 'PARQUET')
AS (SELECT
staff_id,
first_name,
last_name,
cast(address_id AS integer) AS address_id,
email,
cast(store_id AS integer) AS store_id,
active,
username,
password,
cast(last_update AS timestamp) AS last_update,
picture
FROM postgresqldvd.public.staff)
CREATE TABLE hive.test.dvd_customer
WITH (format = 'PARQUET')
AS (SELECT
customer_id,
cast(store_id AS integer) AS store_id,
first_name,
last_name,
email,
cast(address_id AS integer) AS address_id,
activebool,
create_date,
cast(last_update AS timestamp) AS last_update,
active
FROM postgresqldvd.public.customer)
Let’s union the Staff and Customers tables.
CREATE TABLE hive.test.dvd_core_rental
WITH (format = 'PARQUET')
AS (SELECT
rental_id,
rental_date,
inventory_id,
cst.first_name AS customer_name, --cast(customer_id as integer) as customer_id,
cst.last_name AS customer_lastname,
cast(return_date AS timestamp) AS return_date,
stf.first_name AS staff_name, --cast(staff_id as integer) as staff_id,
stf.last_name AS staff_lastname,
rnt.last_update
FROM hive.test.dvd_rental rnt
LEFT JOIN hive.test.dvd_customer cst ON rnt.customer_id = cst.customer_id
LEFT JOIN hive.test.dvd_staff stf ON rnt.staff_id = stf.staff_id)
If this table is required by data analysts, then we can easily move it to the data mart (the Clickhouse layer we use to deliver data to end users).
CREATE TABLE clickhouse.default.rental_analysis_table
(
rental_id integer NOT NULL,
rental_date date,
inventory_id integer,
customer_name varchar NOT NULL,
customer_lastname varchar NOT NULL,
return_date date,
staff_name varchar,
staff_lastname varchar,
last_update date
)
WITH (engine = 'MergeTree',
order_by = ARRAY['customer_name', 'customer_lastname']);
A simple insert/select query and nothing more.
INSERT INTO clickhouse.default.rental_analysis_table
SELECT * FROM hive.test.dvd_core_rental
Alternatively we can easily move the datamart to Clickhouse directly from PostgreSQL without intermediate data layers.
INSERT INTO clickhouse.default.rental_analysis_table
SELECT
rental_id,
rental_date,
inventory_id,
cst.first_name AS customer_name,
cst.last_name AS customer_lastname,
cast(return_date AS timestamp) AS return_date,
stf.first_name AS staff_name,
stf.last_name AS staff_lastname,
rnt.last_update
FROM postgresqldvd.public.rental rnt
LEFT JOIN postgresqldvd.public.customer cst ON rnt.customer_id = cst.customer_id
LEFT JOIN postgresqldvd.public.staff stf ON rnt.staff_id = stf.staff_i
Great.
One may suggest that this sample dataset is a small one with only 16 000 rows. The production ETL is mostly run over huge tables containing millions or billions of rows. Let’s test. We work with the tpch database with the scaling factor 3000.
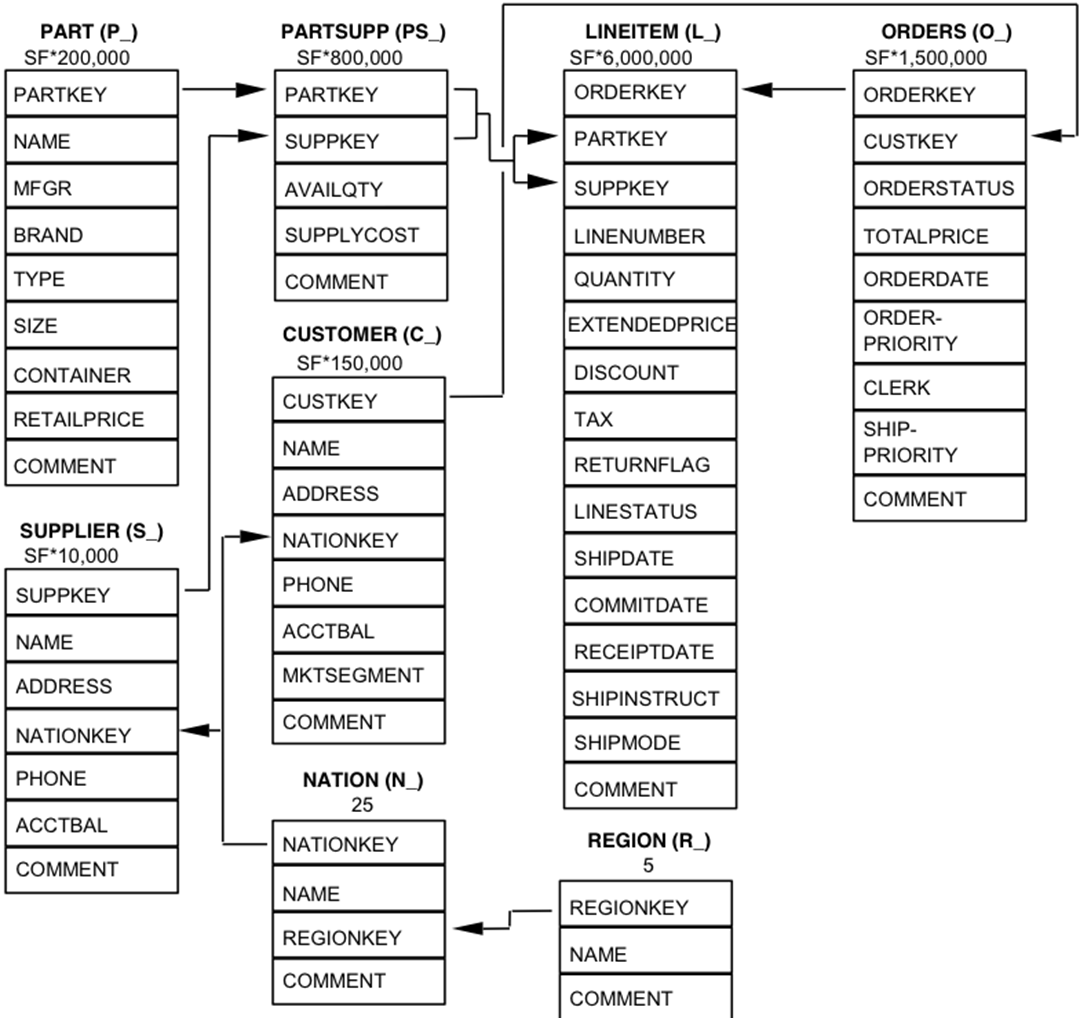
For testing, we consider three tables: lineitem (18 billion rows), orders (450 million rows) and partsupp (2.4 billion rows).
CREATE TABLE iceberg2.ice.tpch_sf3000_customer –(450 M)
WITH (format = 'ORC')
AS
SELECT *
FROM tpch.sf3000.customer
CREATE TABLE iceberg2.ice.tpch_sf3000_lineitem –(18 B)
WITH (format = 'ORC')
AS
SELECT *
FROM tpch.sf3000.lineitem
CREATE TABLE iceberg2.ice.tpch_sf3000_partsupp –(2,4 B)
WITH (format = 'ORC')
AS
SELECT *
FROM tpch.sf3000.partsupp
Then, we try to join all three of these tables as it is shown in the ER diagram.
Let’s make it more challenging by turning off one of the workers, which should
result in a query failure. To enable the automatic query rerun of the failed one
we set retry_policy=QUERY in config. properties.
CREATE TABLE iceberg2.ice.tpch_sf3000_lineitem_joined
WITH (format = 'ORC')
AS
SELECT litem.orderkey ,
litem.partkey ,
litem.suppkey ,
litem.linenumber ,
litem.quantity ,
litem.extendedprice ,
litem.discount ,
litem.tax ,
litem.returnflag ,
litem.linestatus ,
litem.shipdate ,
litem.commitdate ,
litem.receiptdate ,
litem.shipinstruct ,
litem.shipmode ,
litem.comment,
psupp.availqty ,
psupp.supplycost ,
ord.shippriority ,
ord.totalprice
FROM iceberg2.ice.tpch_sf100000_lineitem litem
LEFT JOIN iceberg2.ice.tpch_sf100000_partsupp psupp ON litem.partkey = psupp.partkey and litem.suppkey = psupp.suppkey
LEFT JOIN iceberg2.ice.tpch_sf100000_orders ord ON litem.orderkey = ord.orderkey
The query has been completed in 4 hours. Also, at query processing, worker 22 has been turned off. The query has been automatically started over and completed successfully. At the query processing, three tables have been joined (the triple join): 18 billion rows x 2.4 billion rows x 450 million rows.
This experiment gave us the confidence to move forward in our plans to rebuild our architecture with Trino in order to perform analytical and transformational manipulations upon data directly in S3, which will allow us to exclude HDFS and Hive interference in these processes.
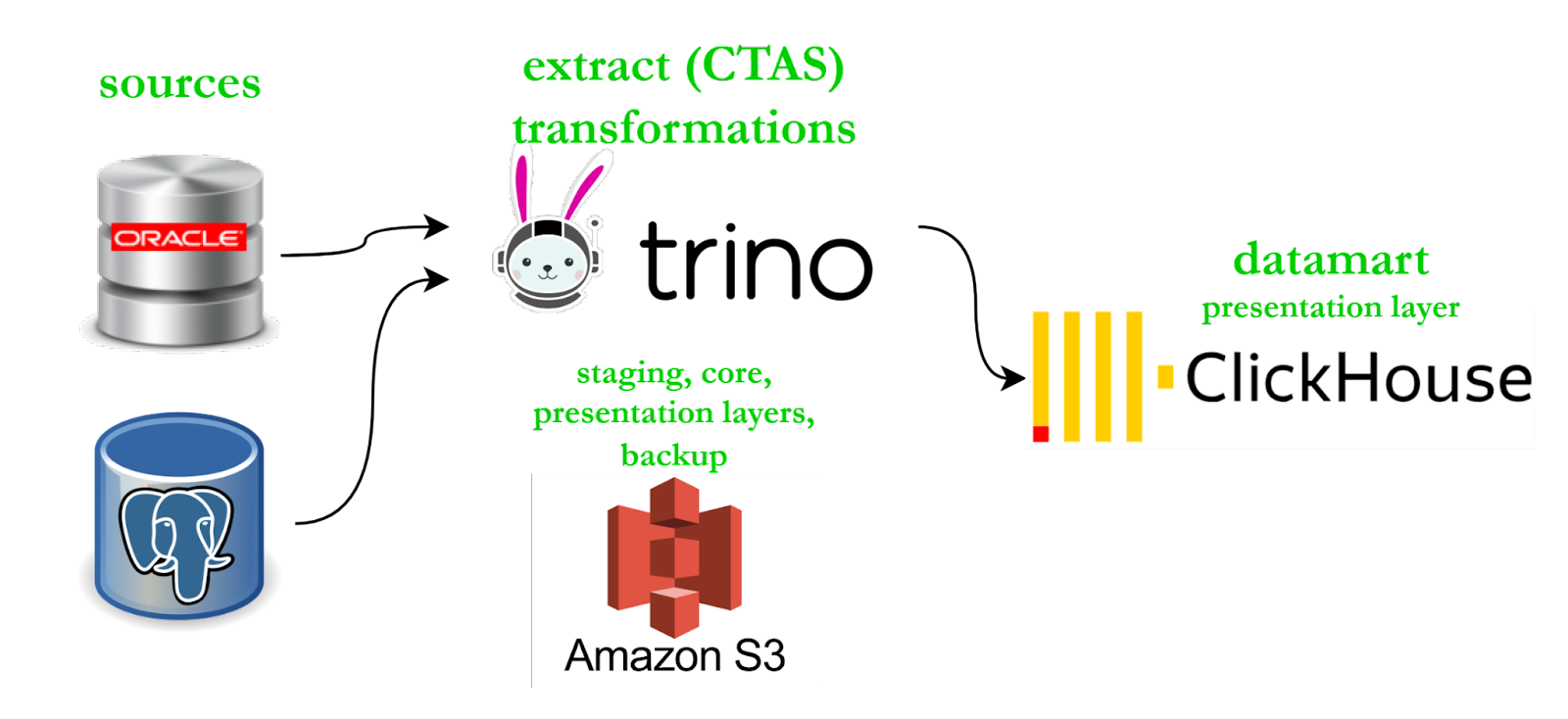
As a result we will achieve faster pipelines.
A huge thanks to the Trino development team and the Trino community for an excellent product, which I enjoy using and allows me to go beyond conventional usage patterns.
If you are looking for help building your data warehouse, or if you’re interested in joining us at QazAI, feel free to reach out to me at Baurzhan Kuspayev on the Trino Slack.
Note from Trino community: We welcome blog submissions from the community. If you have blog ideas, please send a message in the #dev chat. We will mail you Trino swag as a token of appreciation for successful submissions. Trino Slack.