The recent addition of the fault-tolerant execution architecture, delivered to Trino by Project Tardigrade, makes the use of Trino for running your ETL workloads an even more compelling alternative than ever before. We’ve set up a demo environment for you to easily give it a try in Starburst Galaxy.
With Project Tardigrade providing an out-of-the-box solution with advanced resource-aware task scheduling and granular retries at the task/query level, we still need a robust tool to schedule and manage workloads themselves. Apache Airflow is a great choice for this purpose.
Apache Airflow is a widely used workflow engine that allows you to schedule and run complex data pipelines. Airflow provides many plug-and-play operators and hooks to integrate with many third-party services like Trino.
To get started using Airflow to run data pipelines with Trino you need to complete the following steps:
- Install of Apache Airflow 2.10+
- Install the TrinoHook
- Create a Trino connection in Airflow
- Deploy a TrinoOperator
- Deploy your DAGs
Installing Apache Airflow in Docker #
The best way to get you going, if you don’t already have an Airflow cluster available, is to run Airflow in a container using docker compose. Just be aware that this is not best practice for a production environment.
Requirements for the host:
- Docker
- Docker Compose 1.28+
Step 1) Create a directory named airflow for all our configuration files.
$ mkdir airflow
Step 2) In the airflow directory create three subdirectory called dags, plugins, and logs.
$ cd airflow
$ mkdir dags plugins logs
Step 3) Download the Airflow docker compose yaml file.
$ curl -LfO 'https://airflow.apache.org/docs/apache-airflow/stable/docker-compose.yaml'
Step 4) Create an .env configuration file:
$ echo -e "AIRFLOW_UID=$(id -u)" > .env
$ echo "AIRFLOW_GID=0" >> .env
Step 5) Start the Airflow containers
$ docker-compose up -d
Installing the TrinoHook #
If running Airflow in docker, you need to install the TrinoHook in
all the docker containers using the apache/airflow:x.x.x image.
$ docker ps
CONTAINER ID IMAGE PORTS NAMES
cffdfaeb757e apache/airflow:2.3.0 0.0.0.0:8080->8080/tcp airflow_airflow-webserver_1
b0e72f479a66 apache/airflow:2.3.0 8080/tcp airflow_airflow-worker_1
4cdb11b3e5e3 apache/airflow:2.3.0 8080/tcp airflow_airflow-triggerer_1
41d3c3107ddb apache/airflow:2.3.0 0.0.0.0:5555->5555/tcp, 8080/tcp airflow_flower_1
229a11e9cdd3 apache/airflow:2.3.0 8080/tcp airflow_airflow-scheduler_1
68160240857d postgres:13 5432/tcp airflow_postgres_1
a96b98da85df redis:latest 6379/tcp airflow_redis_1
To install the TrinoHook you run pip install apache-airflow-providers-trino in
the first five containers. Run the following command replacing the container id of
each of the containers in your deployment.
$ docker exec -it <container_id> pip install apache-airflow-providers-trino
Once you have done that you need to restart all five containers:
$ docker container restart <container_id_1> ... <container_id_5>
Creating a Trino connection #
After you have installed the TrinoHook and restarted Airflow you can create a
connection to your Trino cluster through the Airflow web UI. If you just
installed Airflow, then go to http://localhost:8080 on your browser and login.
The default credentials unless changed are airflow for username and password.
Go to Admin > Connections.
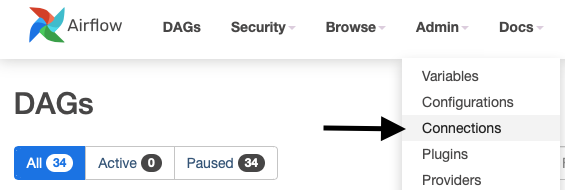
Click on the blue button to Add a new record.
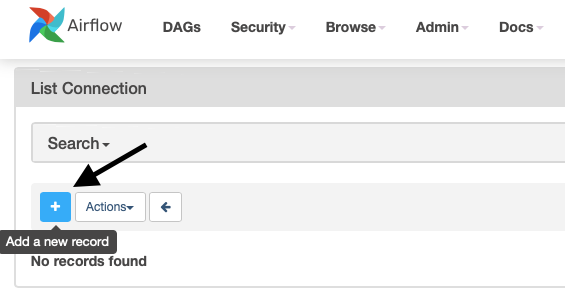
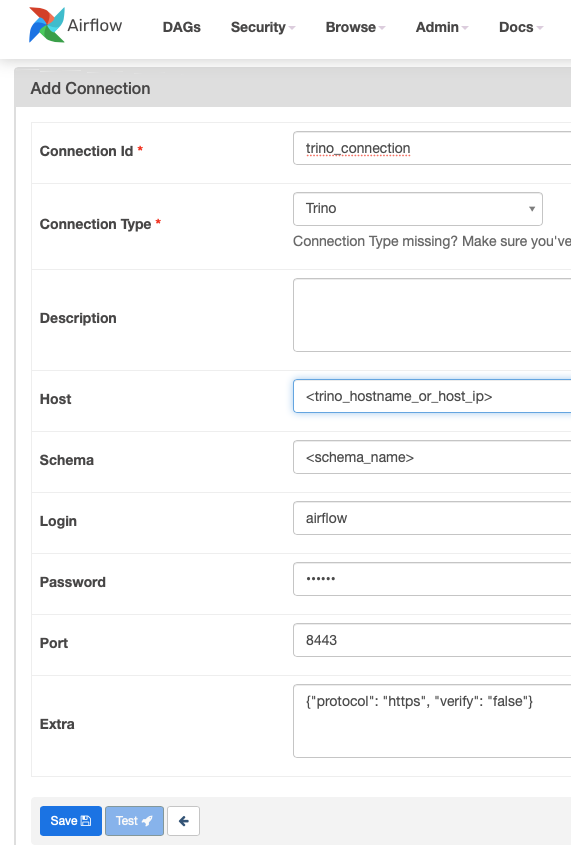
Select Trino from the Connection Type dropdown and provide the following information:
| Connection Id | Whatever you want to call your connection. |
| Host | The hostname or host ip of your trino cluster, e.g., localhost, 10.10.10.1, or www.mytrino.com |
| Schema | A schema in your Trino cluster. |
| Login | The username of the user that Airflow uses to connect to Trino. Best practice would be to create a service account like ‘airflow’. Just understand that this user access level is used to execute SQL statements in Trino. |
| Password | The password of the user that Airflow uses to connect to Trino if authentication is enabled. |
| Port | The port where the Trino Web UI can be accessed, e.g., 8080, 8443. |
| Extra | Additional settings, like protocol:https if using TLS, or verify:false if you are using a self-signed certificate. |
Be aware that the test button might not actually return any feedback for Trino connections.
Deploying a TrinoOperator #
At the time of writing this article there is no TrinoOperator, so you have to
write your own. You find an implementation in the following section, to get you started. This operator allows you to
execute any SQL statements that Trino supports such as SELECT, INSERT, CREATE, SET SESSION, and others. You can run multiple statements in a single task so
they are part of a single Trino session.
To create the TrinoOperator use your favorite text editor to create a file called
trino_operator.py with the following code in it and place it in the
airflow/plugins directory you created earlier. Airflow automatically compiles the code and you are ready to start
writing DAGs.
For those new to Airflow, DAG (Directed Acyclic Graph) is a core Airflow concept, a collection of tasks with dependencies and relationships that indicate to Airflow how they should be executed. DAGs are written in Python.
from airflow.models.baseoperator import BaseOperator
from airflow.utils.decorators import apply_defaults
from airflow.providers.trino.hooks.trino import TrinoHook
import logging
from typing import Sequence, Callable, Optional
def handler(cur):
cur.fetchall()
class TrinoCustomHook(TrinoHook):
def run(
self,
sql,
autocommit: bool = False,
parameters: Optional[dict] = None,
handler: Optional[Callable] = None,
) -> None:
""":sphinx-autoapi-skip:"""
return super(TrinoHook, self).run(
sql=sql, autocommit=autocommit, parameters=parameters, handler=handler
)
class TrinoOperator(BaseOperator):
template_fields: Sequence[str] = ('sql',)
@apply_defaults
def __init__(self, trino_conn_id: str, sql, parameters=None, **kwargs) -> None:
super().__init__(**kwargs)
self.trino_conn_id = trino_conn_id
self.sql = sql
self.parameters = parameters
def execute(self, context):
task_instance = context['task']
logging.info('Creating Trino connection')
hook = TrinoCustomHook(trino_conn_id=self.trino_conn_id)
sql_statements = self.sql
if isinstance(sql_statements, str):
sql = list(filter(None,sql_statements.strip().split(';')))
if len(sql) == 1:
logging.info('Executing single sql statement')
sql = sql[0]
return hook.get_first(sql, parameters=self.parameters)
if len(sql) > 1:
logging.info('Executing multiple sql statements')
return hook.run(sql, autocommit=False, parameters=self.parameters, handler=handler)
if isinstance(sql_statements, list):
sql = []
for sql_statement in sql_statements:
sql.extend(list(filter(None,sql_statement.strip().split(';'))))
logging.info('Executing multiple sql statements')
return hook.run(sql, autocommit=False, parameters=self.parameters, handler=handler)
Deploying a DAG #
Now that you have deployed the TrinoOperator you can start writing DAGs for your data pipelines. Let’s write and deploy a simple sample DAG. DAGs just like the TrinoOperator are deployed into the airflow/dags directory you created earlier.
Create a file called my_first_trino_dag.py with the following code, and save it in the airflow/dags directory.
import pendulum
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from trino_operator import TrinoOperator
## This method is called by task2 (below) to retrieve and print to the logs the return value of task1
def print_command(**kwargs):
task_instance = kwargs['task_instance']
print('Return Value: ',task_instance.xcom_pull(task_ids='task_1',key='return_value'))
with DAG(
default_args={
'depends_on_past': False
},
dag_id='my_first_trino_dag',
schedule_interval='0 8 * * *',
start_date=pendulum.datetime(2022, 5, 1, tz="US/Central"),
catchup=False,
tags=['example'],
) as dag:
## Task 1 runs a Trino select statement to count the number of records
## in the tpch.tiny.customer table
task1 = TrinoOperator(
task_id='task_1',
trino_conn_id='trino_connection',
sql="select count(1) from tpch.tiny.customer")
## Task 2 is a Python Operator that runs the print_command method above
task2 = PythonOperator(
task_id = 'print_command',
python_callable = print_command,
provide_context = True,
dag = dag)
## Task 3 demonstrates how you can use results from previous statements in new SQL statements
task3 = TrinoOperator(
task_id='task_3',
trino_conn_id='trino_connection',
sql="select ")
## Task 4 demonstrates how you can run multiple statements in a single session.
## Best practice is to run a single statement per task however statements that change session
## settings must be run in a single task. The set time zone statements in this example will
## not affect any future tasks but the two now() functions would timestamps for the time zone
## set before they were run.
task4 = TrinoOperator(
task_id='task_4',
trino_conn_id='trino_connection',
sql="set time zone 'America/Chicago'; select now(); set time zone 'UTC' ; select now()")
## The following syntax determines the dependencies between all the DAG tasks.
## Task 1 will have to complete successfully before any other tasks run.
## Tasks 3 and 4 won't run until Task 2 completes.
## Tasks 3 and 4 can run in parallel if there are enough worker threads.
task1 >> task2 >> [task3, task4]
Just like with the TrinoOperator DAGs are picked up and compiled by Airflow automatically. When Airflow fails to compile your DAG it displays an error message at the top of the page in the main page where all the DAGs are listed. You can refresh this page a few times until your DAG is either added to the list or you see an error message. You can expand the message to see the source of the error. Usually the information provided is enough to understand the issue.
Once the DAG shows up on your list you can trigger a manual run, using the play button on the right to activate your DAG. I recommend switching to the Graph view, using the action links on the right to see how tasks change status as they run.
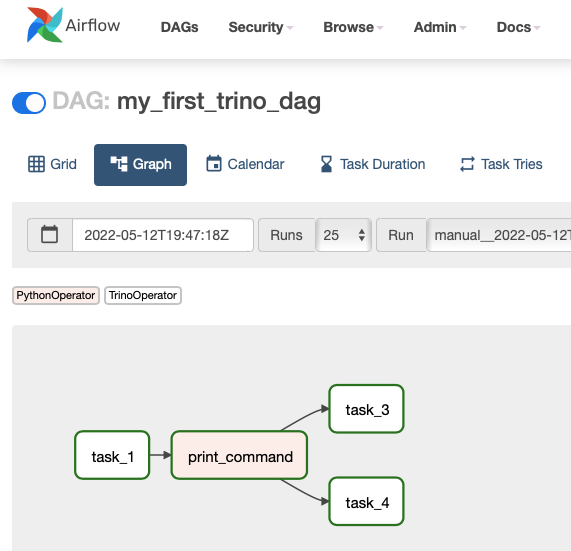
You can see logs for each task by clicking on the corresponding box and selecting Log from the options at the top.
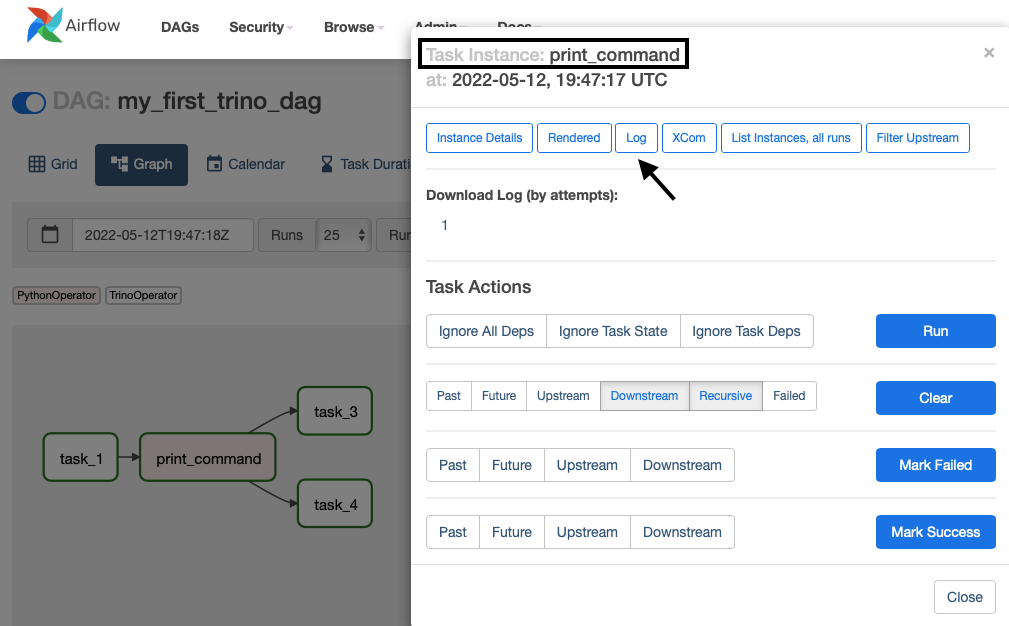
Check out the logs for the print_command task to see the return value of select statement from task_1
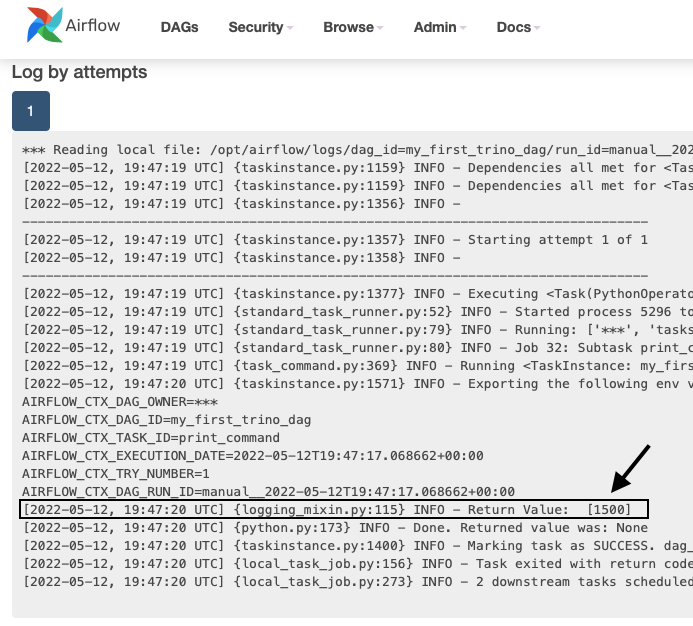
As you can see, output from print() commands can be found in these logs.
Conclusion #
Apache Airflow has been around for many years now. It is used by many large companies in production environments. The open source project has an active community, and I expect that in the near future we will have an official TrinoHook with additional out-of-the-box functionality. While there might be a slight learning curve for new users I think that is worth it.
On the Trino side there are some exciting enhancements for fault-tolerant execution on the roadmap of Project Tardigrade that will make Trino and Airflow an even better combination.
Stay tuned.
Note from Trino community: We welcome blog submissions from the community. If you have blog ideas, send a message in the #dev chat. We will mail you Trino swag as a token of appreciation for successful submissions. Enter the Trino Slack and join the conversation in the #project-tardigrade channel.