By using dynamic filtering via run-time predicate pushdown, we can significantly optimize highly-selective inner-joins.
Introduction #
In the highly-selective join scenario, most of the probe-side rows are dropped immediately after being read, since they don’t match the join criteria.
Our idea was to extend Presto’s predicate pushdown support from the planning phase to run-time, in order to skip reading the non-relevant rows from our connector into Presto1. It should allow much faster joins, when the build-side scan results in a low-cardinality table:
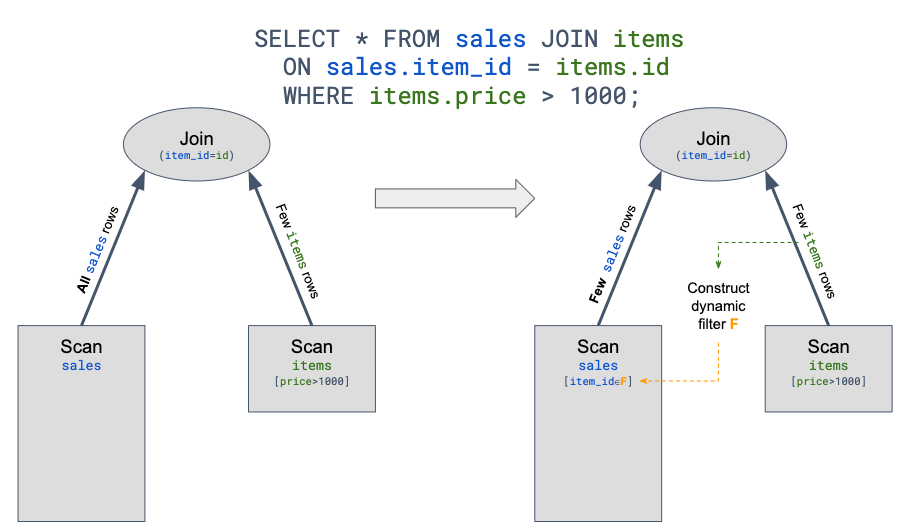
The approach above is called “dynamic filtering”, and there is an ongoing effort to integrate it into Presto.
The main difficulty is the need to pass the build-side values from the inner-join operator to the probe-side scan operator, since the operators may run on different machines. A possible solution is to use the coordinator to facilitate the message passing. However, it requires multiple changes in the existing Presto codebase and careful design is needed to avoid overloading the coordinator.
Since it’s a complex feature with lots of moving parts, we suggest the approach below that allows solving it in a simpler way for specific join use-cases. We note that parts of the implementation below will also help implementing the general dynamic filtering solution.
Design #
Our approach relies on the cost-based optimizer (CBO) that allows using “broadcast” join, since in our case the build-side is much smaller than the probe-side. In this case, the probe-side scan and the inner-join operators are running in the same process - so the message passing between them becomes much simpler.
Therefore, most of the required changes are at the
LocalExecutionPlanner
class, and there is no dependencies on the planner nor the coordinator.
Implementation #
First, we make sure that a broadcast join is used and that the local stage query plan contains the probe-side
TableScan node.
Otherwise - we don’t apply our the optimization since we need access to the probe-side PageSourceProvider
for predicate pushdown.
Then, we add a new “collection” operator, just before the hash-builder operator as described below:
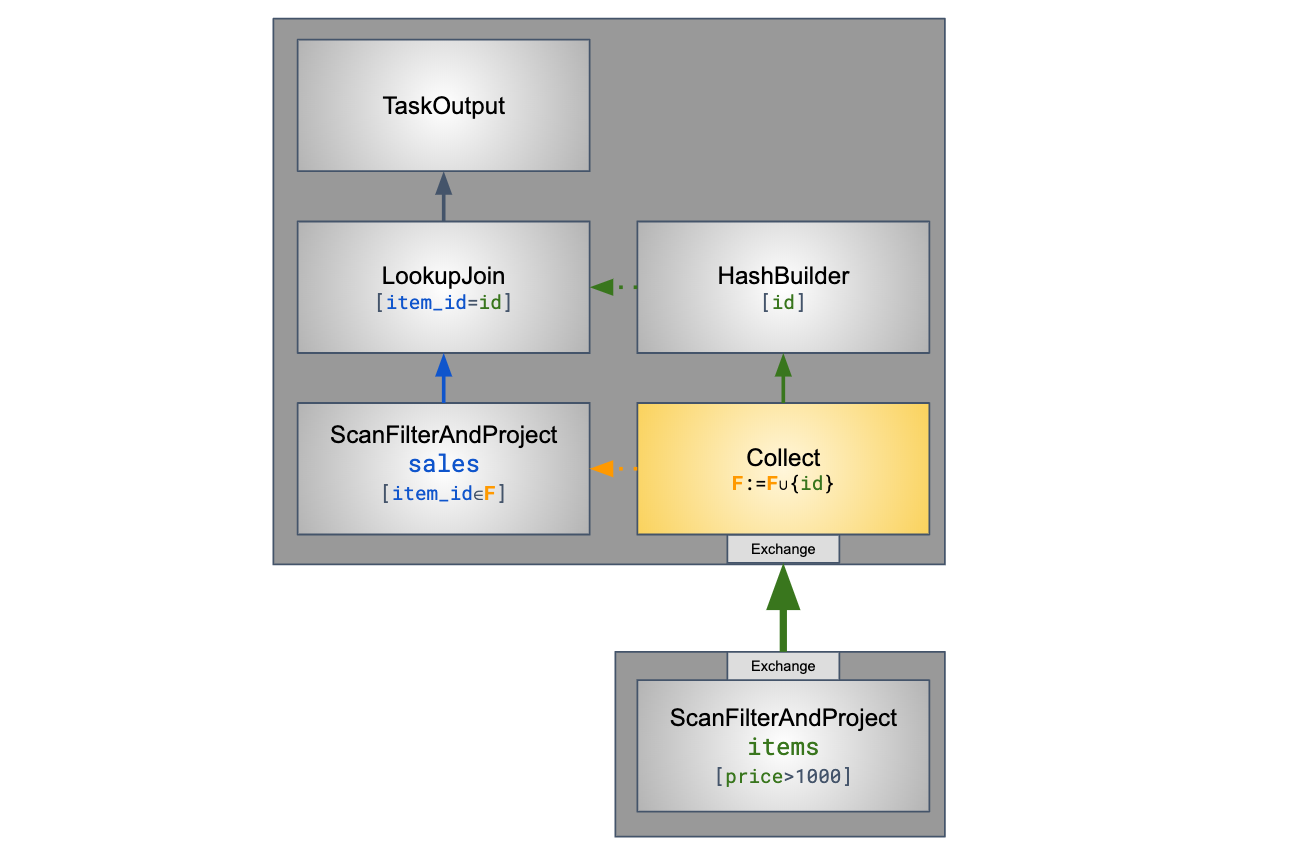
This operator collects the build-side values, and after its input is over, exposes the resulting dynamic filter as a
TupleDomain
to the probe-side PageSourceProvider.
Since the probe-side scan operators are running concurrently with the build-side collection, we don’t block the first probe-side splits - but allow them to be processed while dynamic filters collection is in progress.
The lookup-join operator is not changed, but the optimization above allows it to process much less probe-side rows, while keeping the result the same.
Benchmarks #
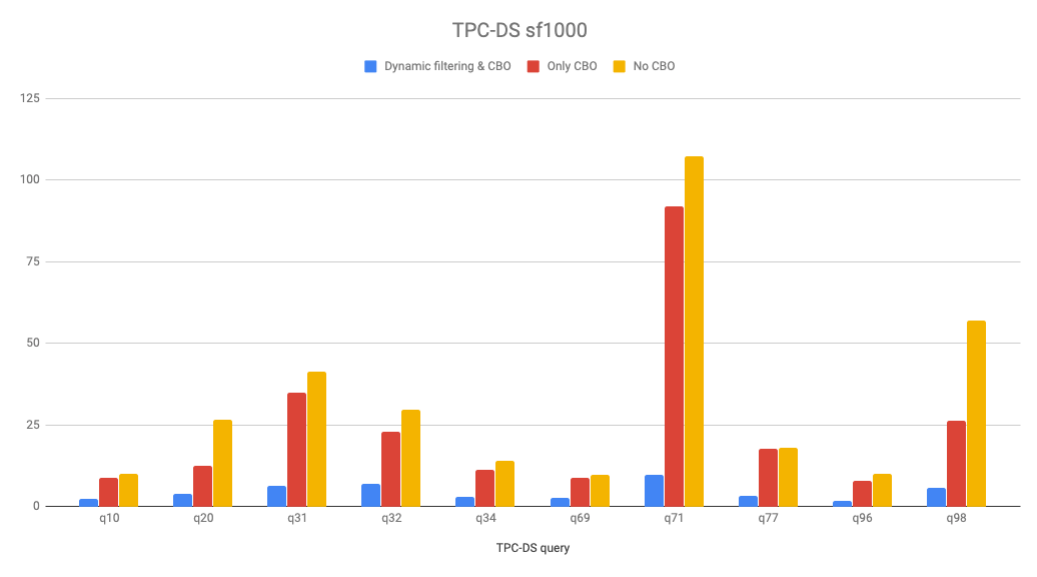
We ran TPC-DS queries on i3.metal 3-node Varada cluster using TPC-DS scale 1000 data. The following queries benefit the most for our dynamic filtering implementation (measuring the elapsed time in seconds).
| Query | Dynamic filtering & CBO | Only CBO | No CBO |
|---|---|---|---|
| q10 | 2.5 | 8.9 | 10.0 |
| q20 | 3.9 | 12.6 | 26.7 |
| q31 | 6.5 | 34.8 | 41.5 |
| q32 | 6.9 | 23.0 | 29.7 |
| q34 | 3.1 | 11.4 | 14.1 |
| q69 | 2.7 | 8.9 | 9.9 |
| q71 | 9.9 | 91.8 | 107.4 |
| q77 | 3.5 | 17.9 | 18.1 |
| q96 | 1.9 | 8.0 | 10.2 |
| q98 | 5.8 | 26.5 | 57.1 |
For example, running the TPC-DS q71 query results in ~9x performance improvement:
| Dynamic filtering | Enabled | Disabled |
|---|---|---|
| Elapsed (sec) | 10 | 92 |
| CPU (min) | 14 | 127 |
| Data read (GB) | 11 | 112 |
Discussion #
These queries are joining large fact “sales” tables with much smaller and filtered dimension tables (e.g. “items”, “customers”, “stores”) - resulting in significant optimization by using dynamic filtering.
Note that we rely on the fact that our connector allows efficient run-time filtering of the build-side table, by using an inline index for every column for each split.
We also rely on the CBO and statistics’ estimation to correctly convert join distribution type to “broadcast” join. Since current statistics’ estimation doesn’t support all query plans, this optimization cannot be currently applied for some types of aggregations (e.g. TPC-DS q19 query).
In addition, our current dynamic filtering doesn’t support multiple join operators in the same stage, so there are some TPC-DS queries (e.g. q13) that may be optimized further.
Future work #
The implementation above is currently in the process of being reviewed and will be available in a release soon. In addition, we intend to improve the existing implementation to resolve the limitations described above, and to support more join patterns.
-
Initially we had experimented with adding Index Join support to our connector, but since it requires a global index and efficient lookups for high performance, we switched to the dynamic filtering approach. ↩