Queries with CROSS JOIN UNNEST clause are expected to have a significant performance improvement starting version 316.
Executive Summary #
The execution plans for queries with a CROSS JOIN UNNEST clause contain an Unnest Operator. The previous implementation of Unnest Operator performed a deep copy on all input blocks to generate output blocks. This caused high CPU consumption and memory allocation for the operator, and impacted the performance of such queries. The impact was worse for UNNEST queries accessing a high number of columns, or even a few columns with deeply nested schema.
We realized that the implementation can be made more efficient by avoiding copies in the Unnest Operator, if possible. Using dictionary blocks to create output blocks pointing to input elements has given us significant CPU and memory benefits by avoiding copies. The benchmark results for the new Unnest Operator implementation show more than ~10x gain in CPU time and 3x~5x gain in memory allocation.
Let’s try to understand this change with an example. At LinkedIn, the most common usage for CROSS JOIN UNNEST clause is seen to be for unnesting a single array or map column. A sample query with the clause would look like the following:
SELECT T.c0, U.unnest_c1
FROM T CROSS JOIN UNNEST(c1) AS U(unnest_c1)
The plots below compare the performance of Unnest Operator in the previous and the current implementation for 3 different cases. Every case evaluates the Unnest Operator performance for a query like the above, on a table T with two columns c0 and c1. For all the 3 cases, c0 is a VARCHAR type column. But the nested column c1 is of ARRAY(VARCHAR), MAP(VARCHAR, VARCHAR) and ARRAY(ROW(VARCHAR, VARCHAR, VARCHAR)) types respectively. All the VARCHAR elements in both the columns have length 50, and the arrays in the second column have lengths distributed uniformly between 0 and 300.
We used JMH benchmark to measure the performance of the queries in terms of CPU time and memory allocations per operation. An “operation” (for the purposes of this measurement) is defined as the processing of 10,000 rows by an unnest operator. These results reflect the speedup of the operator and may not extend to the overall query execution.
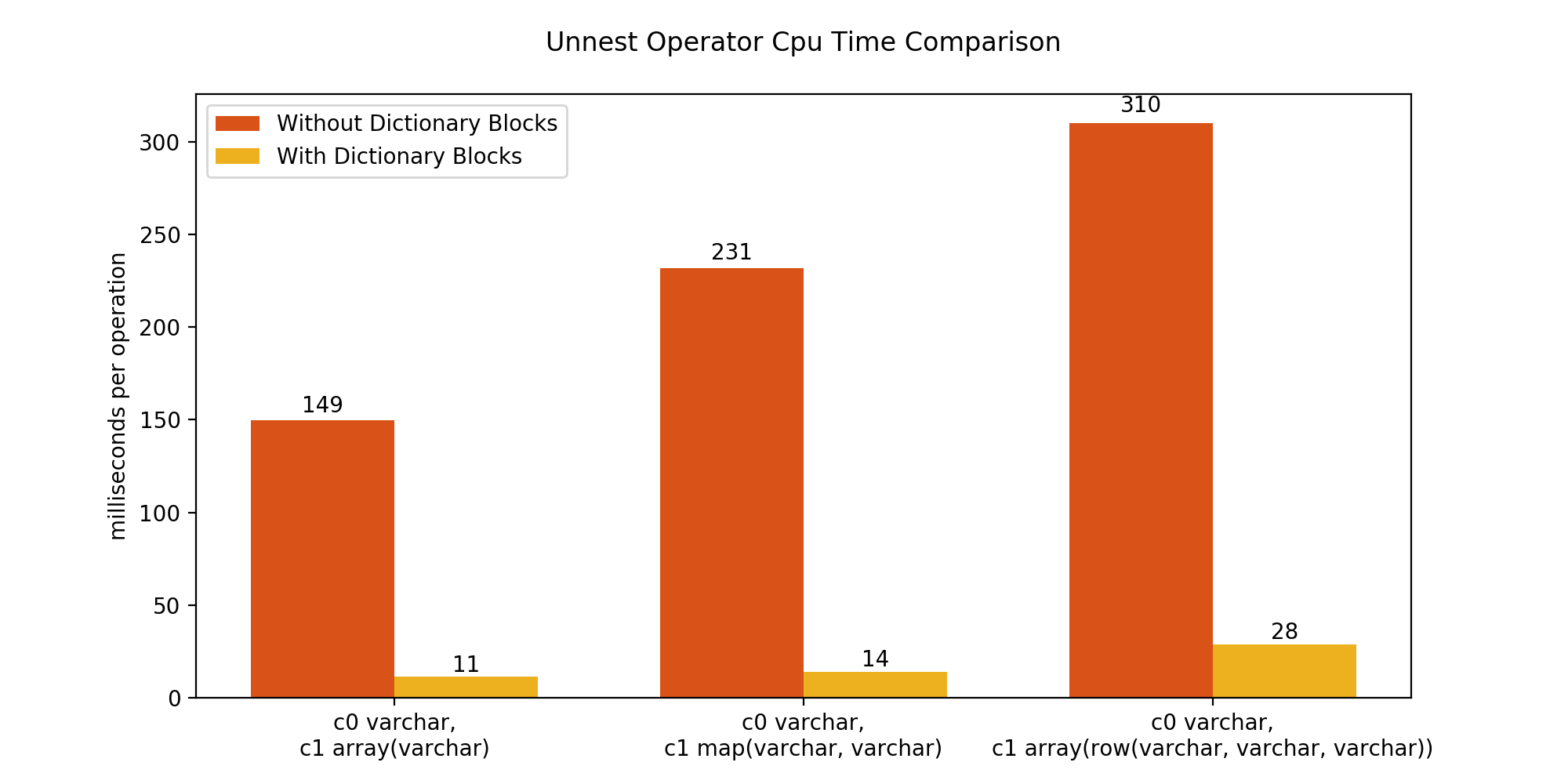
The figure above compares the CPU times before and after the enhancements. For the three cases, we see that every operation finishes more than 10x faster. The new implementation removes the need of copying data for output block generation in this case, giving us significant CPU time savings.
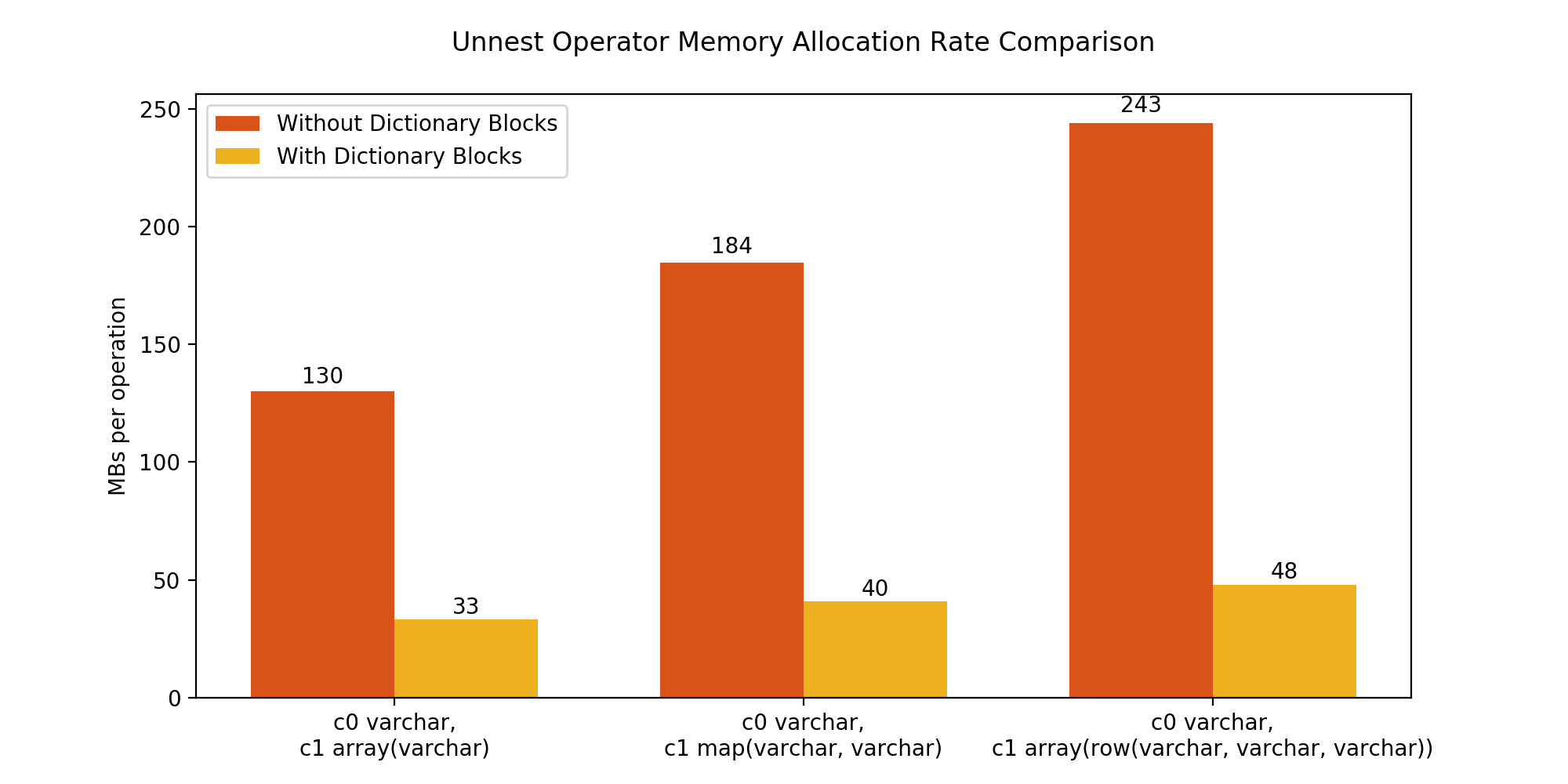
The figure above compares the memory allocation per operation before and after the enhancement. The new Unnest Operator implementation does not allocate new large memory chunks for output blocks. Instead, it uses integer typed pointers pointing to input block elements, which results in smaller memory allocations than creating new VARCHAR blocks. This brings down the allocation rate by 3x-5x in this example.
Let’s dig into the design and implementation details.
Background #
An Operator in Presto performs a step of computation on data. The local execution plan for a task involves pipelines of operators. Operators process pages coming from the previous Operator in the pipeline, and produce output pages for the next one. Code for an Operator has to be efficient, since it may be evaluated billions of times for a single query.
A Page is made of a set of blocks storing data for different columns. DictionaryBlock is one of the Block implementations in Presto. The elements in a DictionaryBlock are represented using an integer array (called ids) and a reference to another block. The values in ids array represent elements of the DictionaryBlock by pointing to element indices in the referenced block. DictionaryBlocks are useful to perform more efficient encoding of columns with duplicates.
The Unnest Operator was implemented before the DictionaryBlock was added. We saw an opportunity to enhance the performance of this Operator by using DictionaryBlocks. A DictionaryBlock can enable the Unnest Operator to reuse already constructed input blocks. Using DictionaryBlock for the Unnest operator eliminates the need for expensive copies and results in significant compute and memory savings.
Design #
Consider the following CROSS JOIN UNNEST query on a table with one VARCHAR type and one ARRAY(VARCHAR) type columns.
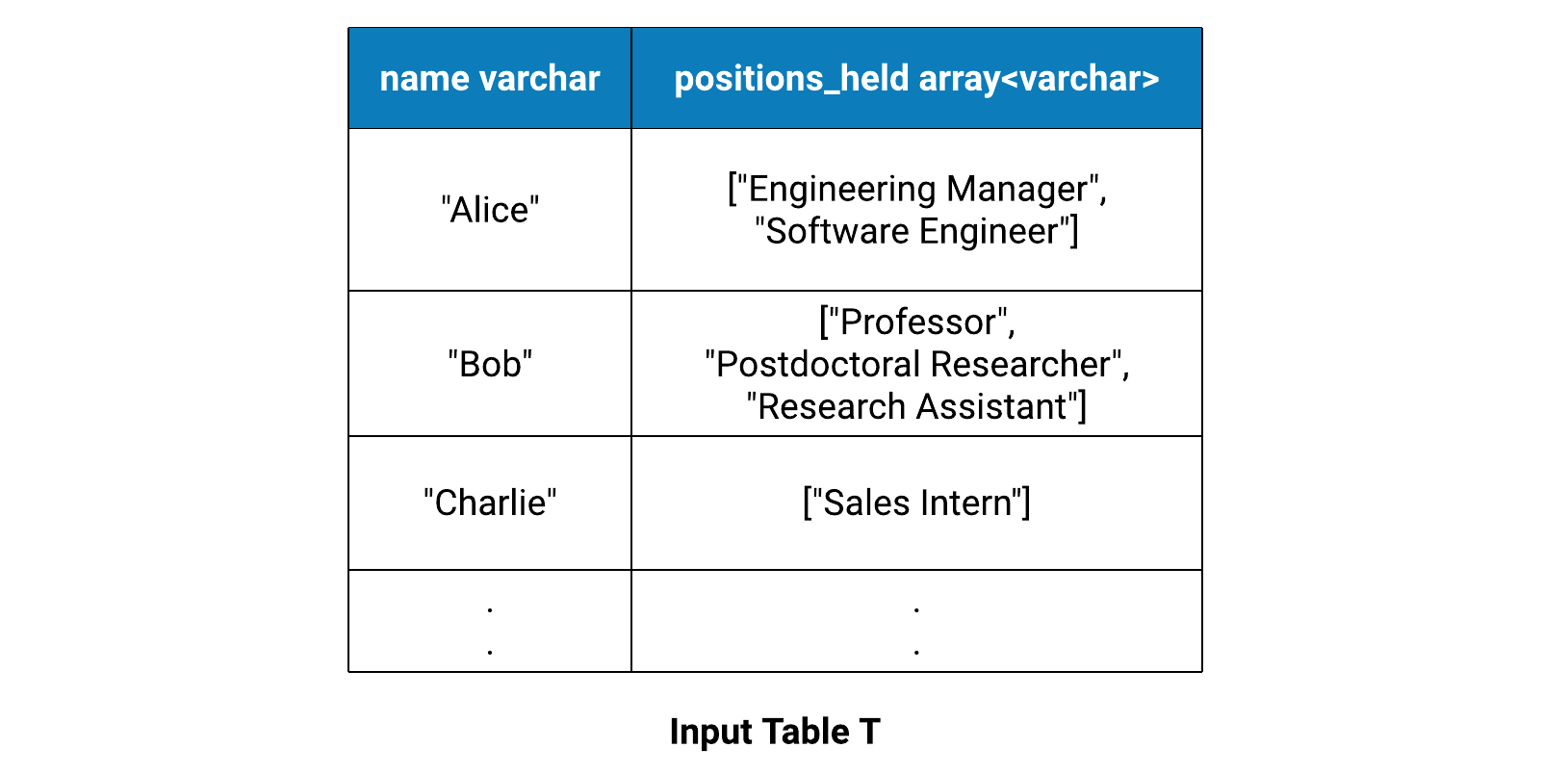
SELECT T.name, U.unnested_position
FROM T CROSS JOIN UNNEST(positions_held) AS U(unnested_position)
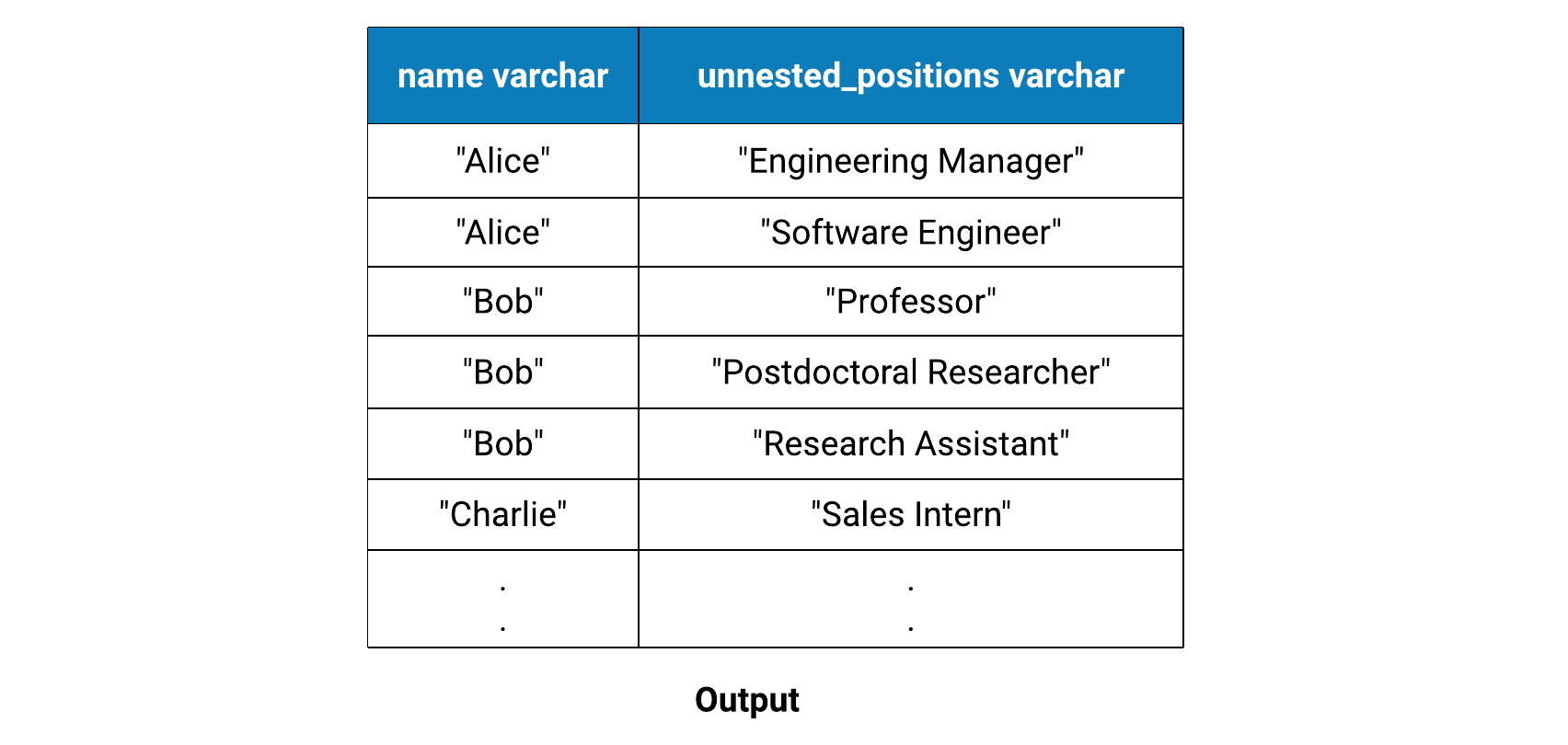
Elements of name column are replicated while we unnest elements in positions_held column. In this example, name is a “replicated column”, and positions_held will be referred to as an “unnested column”.
Multiple unnest columns are also allowed (eg. UNNEST(positions_held, company_name) AS U(unnested_position, unnested_company)), but that case is not that common. It requires special handling, and we talk about that later in the post.
In the old design, an element from a replicated column would get copied over n times for building the output, where n is the cardinality of the element in the unnest column. For example, Alice and Bob will be copied 2 and 3 times respectively. In the new design, the output block will contain n pointers to the element in the input block, without actually copying. It will store a reference to the input block as well. The benefits here are proportional to the replicated column element sizes. The bigger the element size, the greater the speedup.
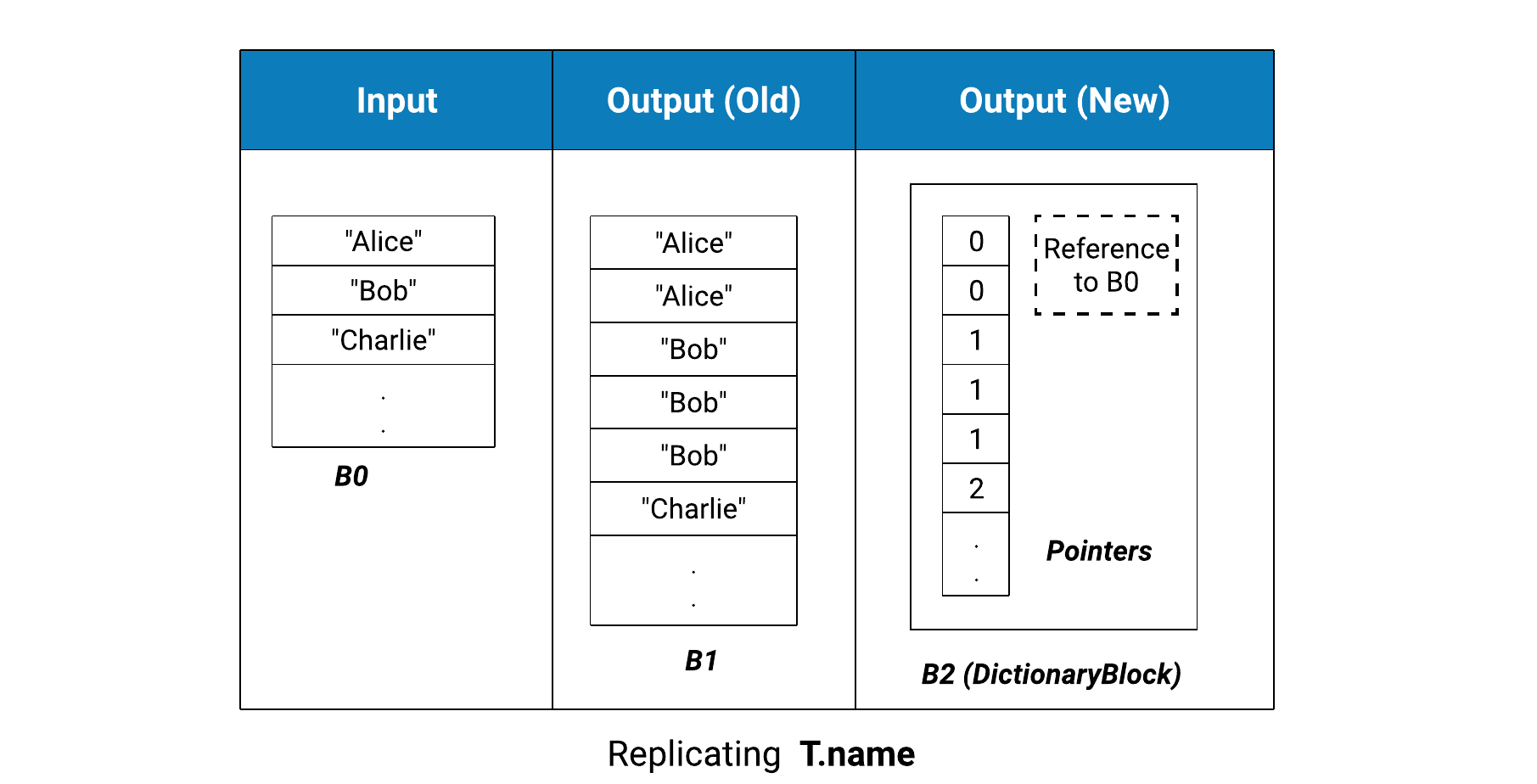
Unnest columns are handled the same way. The previous design would copy them over one by one. This becomes CPU intensive and requires new memory allocations, especially in case of deeply nested columns, since a deep copy is required. In the new design, we try to use pointers instead of copies in most of the cases. The following figure shows the output block structure of the unnested_positions column in the query above, for the old and the new implementation.
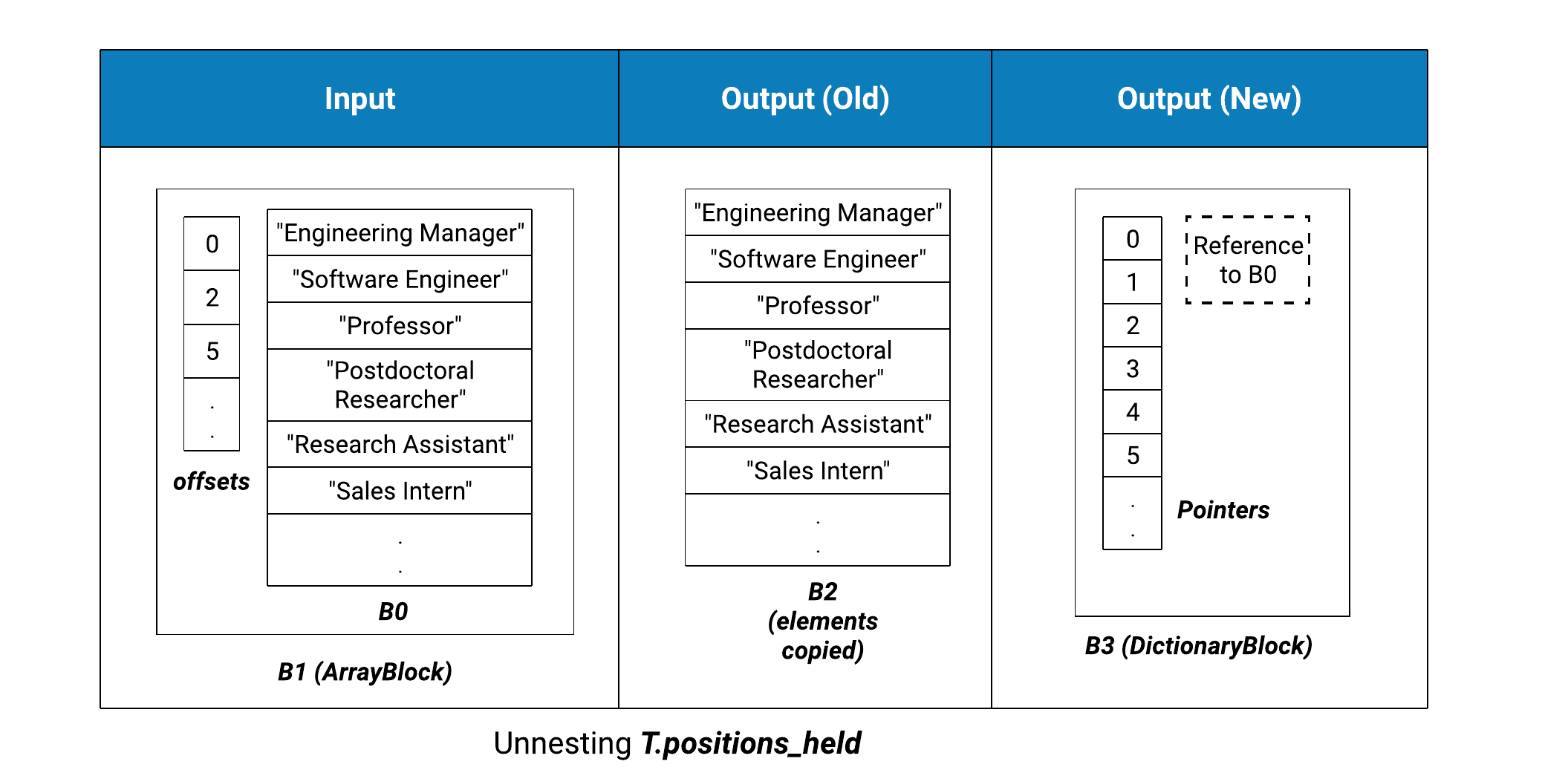
The indices in the output block B3 shown above are strictly increasing starting from 0, but that is not always the case. The same input block can be used to generate multiple output blocks, with a different set of indices. Another interesting scenario is when multiple columns are being unnested. In that case, the output may require null appends because of the difference in cardinalities. We look for null elements in the input block and use their indices for handling the null-appends. If that is not possible, we have to fall back to copying data. We discuss this in more detail in the next section.
Implementation Challenges #
Extracting Input from Nested Blocks #
Data in the input unnest columns is represented in terms of nested structures (eg. ArrayBlock, MapBlock and RowBlock), which creates a layer of indirection on top of the actual element blocks. For the positions_held column from the example above, the input block is an ArrayBlock, that contains:
- offset information for representing arrays in every row
- actual data in the form of an underlying element block storing
VARCHARs.
For building an output DictionaryBlock, we create pointers to this underlying block. While processing entries from input array block, array offsets are translated to indices of the underlying block. Similar translation has been implemented for unnest columns with array type, map type and array of row type. ColumnarMap, ColumnarArray and ColumnarRow structures are used for enabling such translation of indices.
Dealing with Multiple Unnest Columns #
When there are more than one nested columns in a table, a user may want to unnest multiple columns in the same query. Consider a table S with 3 columns: name, schools_attended and graduation_dates. They have VARCHAR, ARRAY(VARCHAR) and ARRAY(VARCHAR) types respectively. Every row in this table indicates schools attended and corresponding graduation dates for a person. Let’s say a user wants to unnest the contents of the two array columns into unnested_school and unnested_graduation_date.
One naive way of doing that is using the CROSS JOIN UNNEST clause twice, on the two different columns. This translates to two different UNNEST operators (as shown in the query below) with a single unnest column producing two independent cross joins, and the execution will proceed the way we discussed earlier. This query structure is not very helpful, since we get blown up cross joined data.
SELECT S.name, U1.unnested_school, U2.unnested_graduation_date
FROM S
CROSS JOIN UNNEST(schools_attended) AS U1(unnested_school)
CROSS JOIN UNNEST(graduation_dates) AS U2(unnested_graduation_date)
The correct way of unnesting the two columns is using them in the same unnest clause, as shown below.
SELECT S.name, U.unnested_school, U.unnested_graduation_date
FROM T
CROSS JOIN UNNEST(schools_attended, graduation_dates) AS U(unnested_school, unnested_graduation_date)
The arrays/maps being unnested in multiple columns can have different cardinalities. In this example, the graduation_date value for the last school may not be present, if the user has not yet graduated. Null elements need to be appended to the output unnest columns in such cases.
In the example data shown below, a NULL element is appended in the unnested_graduation_date column since the array in graduation_dates column is shorter than that in the schools_attended column.
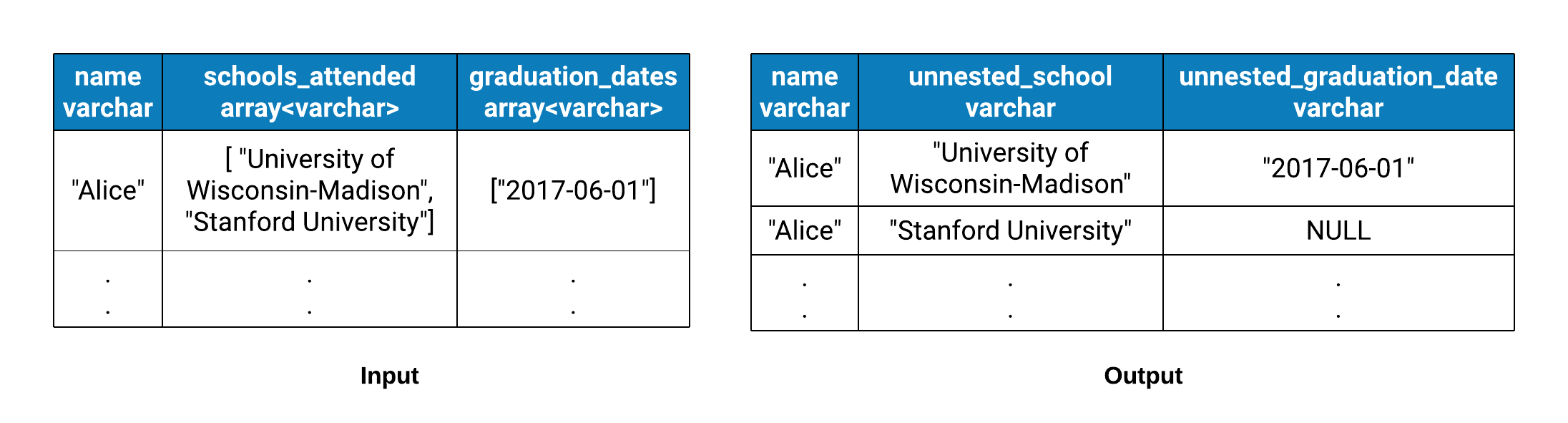
Since we are using a DictionaryBlock for building the unnest output column, appending a null gets slightly tricky. How do we create a pointer for representing a NULL? The DictionaryBlock implementation, as of now, does not have a way to represent null elements. In such cases, we first check for existence of a null element in the input block. If we find a NULL element there, we use the index of that element while appending NULLs in the output. Otherwise we copy elements from the input to create a new output block, like we used to do in the previous implementation.
In cases with multiple columns, the length of arrays/maps are usually the same, and misalignments are not that frequent. Having said that, misalignments can result in copying of data while building output blocks if NULL elements are not present in the input. This may reduce the CPU and memory savings (even increase the average memory allocation in some cases), but this specific case is not common.
Future Work #
Performance for the queries with CROSS JOIN UNNEST clause can be further improved through the following optimizations.
- While unnesting a deeply nested column of type
array(row(.....)), the user is often interested in a small subset of fields from the row. Such cases can benefit from optimization of the logical plan through the pushdown of dereference projections. There are ongoing efforts in the community in this direction.
- The dictionary blocks created in the discussed implementation use the input block as a reference. What happens if the input itself is a
DictionaryBlock? We end up with two levels of dereferencing. Such cases can be further optimized by collapsing the multiple indirections into a single one.
- The common case for unnest column does not involve any NULL appends. The unnested output
DictionaryBlockin this case represents a range over the input block. We can avoid theDictionaryBlockcreation by using thegetRegionmethod on the input block.
- For variable-width and complex columns, usage of
DictionaryBlockcan be beneficial in terms of CPU and memory. This may be overkill for primitive types (booleans or integers) and we might be better off copying rather than creating a dictionary block. Selectively choosing to use dictionary blocks based on the type can be helpful.
Conclusion #
LinkedIn’s data ecosystem makes heavy use of tables with deeply nested columns, and this change is beneficial for handling Presto queries on such tables. In our internal experiments with production data, we have seen queries perform up to ~9x faster with as much as ~13x less cpu usage.
We look forward to people in the community trying this out starting with the 316 release. We would love to hear others’ observations of performance after this change. Feel free to reach out to me over slack (handle @padesai) or LinkedIn with questions or feedback.