Star-schema is one of the most widely used data mart patterns.
The star schema consists of fact tables (usually partitioned) and dimension tables,
which are used to filter rows from fact tables.
Consider the following query which captures a common pattern of a fact table store_sales partitioned by the column
ss_sold_date_sk joined with a filtered dimension table date_dim:
SELECT COUNT(*) FROM
store_sales JOIN date_dim ON store_sales.ss_sold_date_sk = date_dim.d_date_sk
WHERE d_following_holiday='Y' AND d_year = 2000;
Without dynamic filtering, Presto will push predicates for the dimension table to the table scan on date_dim but
it will scan all the data in the fact table since there are no filters on store_sales in the query.
The join operator will end up throwing away most of the probe-side rows as the join criteria is highly selective.
The current implementation of dynamic filtering improves
on this, however it is limited only to broadcast joins on tables stored in ORC or Parquet format.
Additionally, it does not take advantage of the layout of partitioned Hive tables.
With dynamic partition pruning, which extends the current implementation of dynamic filtering, every worker node collects
values eligible for the join from date_dim.d_date_sk column and passes it to the coordinator.
Coordinator can then skip processing of the partitions of store_sales which don’t meet the join criteria.
This greatly reduces the amount of data scanned from store_sales table by worker nodes.
This optimization is applicable to any storage format and to both broadcast and partitioned join.
Design considerations #
This optimization requires dynamic filters collected by worker nodes to be communicated to the coordinator over the network. We needed to ensure that this additional communication overhead does not overload the coordinator. This was achieved by packing dynamic filters into Presto’s existing framework for sending status updates from worker to coordinator.
DynamicFilterService
was added on the coordinator node to perform dynamic filter collection asynchronously.
Queries registered with this service can request dynamic filters while scheduling splits without blocking any operations.
This service is also responsible for ensuring that all the build-side tasks of a join stage have completed execution before
constructing dynamic filters to be used in the scheduling of probe-side table scans by the coordinator.
Implementation #
For identifying opportunities for dynamic filtering in the logical plan, we rely on the implementation added in
#91. Dynamic filters are modeled as FunctionCall expressions which
evaluate to a boolean value. They are created in the PredicatePushDown optimizer rule from the equi-join clauses of inner join
nodes and pushed down in the plan along with other predicates. Dynamic filters are added to the plan after the cost-based
optimization rules. This ensures that dynamic filters do not interfere with cost estimation and join reordering.
The PredicatePushDown rule can end up pushing dynamic filters to unsupported places in the plan via inferencing.
This was solved by adding the
RemoveUnsupportedDynamicFilters
optimizer rule which is responsible for ensuring that:
- Dynamic filters are present only directly above a
TableScannode and only if the subtree is on the probe side of some downstreamJoinNode - Dynamic filters are removed from
JoinNodeif there is no consumer for it on its probe side subtree.
We also run DynamicFiltersChecker
at the end of the planning phase to ensure that the above conditions have been satisfied by the optimized plan.
We reuse the existing DynamicFilterSourceOperator
in LocalExecutionPlanner to collect build-side values from each inner join on each worker node. In addition to passing the collected TupleDomain
to LocalDynamicFiltersCollector
within the same worker node for use in broadcast join probe-side scans, we also pass them to TaskContext to populate task
status updates for the coordinator.
ContinuousTaskStatusFetcher on the coordinator node pulls task status updates from all worker nodes up to every
task.status-refresh-max-wait seconds (default is 1 second) or less (if task status changes). DynamicFilterService
on the coordinator regularly polls for dynamic filters from task status updates through SqlQueryExecution and provides
an interface to supply dynamic filters when they are ready. The ConnectorSplitManager#getSplits API has been updated to
optionally utilize dynamic filters supplied by the DynamicFilterService.
In the Hive connector, BackgroundHiveSplitLoader can apply dynamic filtering by either completely skipping the listing
of files within a partition, or by avoiding the creation of splits within a loaded partition if the dynamic filters
become available in InternalHiveSplitFactory#createInternalHiveSplit due to lazy enumeration of splits.
Benchmarks #
We ran TPC-DS queries on 5 worker nodes cluster of r4.8xlarge machines using data stored in ORC format. TPC-DS tables were partitioned as:
catalog_returnsoncr_returned_date_skcatalog_salesoncs_sold_date_skstore_returnsonsr_returned_date_skstore_salesonss_sold_date_skweb_returnsonwr_returned_date_skweb_salesonws_sold_date_sk
The following queries ran faster by more than 20% with dynamic partition pruning (measuring the elapsed time in seconds, CPU time in minutes and Data read in MB).
| Query | Baseline elapsed | Dynamic partition pruning elapsed | Baseline CPU | Dynamic partition pruning CPU | Baseline data read | Dynamic partition pruning data read |
|---|---|---|---|---|---|---|
| q01 | 10.96 | 8.50 | 10.2 | 8.9 | 17.91 | 14.53 |
| q04 | 21.63 | 10.80 | 23.6 | 16.1 | 34.81 | 12.99 |
| q05 | 41.38 | 14.94 | 57.1 | 16.8 | 54.81 | 11.45 |
| q07 | 12.35 | 9.26 | 26.4 | 14.6 | 30.28 | 17.31 |
| q08 | 10.48 | 6.43 | 11.0 | 4.7 | 10.19 | 3.52 |
| q11 | 20.04 | 14.82 | 35.6 | 27.8 | 25.37 | 9.72 |
| q17 | 24.05 | 9.87 | 26.4 | 12.0 | 30.18 | 9.75 |
| q18 | 13.98 | 6.00 | 17.5 | 7.7 | 20.29 | 8.81 |
| q25 | 18.91 | 8.04 | 26.9 | 9.1 | 37.54 | 11.12 |
| q27 | 11.98 | 5.58 | 25.1 | 8.6 | 26.69 | 10.12 |
| q29 | 24.11 | 15.46 | 30.5 | 18.5 | 30.18 | 13.50 |
| q31 | 27.81 | 12.77 | 48.2 | 21.3 | 39.53 | 13.73 |
| q32 | 11.51 | 8.15 | 12.7 | 10.3 | 15.05 | 12.76 |
| q33 | 15.95 | 4.31 | 24.3 | 5.4 | 31.26 | 6.67 |
| q35 | 15.10 | 5.22 | 13.8 | 6.2 | 4.83 | 1.70 |
| q36 | 11.68 | 6.43 | 22.4 | 11.4 | 24.28 | 12.78 |
| q38 | 21.08 | 16.20 | 39.4 | 31.6 | 5.65 | 3.15 |
| q40 | 37.40 | 11.98 | 37.7 | 8.4 | 17.02 | 9.20 |
| q46 | 11.57 | 9.06 | 24.4 | 17.3 | 18.51 | 14.19 |
| q48 | 20.48 | 12.65 | 42.3 | 22.5 | 20.71 | 11.54 |
| q49 | 26.69 | 16.01 | 38.8 | 12.0 | 68.67 | 30.57 |
| q50 | 46.90 | 33.22 | 43.4 | 42.5 | 21.30 | 16.77 |
| q54 | 43.05 | 11.39 | 27.5 | 14.8 | 17.71 | 11.52 |
| q56 | 16.23 | 4.12 | 23.8 | 5.5 | 31.26 | 6.72 |
| q60 | 16.39 | 6.02 | 25.1 | 6.6 | 31.26 | 7.42 |
| q61 | 17.18 | 5.50 | 33.4 | 7.1 | 42.63 | 9.37 |
| q66 | 13.67 | 6.59 | 19.1 | 8.9 | 19.63 | 8.34 |
| q69 | 9.89 | 7.46 | 10.5 | 6.1 | 4.83 | 3.16 |
| q71 | 17.32 | 6.11 | 23.3 | 6.6 | 31.26 | 8.06 |
| q74 | 16.86 | 9.44 | 24.1 | 17.6 | 22.59 | 8.08 |
| q75 | 122.04 | 69.45 | 102.7 | 62.9 | 110.86 | 63.91 |
| q77 | 23.94 | 7.51 | 29.3 | 6.8 | 49.95 | 12.20 |
| q80 | 43.46 | 18.57 | 45.8 | 11.5 | 37.25 | 11.78 |
| q85 | 20.97 | 16.54 | 16.9 | 14.7 | 14.65 | 10.52 |
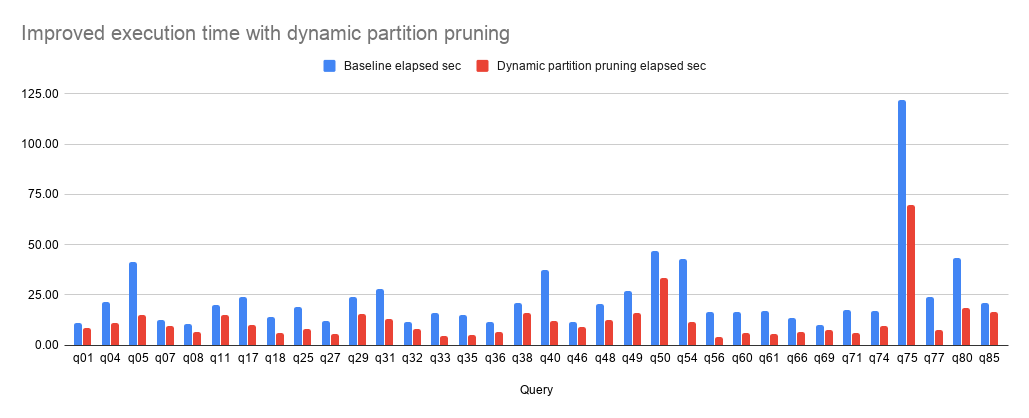
- 18 TPC-DS queries improved runtime by over 50% while decreasing CPU usage by an average of 64%. Data read was decreased by 66%.
- 7 TPC-DS queries improved between 30% to 50% while decreasing CPU usage by an average of 47%. Data read was decreased by 54%.
- 29 TPC-DS queries improved by 10% to 30% while decreasing CPU by an average of 20%. Data read was decreased by 27%.
Note that the baseline here includes the improvements from the existing node local dynamic filtering implementation.
Discussion #
In order for dynamic filtering to work, the smaller dimension table needs to be chosen as a join’s build side. Cost-based optimizer can automatically do this using table statistics from the metastore. Therefore, we generated table statistics prior to running this benchmark and rely on the CBO to correctly choose the smaller table on the build side of join.
It is quite common for large fact tables to be partitioned by dimensions like time.
Queries joining such tables with filtered dimension tables benefit significantly from dynamic partition pruning.
This optimization is applicable to partitioned Hive tables stored in any data format.
It also works with both broadcast and partitioned joins. Other connectors can easily take advantage of dynamic filters
by implementing the new ConnectorSplitManager#getSplits API which supplies dynamic filters to the connector.
Future work #
- Support for using min-max range in DynamicFilterSourceOperator when the build-side contains too many values.
- Passing dynamic filters back to the worker nodes from coordinator to allow ORC and Parquet readers to use dynamic filters with partitioned joins.
- Allow connectors to block probe-side scan until dynamic filters are ready.
- Support dynamic filtering with inequality operators
- Support for semi-joins
- Take advantage of dynamic filters in connectors other than Hive.