
It’s that time of the year where everyone gives excessively broad or niche predictions about the finance market, venture capital, or even the data industry. And we are now bombarded with “year-in-review” summaries where we find out just how much data is being collected to generate those summaries. End-of-year reflections are always useful because you can find patterns of what’s going well and what’s going poorly. It’s also good to pause and take stock of the things that did go well, because without that, you’ll only be looking at the list of things that you still have to do, and that isn’t healthy for anybody. In that spirit, let’s reflect on what we’ve been able to accomplish as a community this year, as well as what to look forward to in the next year!
2022 by the numbers #
Let’s take a look at the Trino project’s growth and what happened specifically in the past year:
- 1,031,842 unique visits 🙋to the Trino site
- 116,231 unique blog post views 👩💻 on the Trino site
- 60,296 views 👀 on YouTube
- 5,982 hours watched ⌚on YouTube
- 4,696 new commits 💻 in GitHub
- 2,775 new members 👋 in Slack
- 2,769 new stargazers ⭐ in GitHub
- 2,550 pull requests merged ✅ in GitHub
- 1,465 issues 📝 created in GitHub
- 1,322 new followers 🐦 on Twitter
- 1,068 pull requests closed ❌ in GitHub
- 702 new subscribers 📺 in YouTube
- 658 average weekly members 💬 in Slack
- 56 videos 🎥 uploaded to YouTube
- 37 Trino 🚀 releases
- 36 blog ✍️ posts
- 12 Trino Community Broadcast ▶️ episodes
- 12 Trino 🍕 meetups
- 2 Trino ⛰️ Summits
The Trino website got an impressive number of unique visits, also referred to as entrances. This metric filters out refreshes and through traffic to count the number of times a visitor started a unique session. Blog posts saw a 47 percent increase from last year. Slack membership grew 13 percent and average weekly active members grew an exciting 25 percent. YouTube views have increased by 218 percent. We’ve more than doubled the number of hours watched, which makes sense, as we’ve nearly doubled the number of subscribers since last year.
The project’s velocity hasn’t slowed down either. The number of commits grew 27.6 percent this year and the number of created issues grew by 20 percent. This increase in demand for features also pushed up merged pull requests numbers by nearly 29 percent!
Why are we pointing out the number of closed pull requests that weren’t merged? We are improving communication with contributors regarding when and why we explicitly decide not to move forward with a pull request. Part of this has included a new initiative to close out old and inactive pull requests. There have been a good number of pull requests that have fallen through the cracks and are missing communication from the pull request creator or reviewer. The DevRel team, Brian Olsen, Cole Bowden, and Manfred Moser, are actively working on improving the workflow around pull requests and issues. Cole recently posted a blog that dives deeper into what this team is actively working on to improve the experience of contributing to the project.
Trino is trending #
A lot of these metrics indicate the growing popularity of Trino, but they also help drive further awareness of the project to others. One metric we pay close attention to is the number of visitors we get through blog posts, as they grow Trino’s visibility. This increases the number of contributors and users that shape Trino to be the best analytics SQL query engine on the planet. One of our most successful blog posts was Why leaving Facebook/Meta was the best thing we could do for the Trino Community. The day this blog post was released, it doubled the website traffic we received and set the record for blog post views or website views in a single day. For reference, our previous record was the post we had when the project was rebranded.
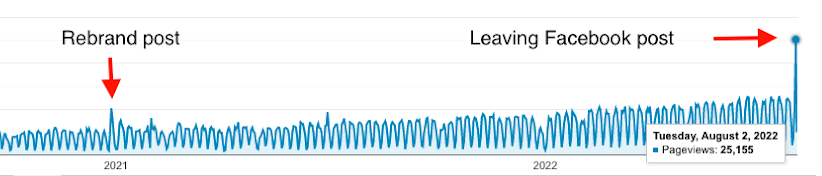
This post gained a lot of traction for two reasons. Posts related to Meta and the inner workings of open source communities naturally perform well, as many developers are interested in these topics - drama is exciting! But you can have an interesting topic that doesn’t go viral if nobody sees it. The catalyst to this success was actually when David Phillips posted this to Hacker News. We hit the top ten of Hacker News and occupied the front page for about two days.
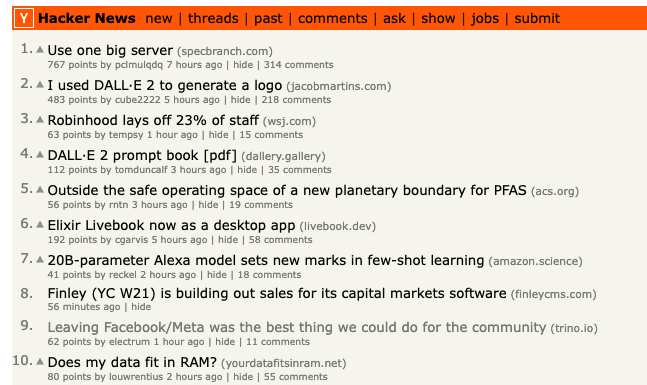
So what is the takeaway here? We need your help! While it made sense for David to do this post once, Hacker News generally looks down upon repeated self-promotion. Clearly there’s a lot of people interested in Trino, and Hacker News and many other social media outlets are how we get the word out. If you don’t think that sharing has much effect, we hope sharing this impact motivates you to help us. We don’t want to keep Trino the hidden secret of Silicon Valley much longer. We need your help to really get people continuously reading and hearing about all things Trino. So share any time you see something cool going on in our community!
Trino touches the world #
Let’s take a look at the number of users who have initiated at least one session on the Trino site in 2022 by top 10 countries. This goes to show the true global reach this project has attained in 10 years.
- 123,326 USA 🇺🇸users
- 33,540 Indian 🇮🇳users
- 30,955 Chinese 🇨🇳users
- 12,282 British 🇬🇧users
- 11,638 German 🇩🇪users
- 10,760 Canadian 🇨🇦 users
- 9,980 Brazilian 🇧🇷users
- 9,098 Singaporean 🇸🇬users
- 8,649 South Korean 🇰🇷users
- 8,636 Japanese 🇯🇵users
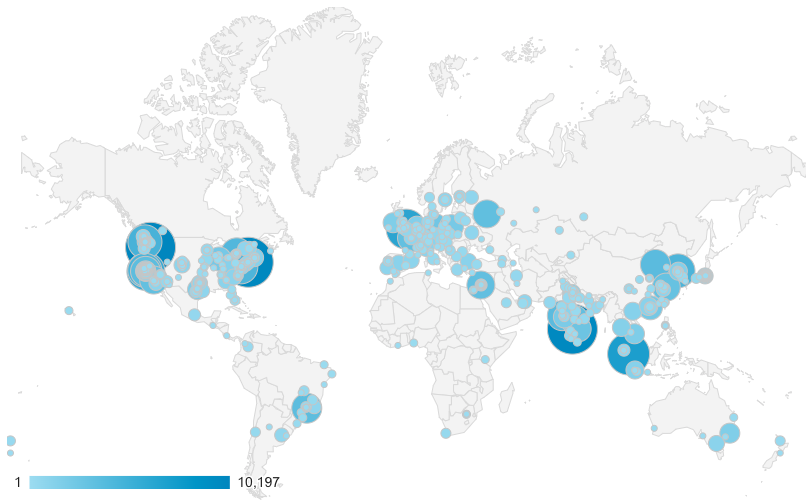
Our reach currently favors the USA, but our aim is to grow Trino in all countries that are starting to show interest. The new edition of “Trino: The Definitive Guide” is being translated into Chinese, Polish, and Japanese. If you want to translate the book to your local language, please reach out to Manfred Moser.
Trino celebrates its tenth birthday #
Of all the incredible things that happened, one that gave us cause to reflect was Trino’s tenth birthday. Martin, Dain, and David cite longevity of the project as one of the core philosophies that govern decisions around Trino. We expect that Trino will be used for at least the next 20 years. We build for the long term. This first decade has been an adventurous ride, and wow has it produced an incredible system.

We wanted to do something special with the community to celebrate this milestone, so Brian put together a birthday video to timeline the evolution of Presto and now Trino. We had a premiere watch party on the day of the tenth anniversary and got some folks’ reactions. Take a look at the video if you haven’t yet, you don’t want to miss it.
Trino Summit #
The next event in 2022 was the Trino Summit, which was the first in-person summit we’ve had as Trino, with well over 750 attendees. We had a stellar lineup of speakers from companies like Apple, Astronomer, Bloomberg, Comcast, Goldman Sachs, Lyft, Quora, Shopify, Upsolver, and Zillow.
This summit had a Pokémon theme, making the analogy that data sources are much like Pokémon and Trino is much like a Pokémon trainer trying to access and federate all the data, train it, and level the data up. Check out the video for a small summary, and if you missed this event, we have all the recordings and slides available.
We want to thank Starburst for hosting this event and all the sponsors for making this year’s summit possible. As usual, a huge thanks to the community for showing up, engaging with each other, and bringing your stories and curiosity.
Cinco de Trino #
Cinco de Trino was our mini Trino Summit held in the first half of the year. It dove into using Trino with complementary tools to build a data lakehouse. The virtual event was held on Cinco de Mayo (5th of May), which gave it a Margaritaville, on-the-lake vibe. We used this conference as a platform to launch the long-awaited Project Tardigrade features around the fault-tolerance mode for Trino.
Trino Contributor Congregation #
This year, we began what we are calling the Trino Contributor Congregation (TCC), which brings together Trino contributors, maintainers, and developer relations under the same roof. This congregation was to counter the siloed nature of Trino development that occurred during the pandemic. Many community members felt like their work wasn’t being seen and much of this was due to lack of communication, and especially face-to-face communication, which builds empathy and demands attention. The TCCs aim to increase connections and collaboration between maintainers and contributors, create opportunities for highly technical exchange of ideas and plans for Trino, and learn about usage scenarios and issues from each other. This is different from the Trino Summit since it focuses on gathering those who contribute code to keep the conversations focused on developing features and removing blockers for contributors.
The first TCC happened just following Trino Summit in Palo Alto. This was convenient for many, as a lot of folks were already in San Francisco to attend Trino Summit. Moving forward we will continue having in-person TCCs around Trino Summit to minimize the travel expected for anyone wanting to attend in-person TCCs.

Along with the in-person TCC, we also had the first virtual TCC in December. This included a great deal of people in Eurasia who weren’t able to travel to San Francisco in November. We covered mostly similar topics but with a larger amount of interaction from those new voices.
During these discussions the biggest topics covered timelines of existing roadmap items and suggestions for other items that should get more attention. We talked about upcoming connectors and plugins, and all the required infrastructure needed to support that. A recurring theme was the need for better testing infrastructure. The more information we can gather as a community, the quicker we can remove any issues as new releases come out and increase adoption of newer versions of Trino. We also discussed desired features around resource-intensive and batch workloads, and the new polymorphic table function features.
The biggest takeaway from these meetings was that everyone now had a better basis to engage with each other. As we move forward, we will continue the cadence of having these virtual TCCs to keep everyone on the same page, and have in-person meetings when there is a larger conference. With that, let’s cover some of the features we gained this year.
Features #
Of course, one of the main deliverables of our project are Trino releases. In 2022, we improved our release process and cadence, shipping 37 releases that were packed with features, and we’re about to dive into a high-level list of the most exciting ones that made their way to you. For details and to keep up you can check out the release notes.
Fault-tolerant execution mode #
2022 was the year of resiliency for Trino. Users have long requested adding a fault-tolerant mechanism to Trino akin to query engines like Apache Spark. Users wanted the ability to take the queries that they were running in Trino and scale those queries to larger data or resource intensive queries. Experimental features were implemented in late 2021 for automatic query retries and earlier this year task-level retries. The efforts for these features were codenamed Project Tardigrade.
Fault-tolerant execution relies on storing intermediate data between task shuffles to have data persist in an exchange spool. The first iteration of this was AWS S3, but eventually Azure Blob Storage and Google Cloud Storage were included. The Project Tardigrade engineers started improving performance and fixing bugs in fault-tolerant execution as users tested the early implementation. Later, memory efficiency for aggregations, faster data transfers, and dynamic filtering with fault-tolerant query execution were added. The launch of fault-tolerant execution happened at Cinco de Trino. The first iterations only applied to queries being run on object-storage connectors such as Hive, Iceberg, and Delta Lake. Recently, support for MySQL, PostgreSQL, and SQL Server were added. These contributions added a foundation for other JDBC connectors. A few companies, most notably Lyft, have adopted this feature and are scaling it in production.
SQL language improvements #
Here are all the notable SQL features that made it to Trino this year:
MERGEstatement support is the most impactful SQL feature released this year.MERGEallows users to implementINSERT,UPDATE, andDELETEfunctionality in one statement.MERGEis not simply syntax sugar, the implementation has profound performance improvements. A lot of your operations can be merged (pun intended) from multiple tasks into a single scan over data. This functionality is absolutely critical for positioning Trino as a data lakehouse query engine.MERGEis currently available in the Hive, Iceberg, Delta Lake, Kudu, and Raptor connectors. We discussed this and did a demo withMERGEon the recent Trino Community Broadcast with Iceberg.- Another massive update was the introduction of polymorphic table functions ( PTFs). Table functions initially released with some initial passthrough query functionality that we see in connectors like Pinot, Elasticsearch, MySQL, PostgreSQL, and other JDBC connectors. However, this is only one small instance of what can be achieved with PTFs and the true power comes from the generalization of this feature. Dain and David gave a simpler explanation of PTFs. To dive in deeper, watch this episode of the Trino Community Broadcast where Kasia Findeisen and Martin discuss PTFs in greater detail.
- Dynamic function resolution has been discussed for many years and finally arrived. This provides the ability for connectors to provide functions at runtime. Unlike before, where you needed to statically register your functions ahead of time, you can now provide a plugin that contains these functions that are resolved at runtime. This enables features like supporting function calls to dynamically registered user-defined functions in different languages like Javascript or Python. Martin and Dain go into great detail about how this works when answering this question at Trino Summit.
- Trino gained support for JSON processing functions, which is a part of the ANSI SQL 2016 specification. This resolves a large number of issues reported by the community over the years. This includes the json_array, json_object, json_exists, json_query, and json_value functions that were added to Trino this year.
- The JSON format was added to the
EXPLAINstatement to provide an anonymized query plan output to enable offline analysis. - It became possible to comment on tables, columns of tables, and even views for various connectors. Support for setting comments on views was introduced very recently and includes support for Hive and Iceberg.
- A ton of new functions were added, including
to_base32,from_base32,trim_array, andtrim.
Performance improvements #
Despite all the hype about vectorization being a silver bullet to make databases go fast, the real speed comes from better algorithms and better data structures that lead to lower resource consumption. Following is a list of some improvements that made their way into Trino this year:
- Trino now offers improved performance for a variety of operations, including complex join criteria pushdown to connectors, faster aggregations, faster joins, and better performance for large clusters. We have also implemented improvements specifically for aggregations with filters and for the Glue metastore. In addition, we now support dynamic filtering for various connectors and have faster query planning for the Hive, Delta Lake, Iceberg, MySQL, PostgreSQL, and SQL Server connectors.
- Along with general performance optimizations, there have been a great deal of
query planning optimizations that lead to better performance for specific SQL
operators. These include faster
INSERTqueries, improved performance forLIKEexpressions and highly selectiveLIMITqueries, and enhanced performance and reliability forINSERTandMERGEoperations. We also made performance improvements forJOIN,UNION, andGROUP BYqueries, as well as faster planning of queries withINpredicates. - There are also optimizations for specific SQL types’ performance, such as
string,
DECIMAL,MAPandROWtypes. We have also made aggregations overDECIMALcolumns faster and improved the performance ofROWtype and aggregation. - A last set of improvements come from reading open file formats like ORC and Parquet efficiently. We have improved the speed of reading or writing of all data types from and to Parquet in general. There were also general performance to ORC types, and now have the ability to write Bloom filters in ORC files. We have also improved performance and efficiency for a wide range of ORC and Parquet-related operations.
These improvements in aggregate are at the core of what makes Trino fast. There is no silver bullet you can plug in to speed things up. It takes time, effort, and smart changes to improve the speed of various systems.
Runtime improvements #
Trino upgraded to Java 17. This upgrade improves the overall speed and lowers the memory footprint of Trino with various performance fixes to the JVM and garbage collectors. Trino uses the G1 garbage collector which can now more efficiently reclaim memory and reduce pause times.
Aside from having to perform the upgrades, we get a lot of these performance enhancements for free. On top of performance, upgrading to Java 17 adds new Java language features to improve the ability to write and maintain higher quality code.
To learn more, read this blog post and watch episode 36 of the Trino Community Broadcast
Along with the Java upgrade, Trino now has a Docker image for ppc64le and added CLI support for ARM64, which means Trino’s Docker image can run on AWS Graviton processors and the image and CLI can run on the new MacBooks.
Security #
Trino added the following improvements and features relevant for authentication, authorization and integration with other security systems:
- There were a lot of updates to OAuth 2.0 authentication like support for OAuth 2.0 refresh tokens and allowing access token passthrough with refresh tokens enabled. We also added support for automatic discovery of OpenID Connect metadata with OAuth 2.0 authentication, support for groups in OAuth2 claims, and reduced latency for OAuth2.0 authentication.
- Hive, Iceberg, and Delta Lake got AWS Security Token Service (STS) credentials for authentication with Glue catalog and allow specifying an AWS role session name via S3 security mapping config.
Object storage connectors (Hive, Iceberg, Delta Lake, Hudi): #
One of the common uses for Trino is being used as a data lakehouse query engine. This year we not only added two connectors to this category, but a lot of performance improvements across the board with the file reader and writer improvements.
- Earlier this year, we added the Delta Lake connector to finally reach everyone using Trino in the Delta Lake community. Delta Lake is a table format that improves on the Hive table format in areas like better support for ACID transactions. After the initial release, we added read and write support on Google Cloud Storage, added support for Databricks 10.4 LTS, and improved overall performance of the connector. To learn more about the Delta Lake connector, watch the Trino Community Broadcast on Delta Lake.
- The Hudi connector is a more recent addition, but it’s just as exciting. Hudi was created at Uber with the goal of handling realtime ingestion to a data lake. This connector is the youngest of the three newest object storage connectors, so stay tuned to see more features land around this connector. See how Robinhood uses Hudi and Trino in the Trino Community Broadcast.
- The Iceberg connector had a massive amount of improvements as well, bringing
it to the same level of a production-ready connector as Hive. Iceberg now has
new
expire_snapshotsanddelete_orphan_filesandOPTIMIZEprocedures. Having these capabilities along withMERGEare really the keys to being an effective lakehouse query engine. This year, Iceberg added support for the Glue metastore, the Avro file format, file-based access control, andUPDATEand time travel syntax. Iceberg received a lot of performance improvements and improvement in latency when querying tables with many files. - Although it seems like Hive is gradually on its way out, there are many that
still depends on the Hive connector to be performant. Hive received support for
S3 Select pushdown for JSON data, IBM Cloud Object Storage in Hive,
improved performance when querying partitioned Hive tables, and the
flush_metadata_cache()procedure for the Hive connector.
Other connectors #
A major feature of Trino is the availability of other connectors to query all sorts of databases with SQL. All with the speed that Trino users are used to. Here’s some of the major improvements that landed for these connectors in 2022:
- New MariaDB connector
- Performance improvements with various pushdowns in the MongoDB, MySQL, Oracle, PostgreSQL and SQL Server connectors.
- Support for bulk data insertion in SQL Server connector.
- Added a query passthrough table function to numerous connectors.
- Expanded SQL features for various connectors by adding support for
TRUNCATE TABLE,DELETE,CREATE/DROPSCHEMA,INSERT, and others. - Update Cassandra connector to support v5 and v6 protocols.
- A collection of improvements on the Pinot and BigQuery connectors
Bug fixes #
Any software includes issues and bugs, Trino included. Thanks to our community we learned about many of them, and fixed even more. Continue to test new releases and report issues. Check out all the release notes for details.
Updates in the Trino ecosystem #
Outside of the excitement within the main Trino project, there was a great deal going on in the larger Trino community and ecosystem:
Trino: The Definitive Guide second edition #
Martin, Manfred, and Matt released the second version of Trino: The Definitive Guide. This update of the book from O’Reilly fixed errata, added the deployment process to include newer Kubernetes installation methods, and updated features for all the additions that had been released since the first version of the book. Along with this, efforts are underway to translate this book to different languages. Huge thanks to everyone involved in this!
Starburst provides Trino in the cloud #
As a major community supporter, Starburst helped us with events, marketing, developer relations, and partner cooperation. Starburst also provided a large part of development and code contributions to Trino and its related projects. Starburst acquired Varada and integrated the object storage indexing technology, and they shipped many Starburst Enterprise releases for self-managed deployments. On top of all that amazing work, Starburst launched Starburst Galaxy as a powerful, multi-cloud SaaS offering of Trino. Security, cluster management, a query editor, and many other features are included in this new platform.
Amazon upgrades Athena #
Athena version three rolled out and is now based on a recent Trino release. This is great news for Athena users who were missing the many performance gains, expanded SQL support, and other features from Trino, since the prior versions are based on old Presto releases. As a result, the large Athena community and their feedback and knowledge have become more integrated with the Trino community, and we are seeing positive impact for Trino releases already.
dbt-trino #
dbt users rejoice! The official dbt-Trino integration made it into dbt this year! This means that anyone who wanted to read or write data to or from multiple data sources is now able to. If you want to dive into it, check out this blog post written by the contributors of this integration.
Python client improvements #
The amount of development of the trino-python-client doubled this year. A major focus was on performance improvements with the sqlalchemy integration. There was also a wide range of bug fixes.
Airflow integration #
The long-awaited Trino/Airflow integration landed this year. This paired well with the new task-retry and fault-tolerant execution features. To learn more about the full capabilities of pairing Trino’s few fault-tolerant execution mode with Airflow, check out Philippe Gagnon’s talk at this year’s Trino Summit.
Metabase driver #
A lot of folks in the community were asking for a Trino/Metabase driver after Trino updated its name. This was a large blocker for anyone who wants to move to Trino and uses Metabase. Through a collaboration of the Metabase and Starburst engineers, the metabase-driver for Trino was released, and we saw numerous users migrate to Trino.
2023 Roadmap #
The upcoming roadmap was covered in detail by Martin at Trino Summit. To avoid extending this blog even further, we’ll leave you with the featured project that covers many aspects of the Trino core engine.
Project Hummingbird #
Project Hummingbird aims to improve Trino’s columnar and vectorized evaluation engine. Every year we report on many incremental performance improvements. These improvements are typically small in isolation but have a large aggregate impact. This incremental approach is the real key to improving query engine performance, and there is always room for further optimization. If you want to get involved with this exciting project, or to learn about the latest innovations as they are being discussed, join the #project-hummingbird channel in the Trino Slack workspace.
Conclusion #
2022 was by far the busiest year this bunny has been. Trino has consistently continued growing as we’ve attracted more contributors. We believe this trend will continue in 2023 as we begin to put more process in place around managing pull requests. Remember to get the word out and share anything you genuinely think is cool or important for others to hear! Looking forward to an even more successful 2023 Trino nation!