Video
- Releases 379 to 381: Details about features and fixes in the new releases (497s)
- Question of the episode: Will Trino be making a vectorized C++ version of Trino workers? (1162s)
- Concept of the episode: Java 17 and rearchitecting Trino (2199s)
- Java 17 updates: Performance (2410s)
- Java 17 updates: Garbage collectors (2805s)
- Java 17 updates: Java auto-vectorization (3982s)
- Java 17 updates: Performance (4328s)
- Java 17 updates: Language features (4634s)
- Rearchitecting Trino: Update to Java 17 (5239s)
- Rearchitecting Trino: Revamping Trino (5556s)
- Rearchitecting Trino: Project Hummingbird (5980s)
- Pull requests of the episode: PR 4649: Disable JIT byte code recompilation cutoffs in default jvm.config (6151s)
- Demo of the episode: FizzBuzz - SIMD style! (6558s)
Audio
Releases 379 to 381
Official highlights from Martin Traverso:
- New MariaDB connector
- Performance improvements for
JOIN,UNION, andGROUP BY - Support for Google Cloud Storage in the Delta Lake connector
- Support for Pinot 0.10
- Update Cassandra connector to support v5 and v6 protocols.
- Rename properties controlling Hive view parsing.
- Allow changing file and table format with the Iceberg connector.
- Add support for bulk data insertion in SQL Server connector.
- Support for
UPDATEin Iceberg connector. - Experimental support for table functions.
- Support for exchange spooling on Azure Blob Storage.
- Support reading snapshot tables and materialized views in BigQuery connector.
Additional highlights worth a mention according to Manfred:
- Next is exchange spooling on Google Cloud Storage.
- Framework for table functions is in place, implementations in connectors are coming.
ldap.ssl-trust-certificateas legacy config removes upgrade failures.- Introduce the
least-wastelow memory task killer policy. - Disable auto-suggestion in CLI
More detailed information is available in the release notes for Trino 379, Trino 380, and Trino 381.
Cinco de Trino recap blog post
Check out this blog post that details all the cool talks that took place at Cinco de Trino and includes video resources. This was a mini version of the Trino Summit which will take place later this year.
Question of the episode: Will Trino be making a vectorized C++ version of Trino workers?
Full question from Trino Slack
Answer: Writing a C++ worker would require each plugin to be implemented in C++ as well. However, you don’t need C++ for vectorization. Java already does a technique called auto-vectorization which we will demonstrate later in the show! Java 17 also introduces the new Vector API which unlocks complex usage patterns that we can invest in moving forward. However, there’s so much more to making operations faster than just bare metal speed that we are going to focus on.
To demonstrate this, I’d like to use an analogy about how I think of this. Comparing C++ and Java implementation is like comparing the two fastest men in the world. Usain Bolt holds the most world records for mens track to this date, and teammate Yohan Blake holds many of the second place titles. Most of us know Usain Bolt is the fastest of the two, and you may not have known or remembered Yohan’s name before. Want to hear something crazy, Yohan has beaten Usain Bolt in a few races. The two are so close in speed, it’s seconds to milliseconds difference. The main difference in this analogy is that speed is the only thing that matters in an olymic race. Howver, programming languages and frameworks have a lot more tradeoffs.

The point is, Java is fast and more importantly, it removes a lot of burden maintaining and scaling out the code. This is conducive to a healthy open-source project, and lowers the barrier for collaboration. Rather than go against this and take on the feat of having to rewrite an entire system in C++, why not lean into the incredible innovation recent Java features have to offer to improve performance even more.
Another important aspect is rather than chasing the fastest bare metal speed, it’s also incredibly important to dedicate time into ensuring that Trino’s optimizer is producing the best possible plans to avoid doing unnecessary work. To continue with the analogy, in a 100m race on a 400m track, imagine we have Usain and Yohan go head to head. We may expect that Usain will likely win, given his track record. However, if Usain is given the wrong instructions and runs in the wrong direction (300m), my bets are that Yohan will win the race.
In essence, the direction of Trino while still including bare metal performance improvements in the JVM, will instead focus on not wasting time with suboptimal query plans before or during runtime. There are so many optimizations that are constantly being added to every release that ultimately makes for a work-smarter-not-harder query engine.
Concept of the episode: Java 17 and rearchitecting Trino
As Trino prepares to update to Java 17, we wanted to give a glimpse at what has happened between the current required JDK version, JDK 11, and future version JDK 17. Both of these versions are long-term support versions, and in the four years from 11 to 17 a lot of exciting improvements were added.
Java 17 updates
Here are some updates coming up in Java 17.
Performance
There were several JDK Enhancement Proposals (JEP) that improve performance as well as many small changes to the JVM:
Performance is a multifaceted topic that includes factors like throughput, latency, memory footprint, startup, ramp up, pause times, and shut down time.
You can used standardized benchmarks like SPECjbb® 2015 to test a Java application in most of these performance factors. Aside from the formalized benchmarks, it’s interesting to see the Java community come up with microbenchmarks to test relative speedups of JVMs on their own applications. This user benchmark found an 8.66% improvement in speed when using hte G1 garbage collector. They isolated modules of their application to measure each microbenchmark separately.
Martin did a similar test late last year, and reported anywhere from 10-15% improvement in speed in Java 17 using the G1 garbage collector. This is an exciting development and we hope to publish more about this as we get closer to updating.
Garbage collectors
Although garbage collectors are performance enhancements in their own right, there is a lot of exciting changes around garbage collectors in Java 17 since Java 11 which earns garbage collectors their own section.
First not one, but two concurrent garbage collectors have made their way out of incubation, and are ready for use.
- JEP 377: ZGC: A Scalable Low-Latency Garbage Collector
- JEP 379: Shenandoah: A Low-Pause-Time Garbage Collector
Aside from that, there are a bunch of big improvements to G1.
- JEP 344: Abortable Mixed Collections for G1
- JEP 345: NUMA-Aware Memory Allocation for G1
- JEP 346: Promptly Return Unused Committed Memory from G1
In a fantastic writeup and benchmark by Stefan Johansson, they ran the SPECjbb® 2015 to evaluate the improvements of different garbage collectors over different LTS versions.
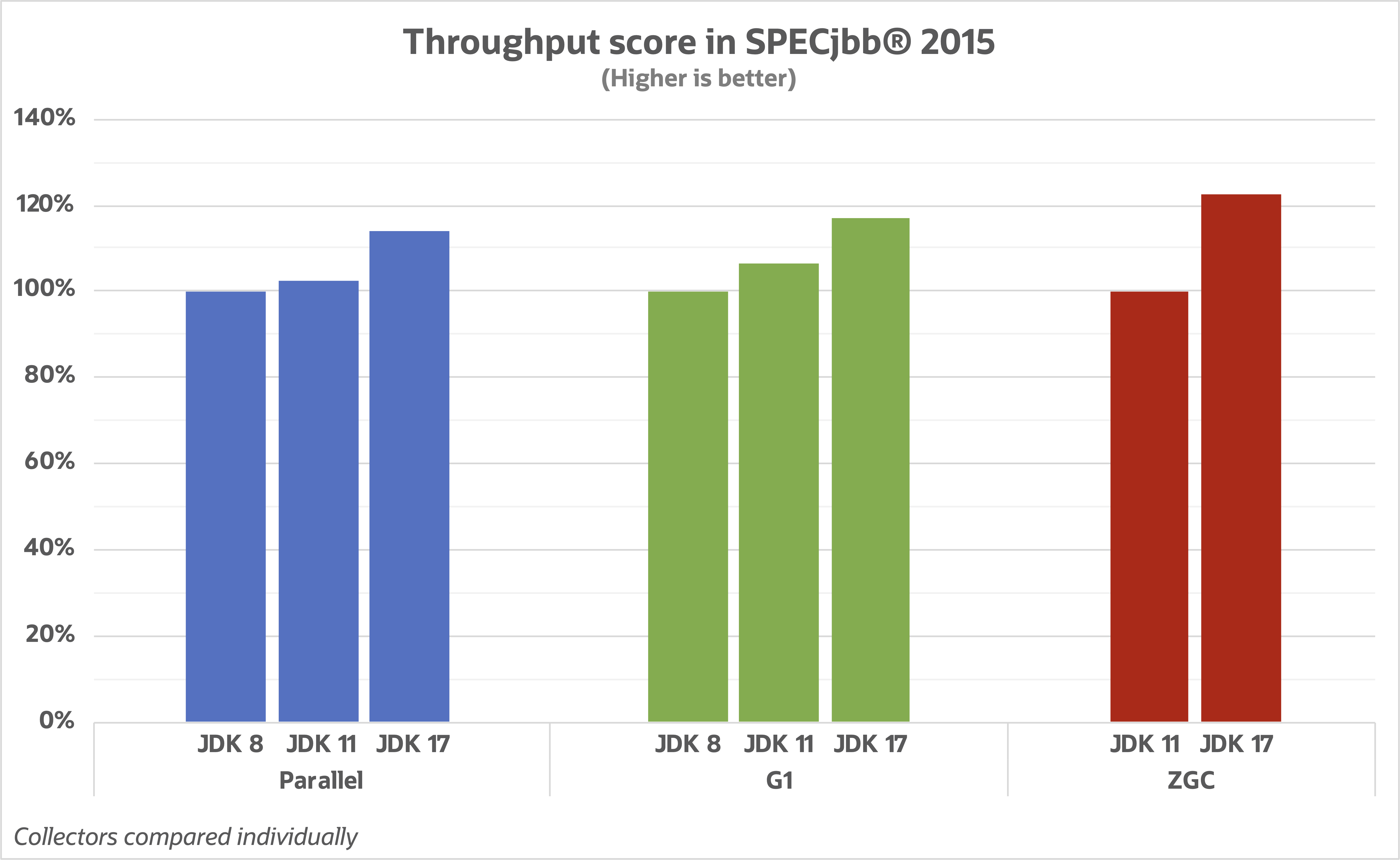
Source: Stefan Johansson's Blog
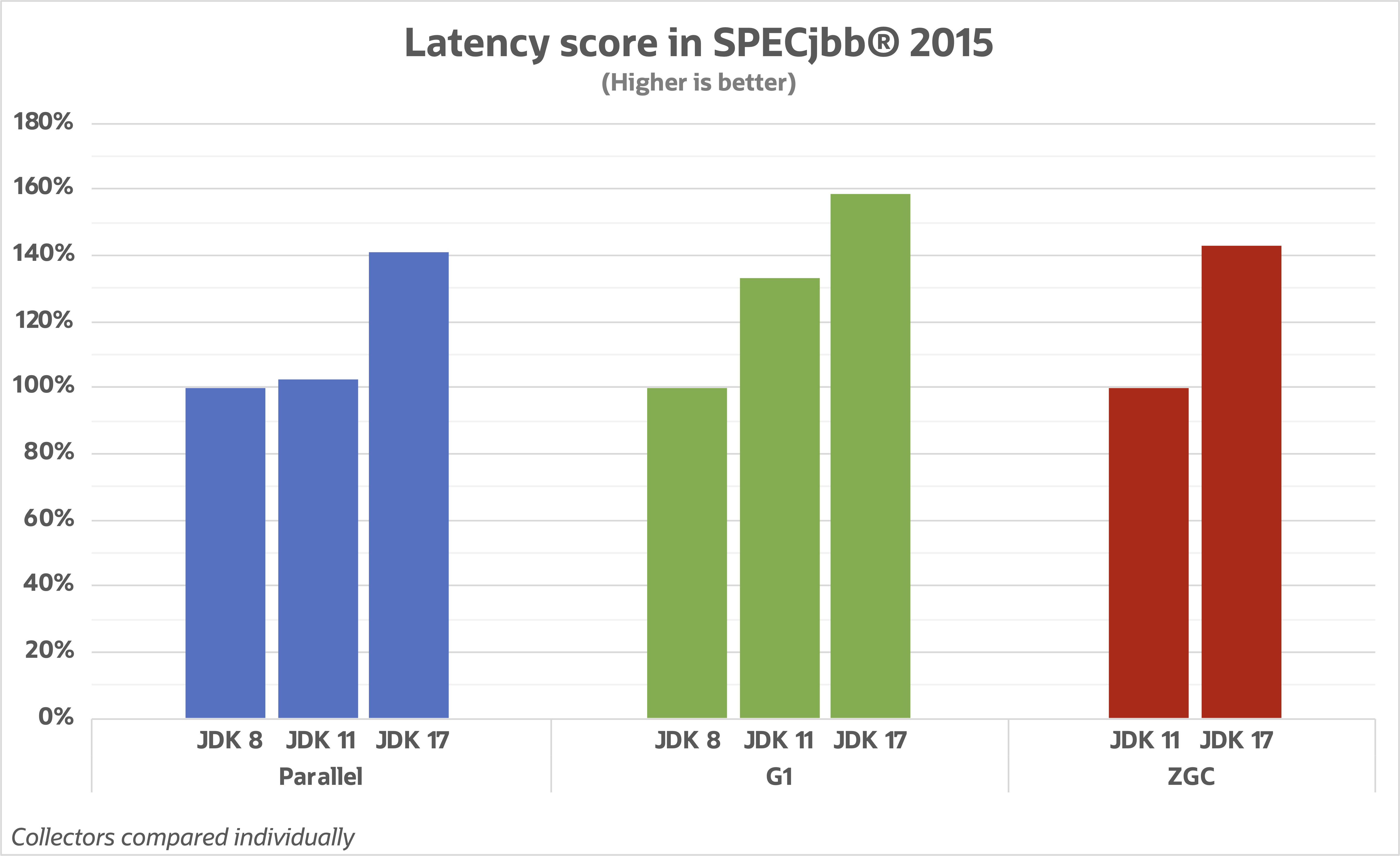
Source: Stefan Johansson's Blog
Pay attention to this chart, as it showcases the advantage of having a concurrent garbage collector like ZGC or Shenandoah that doesn’t interfere with your application code. It’s incredible that 99% of the GC operations only took 0.1ms. Wild!
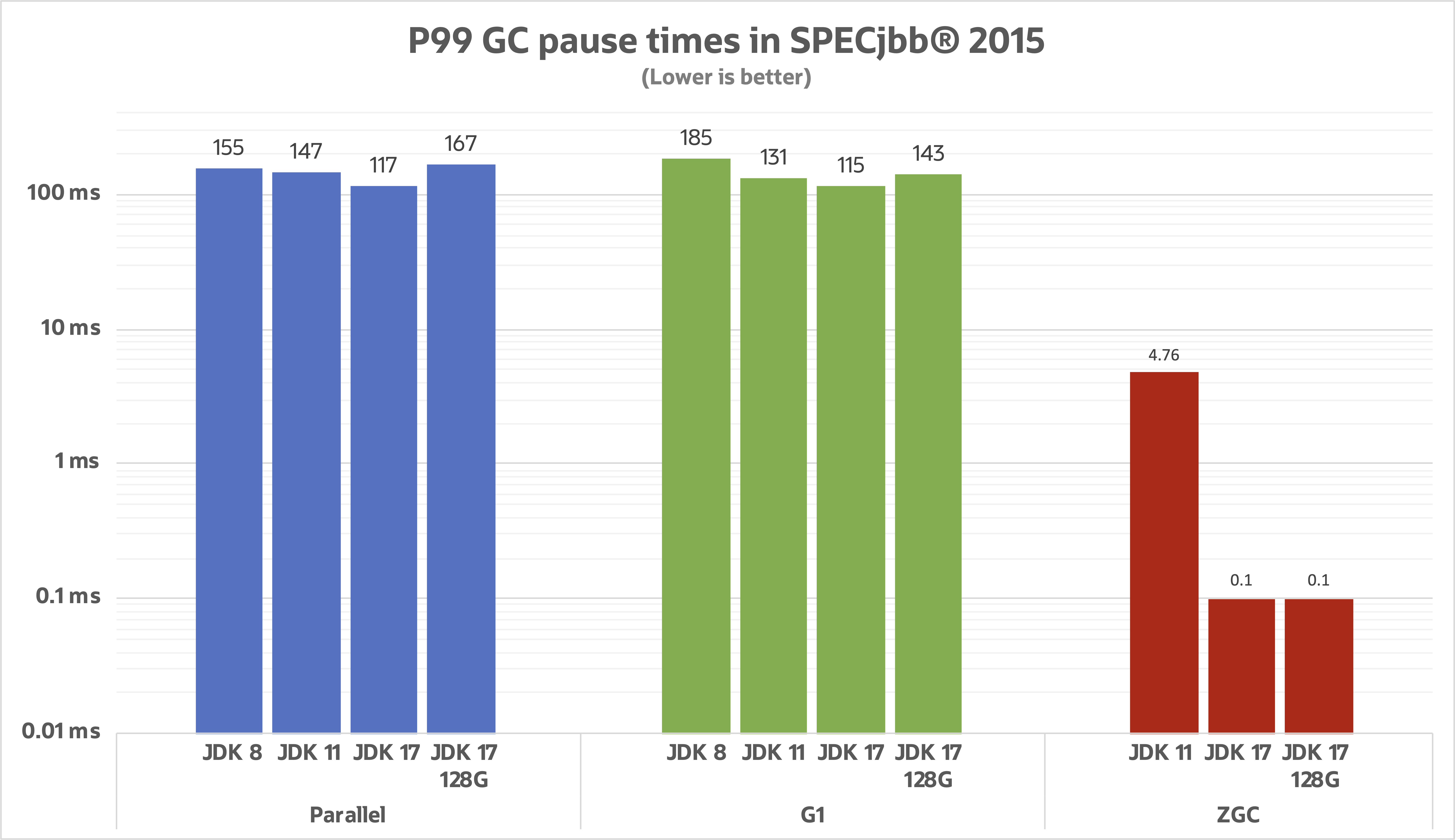
Source: Stefan Johansson's Blog
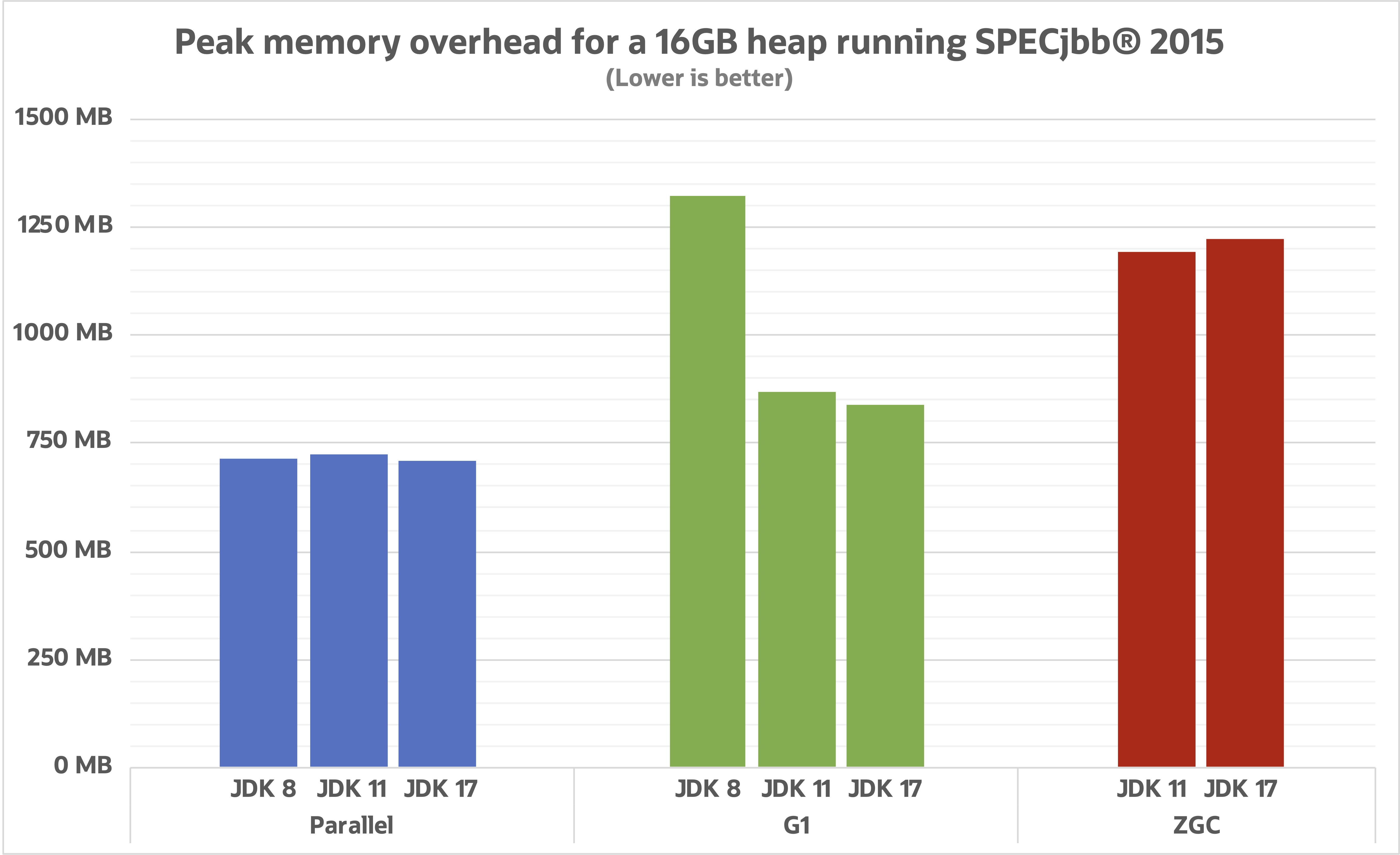
Source: Stefan Johansson's Blog
Take particular note of the massive improvement of G1. This is especially exciting because G1 is recommended for Trino usage. It’s still too early to determine if ZGC or Shenendoah will have overall better performance depending on the context in which the JVM is running. One thing to look forward to is the incredible drop in memory footprint over the different versions!
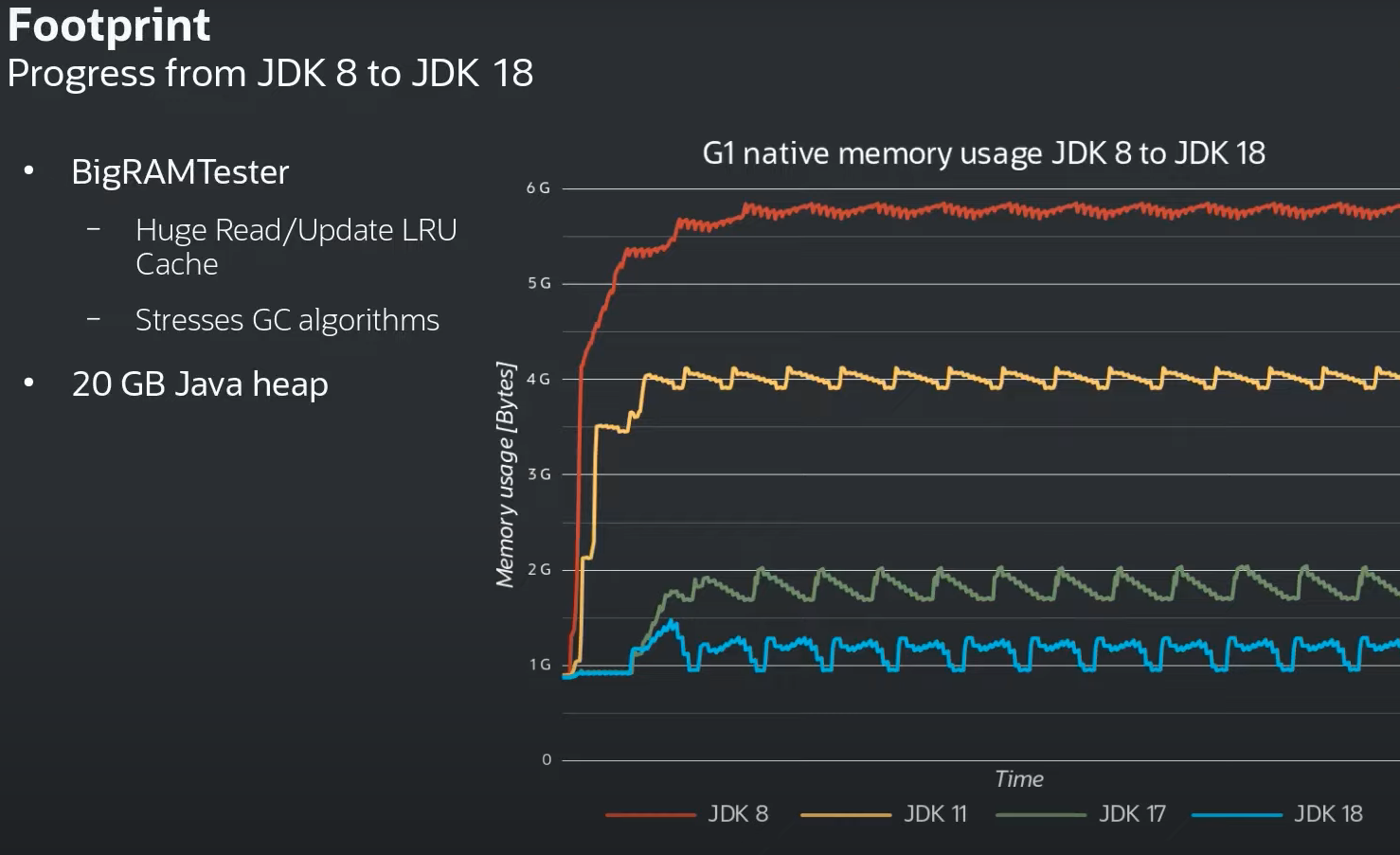
Source: Java YouTube Channel
Vector API (2nd incubator status)
One available capability that is still incubating is the Vector API. Trino currently takes advantage of the auto-vectorization that comes for free when the compiler detects that a loop like this one used from Daniel Strecker’s auto-vectorization blog:
/**
* Run with this command to show native assembly:<br/>
* Java -XX:+UnlockDiagnosticVMOptions
* -XX:CompileCommand=print,VectorizationMicroBenchmark.square
* VectorizationMicroBenchmark
*/
public class VectorizationMicroBenchmark {
private static void square(float[] a) {
for (int i = 0; i < a.length; i++) {
a[i] = a[i] * a[i]; // line 11
}
}
public static void main(String[] args) throws Exception {
float[] a = new float[1024];
// repeatedly invoke the method under test. this
// causes the JIT compiler to optimize the method
for (int i = 0; i < 1000 * 1000; i++) {
square(a);
}
}
}
Without auto-vectorization, a command vmulss (multiply scalar
single-precision) versus with auto-vectorization the vmulps (multiply packed
single-precision) which is a SIMD instruction the JIT compiler updated for us
without manual intervention.
However, this isn’t always so straightforward to detect. As you can see from the comments in the example, special criteria need to be met. For this, you can use the Vector API to directly interface with SIMD and GPU instructions. We will show more on this in the demo.
Language features
Beyond the performance improvements, Java 17 includes some exciting new Java language updates and improvements. While some may not consider this as exciting as performance boosts, language enhancements make it easier to write higher quality and maintainable code. This is especially important for an open source project that is maintained by many individuals.
-
A very useful change for Trino is the new support for multiline text blocks. This allows you to go from having to write a SQL query represented in a one-dimensional string literal like this:
String query = "SELECT \"emp_id\", \"last_name\" FROM \"employee\"\n" + "WHERE \"city\" = 'Indianapolis'\n" + "ORDER BY \"emp_id\", \"last_name\";\n";to a much more readable two-dimensional string block like this:
String query = """ SELECT "emp_id", "last_name" FROM "employoee" WHERE "city" = 'Indianapolis' ORDER BY "emp_id", "last_name"; """; -
The new switch expressions remove the difficult-to-read syntax of switches that led to many bugs and confusing code in the past. Particularly the ambiguity of the
break;statement logic:switch (day) { case MONDAY: case FRIDAY: case SUNDAY: System.out.println(6); break; case TUESDAY: System.out.println(7); break; case THURSDAY: case SATURDAY: System.out.println(8); break; case WEDNESDAY: System.out.println(9); break; }is made much easier to reason about using a functional clause to define the correct code to execute for a set of labels:
switch (day) { case MONDAY, FRIDAY, SUNDAY -> System.out.println(6); case TUESDAY -> System.out.println(7); case THURSDAY, SATURDAY -> System.out.println(8); case WEDNESDAY -> System.out.println(9); } -
Always having to do a cast after checking for a type has always been an annoyance to many Java developers. Pattern Matching for instanceof makes this go away. Look at this example you may be familiar with:
if (obj instanceof String) { String s = (String) obj; // grr... ... }Now imagine, you don’t have to have a cast statement for every one of these laying around in your codebase:
if (obj instanceof String s) { // Let pattern matching do the work! ... } -
Helpful NullPointerExceptions are particularly exciting as the ever confusing nulls for no reason don’t come up, and require you to chase down where it happened in the code. Instead there is new information added to the message that ideally gives you a more unique message.
Rearchitecting Trino
With all these exciting changes, what does this mean for Trino? Let’s first dive into the thing that many of our users dread…upgrading.
Upgrade to Java 17 (When it’s time)
As mentioned before, Java 17 is the current LTS version, following Java 11. Java 17 provides significant improvements that we outlined before. We believe that once we update, everyone should be running version 17 to get the best experience out of Trino. Moving to Java 17 allows us to take advantage of many improvements to the JDK and the Java language that were introduced since Java 11. There are some reasons people say they can’t update.
-
Updating Java in all the clients and code that calls Trino is tedious.
You luckily only need to update the server that Trino is running on. The client or CLI can still run any version of Java.
-
There are conflicting Java versions on the node Trino servers run.
If you are running another application depending on Java you shouldn’t be. Ideally Trino runs on its own servers. If there’s a smaller application to, for example, monitor Trino, then you should be able to install a separate version of Trino.
-
There is a company policy requiring specific JDKs be installed on all servers.
You can have side-by-side installs of multiple versions of the JDK and use the appropriate one. You just need to launch Trino with the correct Java
command. If your company is against using a newer JDK, you can point out the arguments above to update the policy to at least include JDK17.
Iterating and improving Trino
We’re also in the process of revamping the core execution engine, which enables us to implement the following improvements:
- Perform adaptive evaluation of expressions based on runtime cost.
- Specialize evaluation for different data encodings (rle, dictionary, etc).
- Implement tighter evaluation loops that make it easier for the VM to vectorize automatically and generate better machine code.
- Implement evaluation of certain operations more efficiently by taking advantage of SIMD or GPU-based processing.
- Columnar evaluation.
Project Hummingbird
Just as we did with the efforts around Project Tardigrade we want to centralize these efforts under a project name that includes a set of motivated community members and give it a cool name.
After some discussion, we would like to announce *Project Hummingbird* is the new banner for the efforts around improving performance and concentrated updates to the core of Trino.
We chose hummingbirds as mascots because they are adaptive, light, and fast. Hummingbirds are the only birds with the incredible capability to fly in any direction and are super fast. It made sense as Trino evolves into a query engine that is capable of adapting to its environment during query runtime, it is akin to these agile and beautiful creatures.
Vectorization is not a silver bullet
There are many ways to parallelize the operations that we run on the Trino server. There’s inter-node parallelization which split data to be operated on across nodes. There’s intra-node parallelization, which generally refers to multithreading across a CPU.
As we start to move towards vectorizations, we start to become hardware dependent and just like with any other hardware setting, your mileage may vary depending on the limitations of the resources Trino is running on.
Further, any time parallelization is applied, there is generally some overhead to coordinate lookups, shuffling more data across processors, etc..
Pull requests of the episode: PR 4649: Disable JIT byte code recompilation cutoffs in default jvm.config
This episodes pull request was added by Shubham Tagra to increase the amount of memory needed to avoid JIT recompilation cutoffs for large methods in the JVM. If these limits are hit, the JIT compiler calls an uncommon_trap to deoptimize the code. If the function is continually retried, continuous deopt or a “deopt storm” can occur, and can cause a large CPU loss. The handling of this is actually a bug in the JVM so this pull request provided a workaround.
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
This had been reported by multiple companies from Comcast to Shopify that had these “random slowness” issues that were resolved when these JVM settings were added.
Demo of the episode: FizzBuzz - SIMD style!
Today I’m stealing, no wait, borrowing a project created by our friend Gunnar Morling. This showcases the well known FizzBuzz game, but programmatically generates the resulting patterns from the game.
Make sure you install JDK 17 before running this code.
git clone [email protected]:bitsondatadev/simd-fizzbuzz.git
mvn clean verify
java --add-modules=jdk.incubator.vector -jar target/benchmarks.jar -f 1 -wi 5 -i 5
Events, news, and various links
Blogs and Documentation
- JEPs in JDK 17 integrated since JDK 11
- Shopify’s Path to a Faster Trino Query Execution: Infrastructure
Videos
- Vector API and Record Serialization
- The Vector API in JDK 17
- JDK 8 to JDK 18 in Garbage Collection: 10 Releases, 2000+ Enhancements
- Concurrent Garbage collectors: ZGC & Shenandoah
Trino Meetup groups
- Virtual
- East Coast (US)
- West Coast (US)
- Mid West (US)
If you want to learn more about Trino, check out the definitive guide from O’Reilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.