Video
- Concept of the week: Data discovery and Amundsen (724s)
- Concept of the week: Amundsen architecture (1450s)
- Concept of the week: Amundsen as a subcomponent to data mesh (2720s)
- PR of the week: Index Trino views (3606s)
- Question of the week: Can I add a UDF without restarting Trino? (4374s)
Audio
Guests
- Mark Grover, Co-creator of Amundsen and Founder at Stemma (@mark_grover).
Release 362
Official announcement items from Martin is not yet available since release it not out… but soon.
Manfreds notes:
- Add new
listaggfunction contributed by Marius - Join performance and
DISTINCTperformance improvements - SQL security related changes in
ALTER SCHEMA - Add
IN tableforCREATE/DROP/…ROLE - Whole bunch of improvements in the BigQuery connector
- Numerous improvements for Parquet file usage in Hive connector
- All connector docs now have SQL support section
Concept of the week: Data discovery and Amundsen
Data discovery is a process that aids in the analysis of data where siloed data has been centralized, and it is difficult to find data or overlap between disparate data sets. Many teams have their own view of the world when it comes to the data they need, but they commonly need to reason about how their data relates to data outside of their domain.
There are typically questions about who owns what data to help identify individuals responsible for maintaining the standards. Additionally, there are also issues around providing documentation around the data, and to identify who to call for help if there are issues using the data. This allows analysts to discover patterns in the data, and periodically audit the data storage practices. Interesting questions also arise around existing policies, and can encourage a system of record that act as a shared front end around their data policies.
What is Amundsen?
Amundsen provides data discovery by using ETL processes to scrape metadata from all of the data sources. It creates a central location to collect all that metadata and enables search and other analytics of this metadata. Here’s how the project describes itself on the Amundsen website:
Amundsen is a data discovery and metadata engine for improving the productivity of data analysts, data scientists and engineers when interacting with data. It does that today by indexing data resources (tables, dashboards, streams, etc.) and powering a page-rank style search based on usage patterns (e.g. highly queried tables show up earlier than less queried tables).
Amundsen has an architecture that interacts primarily with information_schema
tables, among other metadata, depending on the data source. In Trino’s case,
the extractor used
connects directly to the Hive metastore database, for Trino views, since
they’re stored there. Physical tables use the HiveTableMetadataExtractor
to load these tables into Amundsen. This makes sense since the data is stored in
the Hive table format. For non-Hive use cases, you generally want to bypass
using Trino (for now) and directly connect Amundsen to each data source.
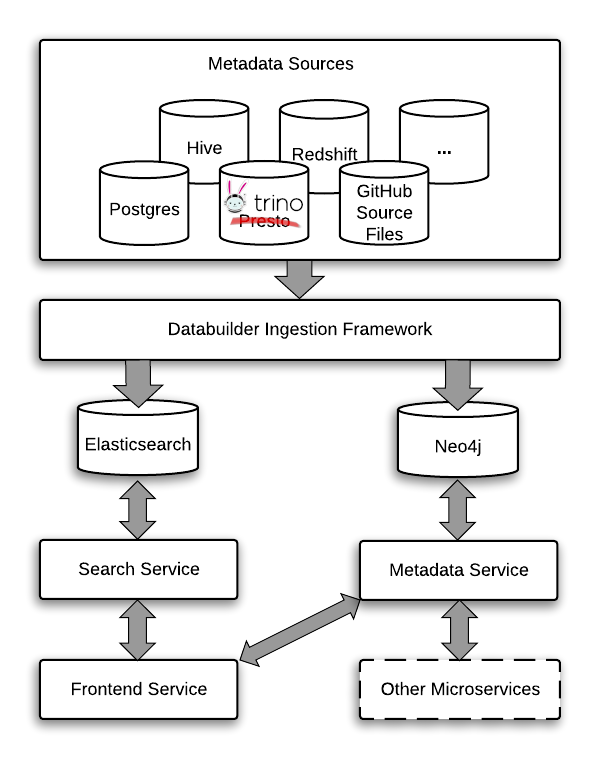
Amundsen includes an ETL framework called databuilder that runs multiple jobs. Jobs contain an ETL task to extract the metadata and load it into the two databases that are central to Amundsen, Neo4j and Elasticsearch. Neo4j stores the core metadata that is represented on the UI. Elasticsearch enables search over the many fields in the metadata. Ingestion via ETL follows the following steps:
- Ingest base data to Neo4j.
- Ingest additional data and decorate Neo4j over base data.
- Update Elasticsearch index using Neo4j data.
- Remove stale data.
Each job contains an ETL task. The task must define an extractor and a loader, and optionally a translator. You can see example configurations for different extractors on the website, like the example for the HiveTableMetadataExtractor.
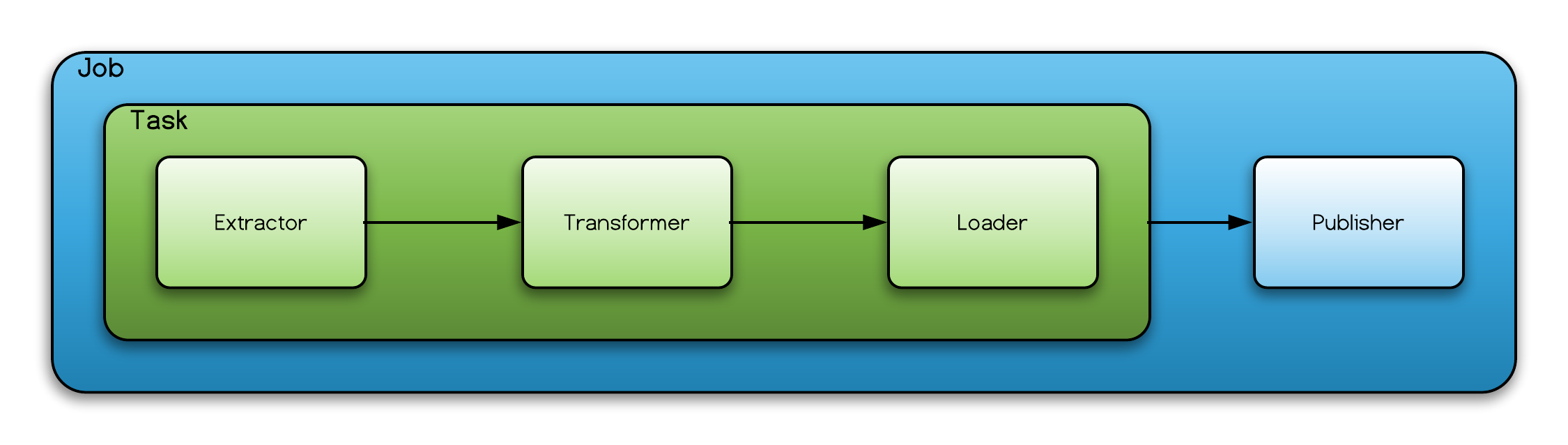
The metadata is modeled using a graph representation in neo4j and optionally Apache Atlas to model advanced concepts, such as, lineage and other relations.
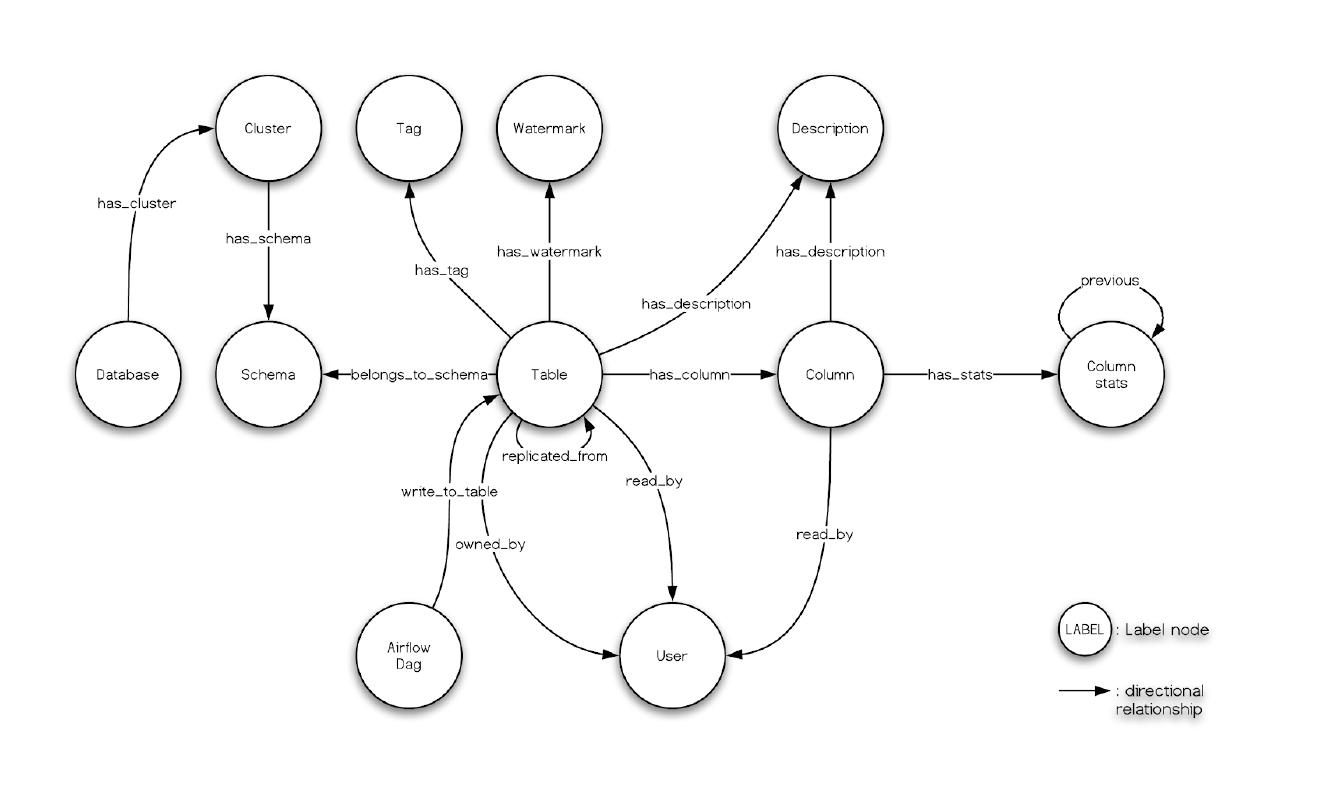
You can learn more about the models in the metadata here.
Amundsen resources
- Docs: https://www.amundsen.io/amundsen/
- GitHub: https://github.com/amundsen-io/amundsen
- YouTube: https://www.youtube.com/playlist?list=PL0UJdxehTNlKnGU_h7k2fzJyvAiufeh1U
- Slack: Join
Amundsen as a subcomponent to data mesh
A new architecture, philosophy, and yes, buzzword that is gaining momentum is the data mesh. While it certainly still not concretely defined, it is in the research and development phase. Data mesh is gaining a lot of attention as a potential alternative to data lakes and data warehouses for analytics solutions.
Data mesh mirrors the philosophy of microservice architecture. It argues that data should be defined and maintained by teams responsible for their business domain similar to how the responsibility is delegated at the service layer. Since not everyone is going to be a data engineer on the domain team, there must be some consideration for the architecture of such a platform. The author of this paradigm, Zhamak Dehghani, lays out 4 principles that characterize a data mesh. Below are the principles of a Data mesh. Below the systems that provide some or all of the solution for a principle are listed in parentheses.
- Domain-oriented decentralized data ownership and architecture (Trino & Amundsen)
- Data as a product (Amundsen)
- Self-serve data infrastructure as a platform (Trino)
- Federated computational governance (Amundsen to some extent)
Stemma
Like with many successful open source projects, there are enterprise products that build on and support the open source project. Stemma is the enterprise company that supports Amundsen. It’s founded by Mark and others central to the open source project.
PR of the week: Index Trino views
The PR (or should we say commit) of the week, adds the original Trino extractor. As mentioned above this extractor is only needed for views as the physical tables exist in Hive and are retrieved.
Call to contribute to Amundsen
If you want to help out, you can consider adding the Trino image similar to this commit completed a while back.
Demo: Extracting metadata from Hive metastore and loading it into Amundsen
There were technical difficulties on the day of broadcasting the show, so the demo was moved to its own separate video.
The steps in this demo are adapted from the Amundsen installation page.
Clone this repository and navigate to the trino-getting-started/community_tutorials/amundsen
directory. For this demo you need at least 3GB of memory allocated to your
Docker application.
git clone [email protected]:bitsondatadev/trino-getting-started.git
cd community_tutorials/amundsen
docker-compose up -d
Once all the services are running, clone the Amundsen repository in a separate terminal. Then navigate to the databuilder folder and install all the dependencies:
git clone --recursive https://github.com/amundsen-io/amundsen.git
cd databuilder
python3 -m venv venv
source venv/bin/activate
pip3 install --upgrade pip
pip3 install -r requirements.txt
python3 setup.py install
Navigate to MinIO at http://localhost:9000 to create the tiny bucket for the
schema in Trino to map to. In Trino, create a schema and a couple tables in the
existing minio catalog:
CREATE SCHEMA minio.tiny
WITH (location = 's3a://tiny/');
CREATE TABLE minio.tiny.customer
WITH (
format = 'ORC',
external_location = 's3a://tiny/customer/'
)
AS SELECT * FROM tpch.tiny.customer;
CREATE TABLE minio.tiny.orders
WITH (
format = 'ORC',
external_location = 's3a://tiny/orders/'
)
AS SELECT * FROM tpch.tiny.orders;
Navigate back to the trino-getting-started/community_tutorials/amundsen directory in the same
Python virtual environment you just opened.
cd trino-getting-started/community_tutorials/amundsen
python3 assets/scripts/sample_trino_data_loader.py
View the Amundsen UI at http://localhost:5000 and try to search test, it should return the tables you just created.
You can verify dummy data has been ingested into Neo4j by visiting http://localhost:7474/browser/.
Log in as neo4j with the test password and run
MATCH (n:Table) RETURN n LIMIT 25 in the query box. You should see few tables.
If you have any issues, look at some of the troubleshooting steps in the Amundsen installation page.
Question of the week: Can I add a UDF without restarting Trino?
This weeks question of the week comes in from the Trino Slack from Chen Xuying.
Is there any way to register a new user defined function (UDF) and needn’t restart coordinator and worker?
Currently, no. In Java, jar files and all the java code is loaded up on start time. So in order to load the files on all the worker nodes and coordinator, you need to restart. There are various ways for UDFs to be implemented in a dynamic way so we are still looking for a suggestion here.
One option, as Manfred mentions, would be to load Javascript as a UDF as Java allows to compile Javascript. This would allow for new functions to be added without restart. There may be other ways to acheive and we invite you to contribute your ideas!
Events, news, and various links
Blogs
Trino Meetup groups
- Virtual
- East Coast (US)
- West Coast (US)
- Mid West (US)
If you want to learn more about Trino, check out the definitive guide from OReilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.