Video
- Concept of the week: Event stream abstractions and Pravega (915s)
- Demo of the week: Querying Pravega from Trino (4260s)
- PR of the week: Pravega presto-connector PR 49 (4851s)
- Question of the week: What is the point of Trino Forum, and what is the relationship to Trino Slack? (5167s)
Audio
Guests
- Derek Moore, Software Senior Principal Engineer at Dell EMC (@derekm00r3).
- Andrew Robertson,Principal Software Engineer at Dell EMC (@andrew-robertson).
- Karan Singh, Software Engineer 2 at Dell EMC (@singhkaranrakesh).
Trino Summit 2021
Get ready for Trino Summit, coming October 21st and 22nd! This annual Trino community event is where we gather practitioners that deploy Trino at scale and share their experiences and best practices with the rest of the community. While the planning for this event was a bit chaotic due to the pandemic, we have made the final decision to host the event virtually for the safety of all the attendees. We look forward to seeing you there, and can’t wait to share more information in the coming weeks!
Release 363
Official announcement items from Martin:
- New HTTP event listener plugin
- Insert overwrite for S3-backed tables
- Support for Elasticsearch
scaled_floattype - Support for Cassandra
tupletype - Support for
timetype in MySQL connector - Support for SQLServer
datetimeoffsettype
Manfred’s additional notes:
- Misc performance and memory usage improvements
SHOW ROLESfixEXPLAIN ANALYZEfix for estimate display- Numerous improvements for Parquet files in Hive and Iceberg connectors
More info at https://trino.io/docs/current/release/release-363.html.
Concept of the week: Event stream abstractions and Pravega
Events and streams
What is an event? This sounds like a silly question when asked generally. The answer is less clear when discussing event-driven systems though. An event is an action or occurrence that is captured by either a sensor, or a generated by a source system, and emitted to a sink system. Some examples include user events from an application, system events in telemetry systems, or sensor events from monitoring applications.
What is an event stream? Now knowing what an event is, an event stream is an unbounded set of events that are tracked over time.
In this simple view, an event stream contains a sequential list of events. The list contains events that have been processed, and some that still need to be processed.
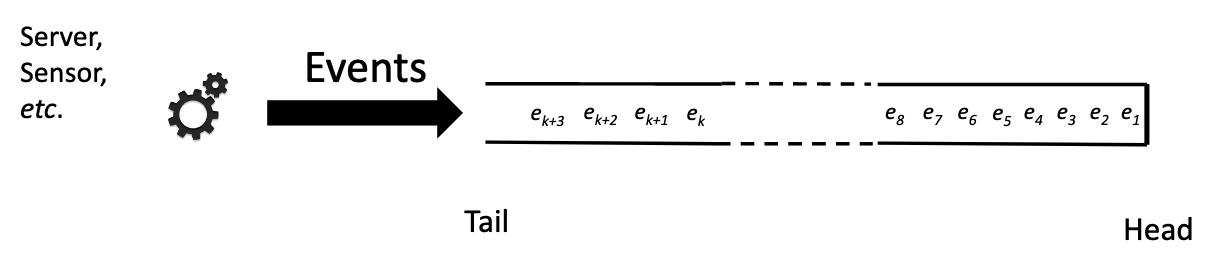
Cloud Native Computing Foundation Presentation: Source.
This is very different from a more realistic view of event streams that considers that events arrive and are processed in parallel. Event load may also fluctuate as events may burst around specific events or events have specific periodic behavior. While taking event ingest (writes) into consideration, it is also important to consider event egress (reads) as part of the problem of representing event streams.
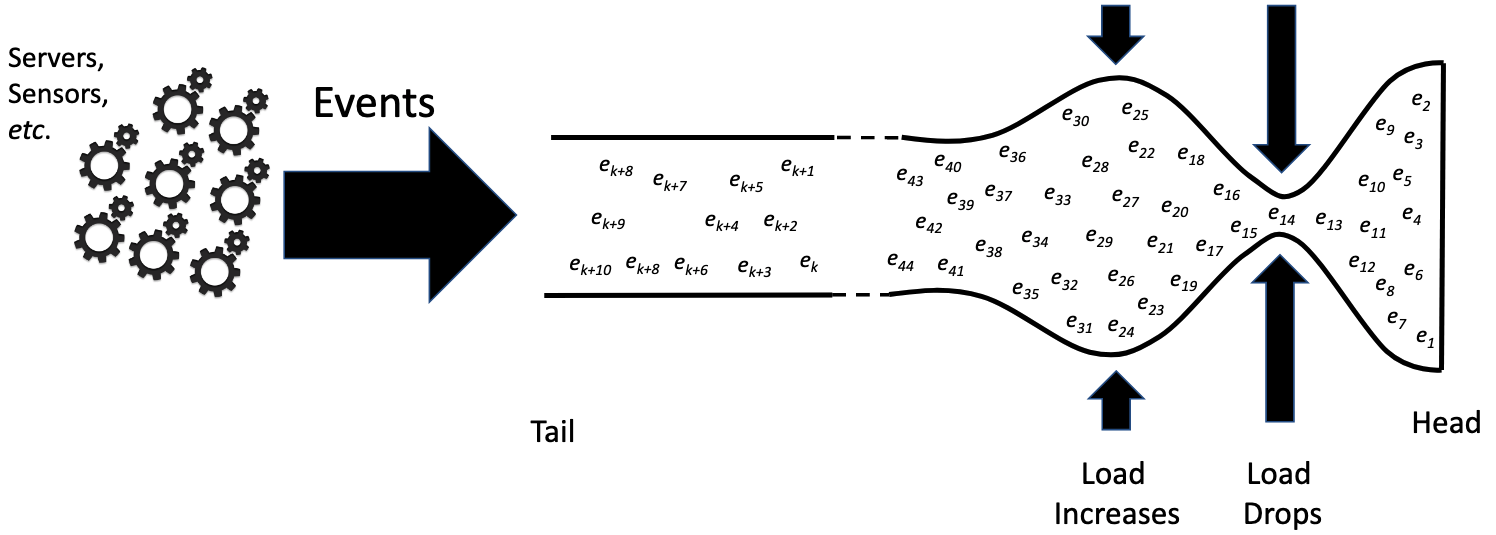
Cloud Native Computing Foundation Presentation: Source.
Pravega and segments
Engineers at Dell Labs wanted to find a better abstraction to solve for the problems they saw in existing event streaming systems. This included how to address this type of constant shift in scaling, while also addressing the brittle storage abstractions that even streams use today. The storage abstraction needs to allow for both real-time and historical analytics. The data along a particular transaction also needs to be consistent.

Cloud Native Computing Foundation Presentation: Source.
Their solution is Pravega. The core of Pravega models streams built around a storage unit called a segment. A segment is an append-only sequence of bytes (not events/records). This offers a greater level of flexibility and better parallelism and serialization over streams. Pravega stream writers are then able to write in parallel increasing ingest throughput.
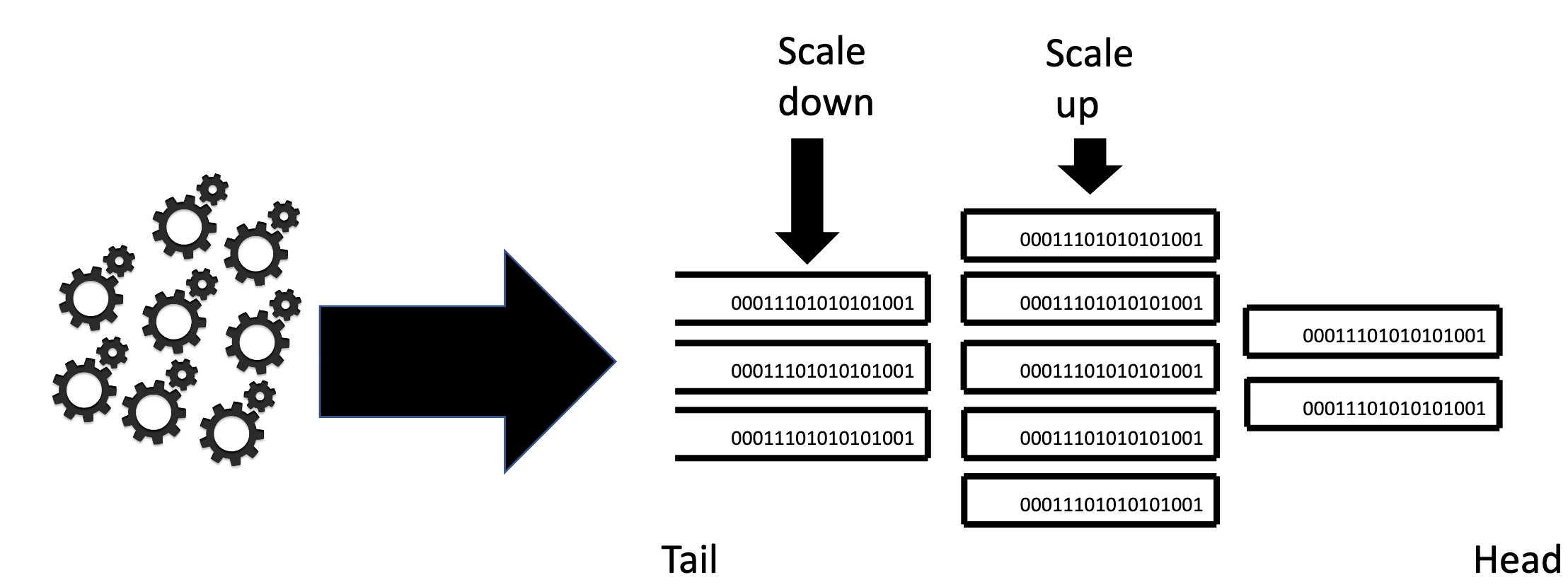
Cloud Native Computing Foundation Presentation: Source.
You can use routing keys to map events to particular segments. Pravega enforces order within specific keys, but does not guarantee ordering of events across keys. The tradeoff is providing ordering of events versus higher parallelism and better performance.
With segments, you can also scale up and scale down the number of segments depending on the workload you’re experiencing. Another compelling capability this enables is managing transactions in the stream. As writers submit data, they write to a temporary segment, which are merged to a permanent segment on commit.
![]()
Cloud Native Computing Foundation Presentation: Source.
The following diagram displays autoscaling splits and merges as specific routing keys become more popular. To provide a clearer example, say that the routing keys are actually just hash geo location values for a taxi app that are mapped between zero and one. As certain locations become crowded, lets say that a lot of people are going home for the work day, and many taxis are in the downtown location. The locations mapped to the downtown routing keys can automatically trigger a split, and once the rush hour is over, it merges these segments as traffic slows down.
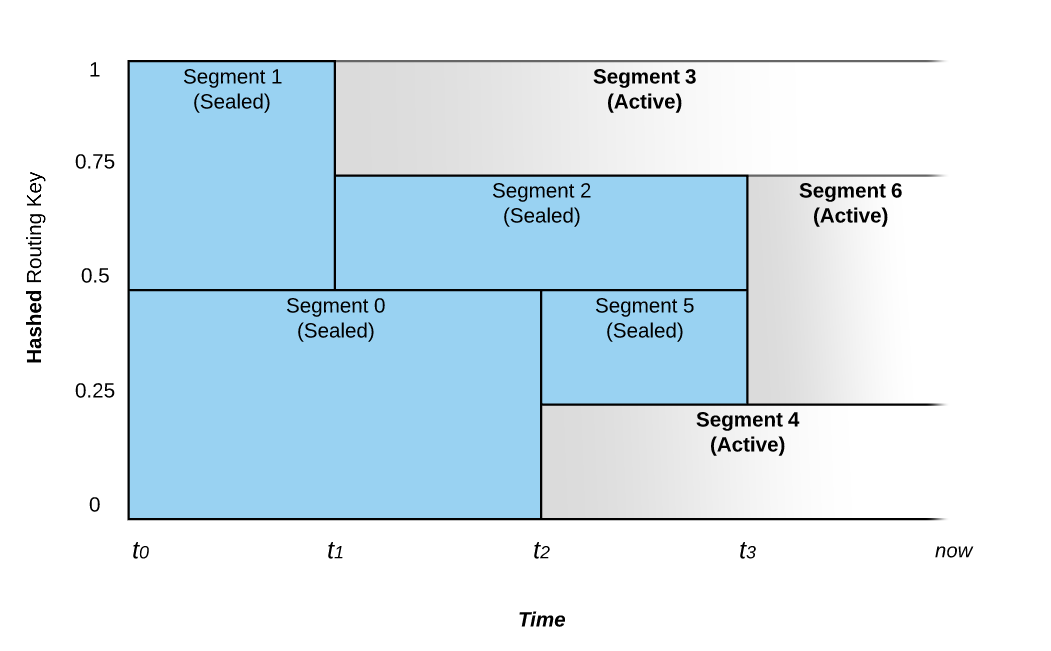
Pravega Docs: Source.
Pravega architecture
The Pravega architecture comes with writers groups and reader groups that scale up and down along with the autoscaling applied to the segments. It consists of a controller that maintains stream metadata and the segment store that works off of tier one storage (Apache Bookkeeper) and tier two storage (Object storage).
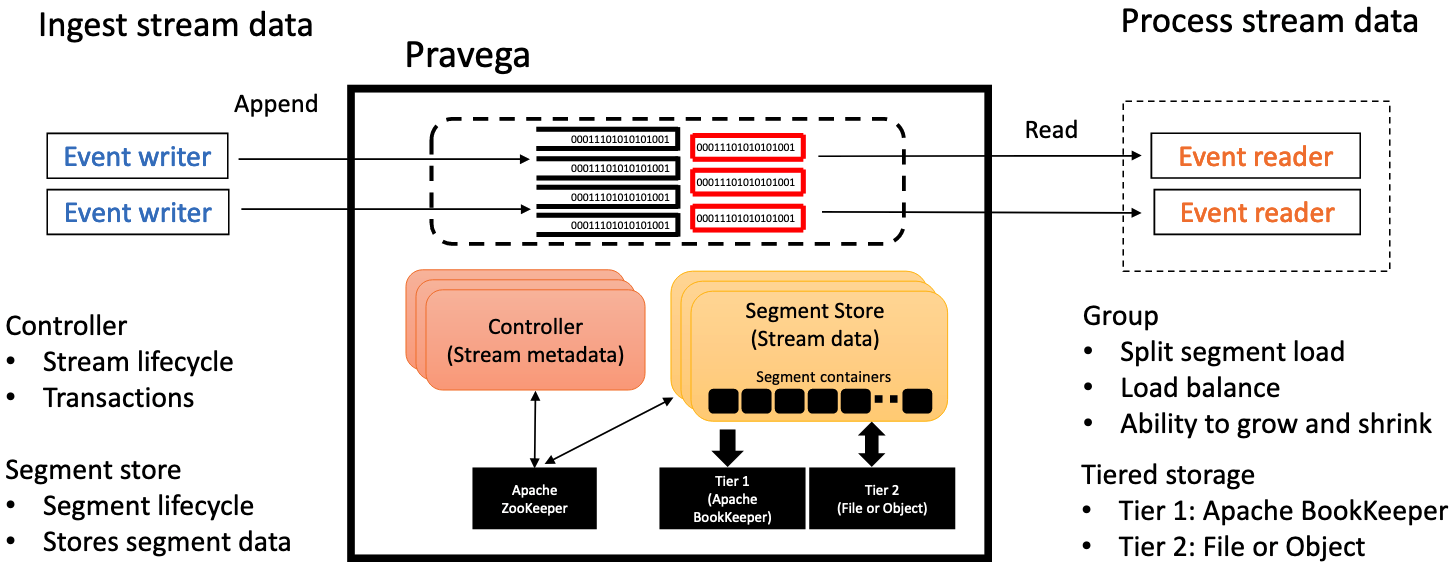
Pravega Docs: Source.
Just like Trino, Pravega also aims to build a rich set of connectors with systems that act as a source and sink. This includes a connector used for Trino.
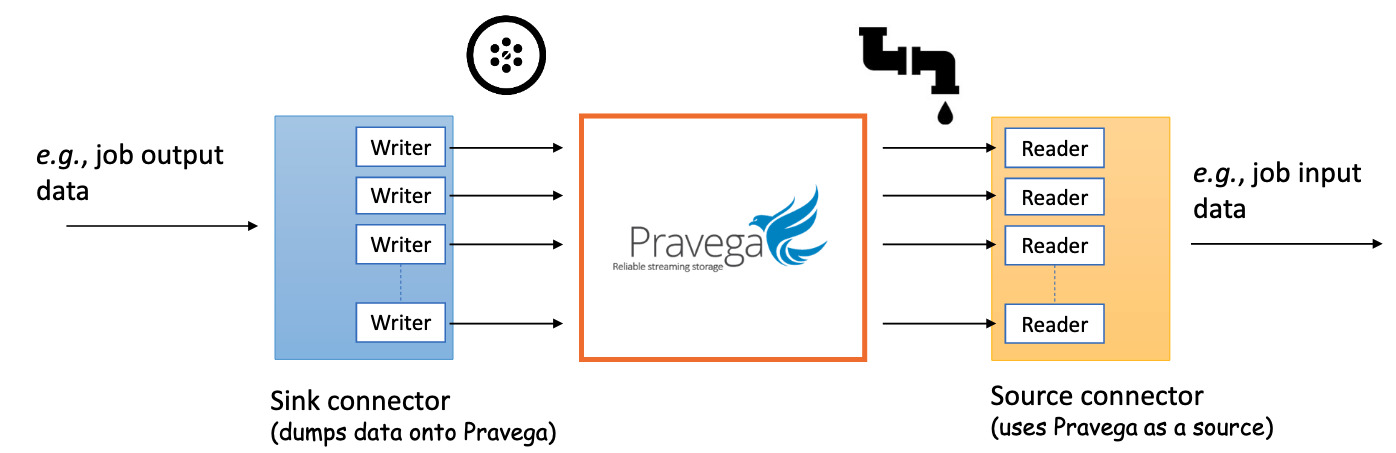
Pravega Docs: Source.
Pravega compared to other event streaming platforms.
This chart is very helpful resource to summarize Pravega against other popular streaming platforms. This comes from the Pravega site so be sure to check for an up to date list of these features moving forward.
| Pravega | Kafka | Pulsar | |
|---|---|---|---|
| Transactions | ✅ | ✅ | ✅ |
| Event streams | ✅ | ✅ | ✅ |
| Long-term retention | ✅ | ✅ | |
| Durable by default | ✅ | ✅ | |
| Auto-scaling | ✅ | ||
| Ingestion of large data (video) | ✅ | ||
| efficient at high partition counts | ✅ | ||
| Consistent state replication | ✅ | ||
| Key-value tables | ✅ |
Comparison between Pravega, Kafka, and Pulsar: Source
Demo of the week: Querying Pravega from Trino
This week the Pravega teams demonstrates an example from their getting-started tutorial for the Trino connector.
PR of the week: Pravega presto-connector PR 49
This weeks PR of the week doesn’t come from the Trino repository this week but rather the presto-connector repository. The Trino portion of the repository was committed by Dell engineer Karan Singh. As it states, this now makes Pravega available from Trino along with the original Presto connector.
Thanks Karan for adding Trino and Andrew for writing the original Presto-Pravega connector!
Question of the week: What is the point of Trino Forum and what is the relationship to Trino Slack?
Our question of the week comes from the new Trino Forum by Starburst. Brian and a few others at Starburst created. Slack is a much more adhoc platform for people to work through problems rather than to search and find solutions to problems. The Trino community has such a great amount of knowledge accumulated in this Slack channel, but there is no way for people to find answers unless they have joined here and none of the information we discuss can be found by a search engine like Google.
Further, a lot of the answers are scattered between different conversations and
this too can be condensed and simplified. I pondered about the best way for us
to expose this and though maybe to add an FAQ page on
Events, news, and various links
Blogs and resources
Trino Meetup groups
- Virtual
- East Coast (US)
- West Coast (US)
- Mid West (US)
If you want to learn more about Trino, check out the definitive guide from OReilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.