Video
- Concept of the month: Introducing Project Tardigrade (1226s)
- Concept of the month: Why ETL in Trino? (1377s)
- Concept of the month: Why are people reluctant to do their ETL in Trino? (2128s)
- Concept of the month: What are the limitations of the current architecture? (2605s)
- Concept of the month: Trino engine improvements with Project Tardigrade (3179s)
- Demo of the month: Task retries with Project Tardigrade (4750s)
- PR of the month: PR of the month: PR 10319 Trino lineage fails for AliasedRelation (4917s)
- Question of the month: How do you cast JSON to varchar with Trino? (5078s)
Audio
Guests
- Andrii Rosa, Software Engineer at Starburst (@andrii-rosa-79578561).
- Brian Zhan, Product Manager at Starburst (@brianzhan1).
- Lukasz Osipiuk, Software Engineer at Starburst (@losipiuk).
- Martin Traverso, Trino & Presto Co-founder and CTO at Starburst (@mtraverso).
- Zebing Lin, Software Engineer at Starburst (@linzebing).
Trino Summit 2021
If you missed Trino Summit 2021, you can watch it on demand, for free!
Releases 367 and 368
Martin’s official announcements merged into one:
- Lineage tracking for
WITHclauses and subqueries. - Option to hide inaccessible columns in
SELECT *. flush_metadata_cache()procedure for the Hive connector.- Improve performance of
DECIMALtype. - File-based access control for the Iceberg connector.
- Support for
TIMEtype in the SingleStore connector. - Support for
BINARYtype in the Phoenix connector.
Manfred’s additional notes:
- Prevent data loss on
DROP SCHEMAin Hive and Iceberg connectors. - New default query execution policy
phasedbrings performance improvements. - And finally, numerous smaller improvements around memory management and query processing for our project Tardigrade.
More detailed information is available in the Trino 367 and Trino 368 release notes.
Concept of the month: Introducing Project Tardigrade
Before we jump right into the project, lets cover some of the history of ETL and data warehousing to better understand the problems that Tardigrade solves.
Why do people want to do ETL in Trino?
Trino is used for Extract, Transform, Load (ETL) workloads in many companies, like Salesforce, Shopify, Slack, and older versions of Trino at Facebook.
First, the most important thing is query speed. Queries run a lot faster in Trino. Open data stack technologies like Hive and Spark retry the query from intermediate checkpoints when something fails. However, there’s a performance cost to this. Trino has always been focused on delivering query results as quickly as possible. Now, Trino performs task-level retries enabling failure recovery where needed for the more long-running queries. More on this later though.
Second, most companies have widely dispersed and fragmented data. It’s typical for most companies to have different storage systems for different use cases. This only becomes more commonplace when a merger and acquisition happens, and you have a ton of data stored in yet another location. The acquiring company ends up having key information living in a bunch of different places. The net result is that the data engineer ends up spending weeks to write that simple dashboard. The data scientist trying to understand a trend gets impeded whenever trying to draw data from a new source and gives up.
Third, data engineers want to spend their time writing business logic, not moving SQL between engines. Unfortunately, this is where they end up spending much of their time. Many do their ad-hoc analytics in Trino, because it provides a far more interactive experience than any other engine. If they don’t just use Trino, they have a 1,000 line SQL ETL job that they now need to convert into another dialect. You just need to search “convert Spark Presto SQL Stack Overflow” to see the numerous challenges that people face moving between engines.
Whether it’s the optimizations in one engine not working in the other, a UDF in Trino not existing in Spark, strange differences in the SQL dialect tripping people up, or being extremely difficult to debug, these factors always cause a delay in completing their tasks. Data engineers are especially paranoid about converting SQL correctly. Imagine reporting an incorrect revenue metric externally, billing a user of your platform the incorrect amount, or delivering the wrong content to users due to any of these issues.
Why are people reluctant to do their ETL in Trino?
Before the drive for big data and technologies like Hadoop showed up on the scene, systems like Teradata, Netezza, and Oracle were used to run ETL pipelines in a largely offline manner. If a query failed, you simply had to restart it. Systems would brag about the low failure rate of their systems.
As Big Data came to the forefront, systems like the Google File System, that largely inspired the design for the Hadoop Distributed File System, aimed to build large distributed systems that supported fault-tolerance. In essence, faults were expected, and if a node in the system failed, no data would be lost.
At this same time, compute and storage systems were becoming separate systems. Just as storage was built with fault-tolerance, compute systems like MapReduce that processed and transformed data was also built with fault tolerance in mind. Apache Hive is a syntax and metadata layer that enables generating MapReduce jobs without having to write code. Apache Spark came on the analytics scene by introducing lineage as a way for engineers to have more control over how and when their datasets are flushed to disk. This technique, while novel, still took a very pessimistic view that allowing faults was the worst case scenario to avoid.
When Trino was created, it was designed with speed in mind. Trino creators Martin, Dain, and David chose not to add fault-tolerance to Trino as they recognized the tradeoff of fast analytics. Due to the nature of the streaming exchange in Trino all tasks are interconnected. A failure of any task results in a query failure. To support long running queries Trino has to be able to tolerate task failures.
Having an all-or-nothing architecture makes it significantly more difficult to tolerate faults, regardless of how rare they are. The likelihood of a failure grows with the time it takes to complete a query. This risk also increases as the resource demands, such as memory requirements of a query, grow. It’s impossible to know the exact memory requirements for processing a query upfront. In addition to increased likelihood of a failure, the impact of failing a long running query is much higher, as it often results in a significant waste of time and resources.
You may think all-or-nothing is a model destined to fail, especially when scaling to petabytes of data. On the contrary, Trino’s predecessor Presto was commonly used to execute batch workloads at this scale at Facebook. Even today, companies like Salesforce, Doordash, and many others, use Trino at Petabyte scale to handle ETL workloads. While it is possible, scaling Trino to run petabyte scale ETL pipelines, you really have to know what you’re doing.
Resource management is another challenge. Users don’t know exactly what resource utilization to expect from a query they submit. It is challenging to properly size the cluster and to avoid resource related failures.
In essence, most people avoid using Trino for ETL because they lack the understanding of how to correctly configure Trino at scale.
What are the limitations of the current architecture?
In the current architecture Trino plans all tasks for processing a specific query upfront. These tasks interconnect with one another as the results from one task are the input for the next. This interdependency is necessary but if any task fails along the way, it breaks the entire chain.
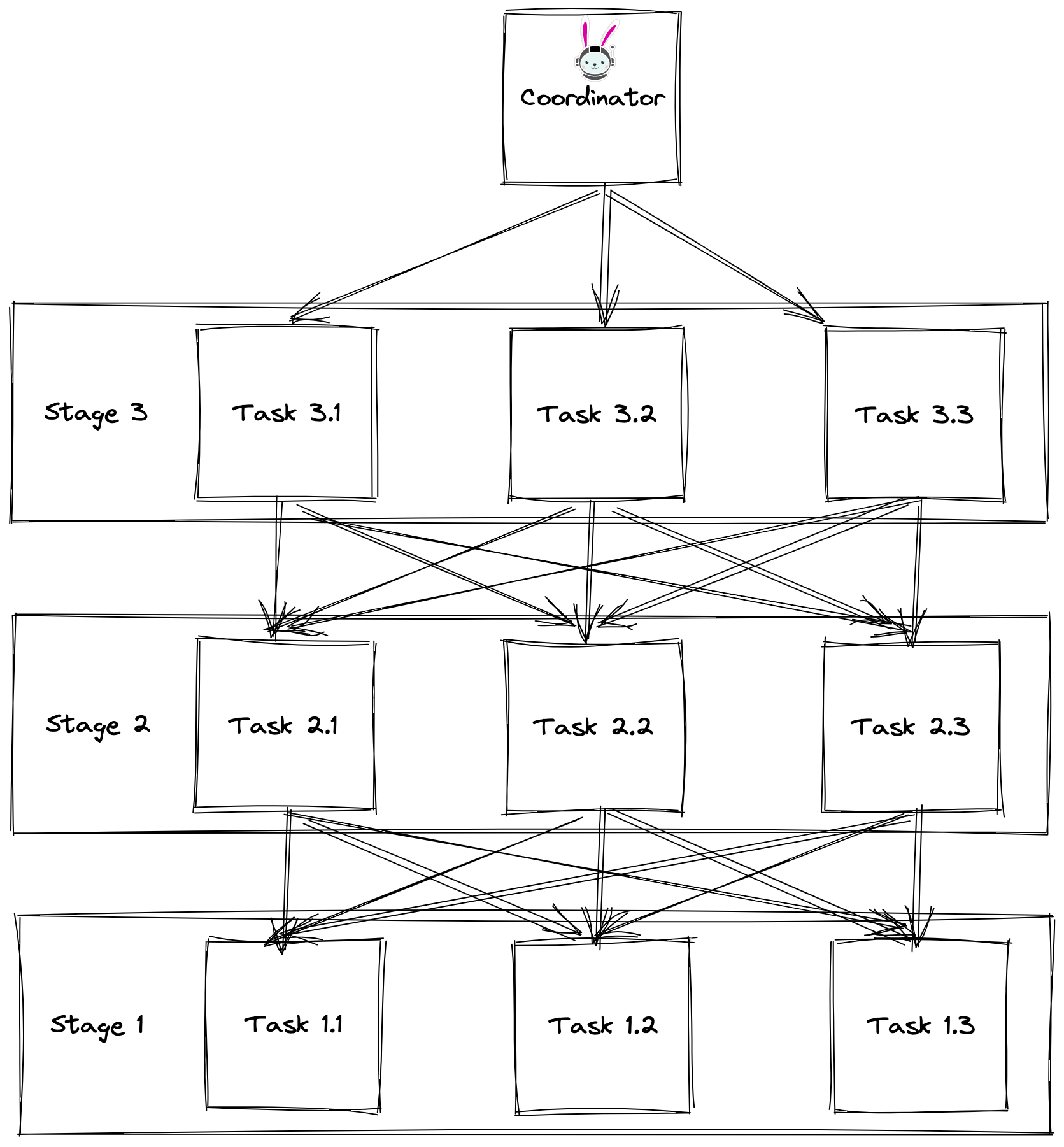
Data is streamed through task graph with no intermediate checkpointing. The query execution has just internal, volatile state of operators running within tasks.
As stated before, this architecture has advantages. Most notably high throughput and low latency. Yet it implies some limitations too. Probably the most natural one is that it does not allow for granular failure recovery. If one of the tasks dies there is no way to restart processing from some intermediary state. The only option is to rerun the whole query from the very beginning.
The other notable limitation is around memory consumption. With static task placement we have little control over resource utilization on nodes.
Finally, the current architecture makes many decisions upfront during query planning. The engine creates a query plan based on incomplete data using table statistics, or blindly, if statistics are not available. After the coordinator creates the plan, and query processing started, there aren’t many ways to adapt. We have much more information during query execution at runtime. For example, we cannot change the number of tasks for a stage. If we observe data skew, we can’t move tasks away from the overworked node, so the affected tasks have more resources at hand. We cannot change the plan for a subquery, if we notice that decision already made is not optimal.
Trino engine improvements with Project Tardigrade
Project Tardigrade aims to break the all-or-nothing execution barriers. It opens many new opportunities around resource management, adaptive query optimization, and failure recovery. We will use a technique called spooling that stores intermediate data in an efficient buffering layer at stage boundaries. The buffer stores intermediate results for the duration of a query or a stage, depending on the context. The project is named after the microscopic Tardigrades that are the world’s most indestructible creatures, akin to the resiliency we are adding to Trino.
![]()
Buffering intermediate results makes it possible to execute queries iteratively. For example, the engine can process one or several tasks at a time, effectively reducing memory pressure, and allow memory intensive queries to succeed without a need to expand the cluster. Tardigrade can significantly lower cost of operation, specifically for the situation when only a small number of queries requires more memory than available.
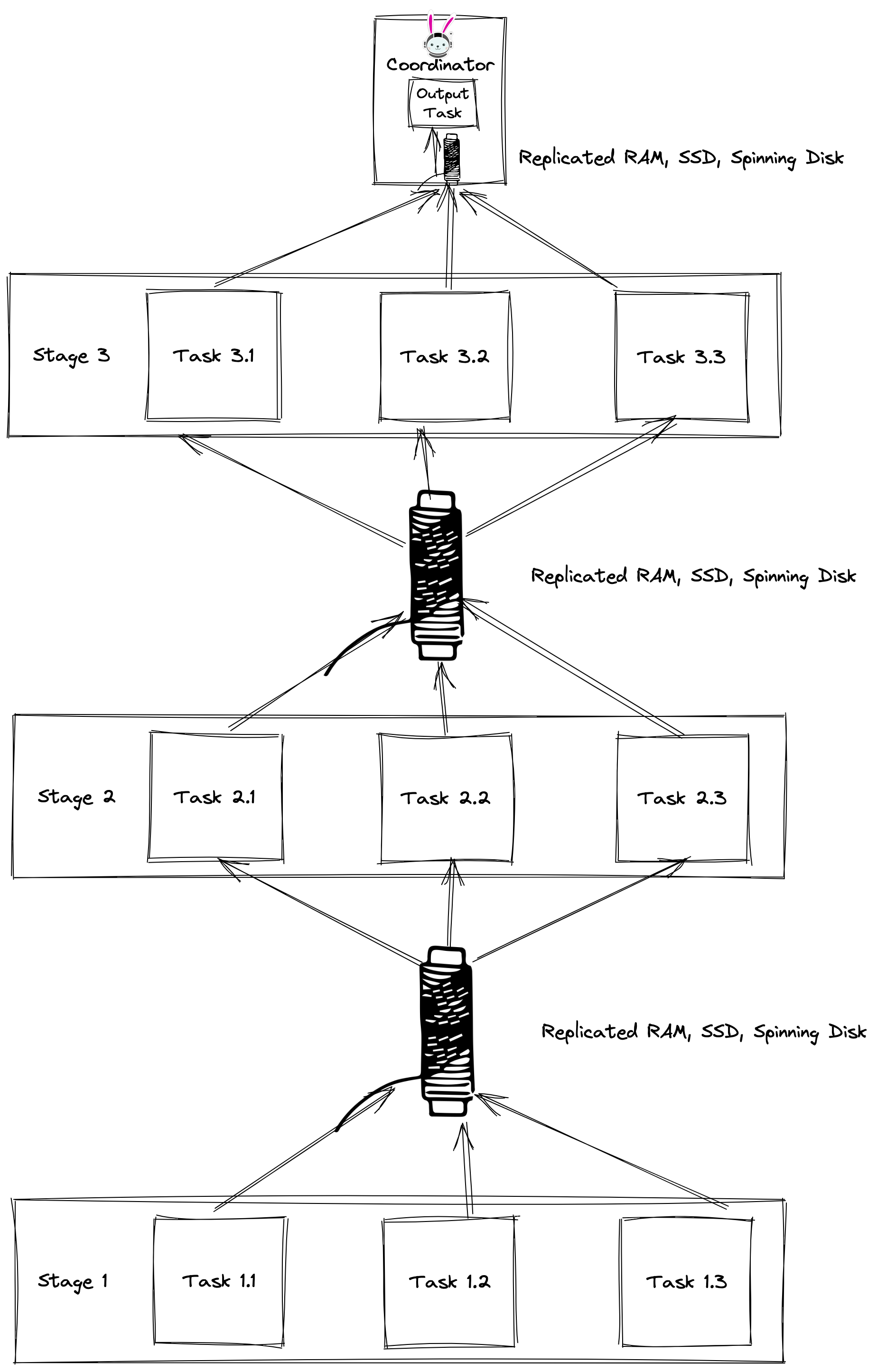
Adaptive planning
The engine may also decide to re-optimize the query at stage boundaries. When
the engine buffers the intermediate data, it is possible to get better insight
into the nature of the data as it’s processed and adapt query plans accordingly.
For example, when the cost based optimizer makes a bad decision, because of
incorrect statistics or estimates, it can pick the wrong type of join, or a
suboptimal join order. The engine can then suspend the query, re-optimize the
plan, and resume processing. Additionally, it may allow the engine to discover
skewed datasets, and change query plans accordingly. This may significantly
improve efficiency and landing time for workloads that are JOIN heavy.
Resource management
Iterative query processing allows us to be more flexible at resource management. Resource allocation can be adjusted as the queries run. For example, when a cluster is idle, we may allow a single query to utilize all available resources on a cluster. When more workload kicks in, the resource allocation for the initial query can be gradually reduced, and available resources can be granted to newly submitted workloads. With this model it is also significantly easier to implement auto scaling. When the submitted workload requires more resources than currently available in the cluster, the engine can request more nodes. Or the opposite, if the cluster is underutilized it is easier to return resources when there’s no need to wait for slow running tasks. Being able to better manage available resources, and adjust the resource pool based on the current workload submitted, would make the engine significantly more cost effective.
Fine-grained failure recovery
Last, but not least, with project Tardigrade we are going to provide fine-grained failure recovery. The buffering introduced at stage boundaries allows for a transparent restart of failed tasks. Fine grained failure recovery would make completion time for ETL pipelines significantly more predictable. Also, it opens the opportunity of running ETL workloads on much cheaper, widely available spot instances that can further optimize operational costs.
Opportunities that Tardigrade opens
In summary, in Project Tardigrade we work on the following improvements to Trino:
- Predictable query completion times.
- The ability to scale up or down to match the workload at runtime.
- Fine grained resource management.
- Non-homogenous hardware.
- Adaptive resource limits for tasks.
- Graceful Shutdown improvement.
- Cheaper compute costs using spot instances that have lower failure guarantees.
- Enables adaptive query replanning during runtime as context changes.
- Handle situations where certain tasks are affected by data skew.
Efficient exchange data buffering implementation
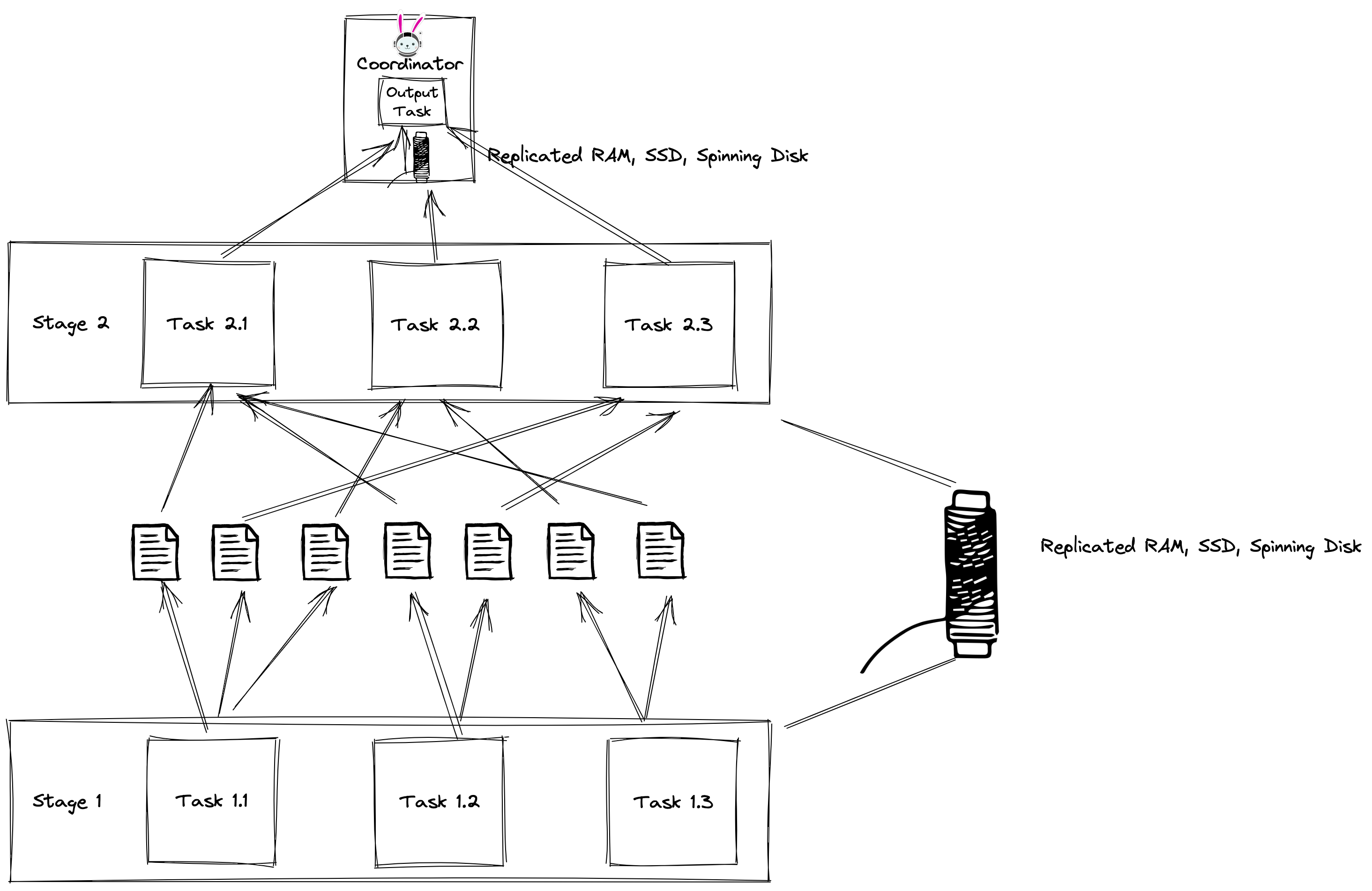
This all sounds incredible, but it begs the question of how to best implement these buffers? Enabling task-level retry requires us to store intermediate exchange data to a “distributed buffer”. In order to minimize the level of disturbance buffering has on the query performance, there needs to be careful design consideration.
A naive implementation is to use a cloud object storage as intermediate storage. This allows you to scale without maintaining a separate service. This is the initial option we are using as a prototype buffer. It is intended as a proof-of-concept and should be good enough for small clusters of ten to twenty nodes. This option can be slow and won’t support high-cardinality exchanges. The number of files grows quadratically with the number of partitions. Trino then has keep track of the metadata of all these files in order to plan and schedule which tasks require which files for the query. With the high amount of files, there is memory cost to hold that metadata. There is also a penalty for the time and bandwidth it takes on the network to list them all. This is a well know many small files problem in big data.
Distributed memory with spilling as a buffer
This solution requires a long-running managed service, but improves performance. Depending on the design we choose, we can use write-ahead buffers to output data belonging to the same partition and provide sequential I/O to downstream tasks.
Demo of the month: Task retries with Project Tardigrade
In this months demo, Zebing showcases task retries using Project Tardigrade after throwing his EC2 instance out the window! See what happens next…
PR of the month: PR 10319 Trino lineage fails for AliasedRelation
This month’s PR of the month was created to resolve an issue reported by Lyft Data Infrasturcture Engineer, Arup Malakar (@amalakar).
Arup reported that Trino lineage fails to capture upstream columns when join and
transformation is used. This issue more generally applied to any column used
with function where its argument are from a AliasedRelation. Starburst
engineer, Praveen Krishna (@Praveen2112),
resolved the issue two days later, and with the help of Arup and the Lyft team,
tested the fix works!
Thanks to both Arup and Praveen for the fix!
Question of the month: How do you cast JSON to varchar with Trino?
This month’s question of the month comes from Borislav Blagoev on Stack Overflow. He asks, “How do you cast JSON to varchar with Trino?”
This was answered by Guru Stron:
Use json_format/ json_parse to handle json object conversions instead of casting:
select json_parse('{"property": 1}') objstring_to_json, json_format(json '{"property": 2}') jsonobj_to_string
Output:
| objstring_to_json | jsonobj_to_string |
|---|---|
| {“property”:1} | {“property”:2} |
Events, news, and various links
Blogs and resources
Trino Meetup groups
- Virtual
- East Coast (US)
- West Coast (US)
- Mid West (US)
If you want to learn more about Trino, check out the definitive guide from OReilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.