Video
- Releases: 396 to 401 (883s)
- Concept of the episode: Intro to Hudi and the Hudi connector (1349s)
- Concept of the episode: Merge on read and copy on write tables (1349s)
- Concept of the episode: Hudi metadata table (2364s)
- Concept of the episode: Hudi data layout (2799s)
- Concept of the episode: Robinhood Trino and Hudi use cases (3072s)
- Concept of the episode: Current state and roadmap for the Hudi connector (3795s)
- PR of the episode: PR 14445: Fault-tolerant execution for PostgreSQL and MySQL connectors (4094s)
- Demo: Using the Hudi Connector (4414s)
Audio
Hosts
- Brian Olsen, Developer Advocate at Starburst (@bitsondatadev)
- Cole Bowden, Developer Advocate at Starburst
Guests
- Sagar Sumit, Software Engineer at Onehouse (@sagarsumit6)
- Grace (Yue) Lu, Software Engineer at Robinhood
Register for Trino Summit 2022!
Trino Summit 2022 is coming around the corner! This free event on November 10th will take place in-person at the Commonwealth Club in San Francisco, CA or can also be attended remotely!
Read about the recently announced speaker sessions and details in these blog posts:
You can register for the conference at any time. We must limit in-person registrations to 250 attendees, so register soon if you plan to attend in person!
Releases 396 to 401
Official highlights from Martin Traverso:
- Improved performance when processing strings.
- Faster writing of
array,map, androwtypes to Parquet. - Support for pushing down complex join criteria to connectors.
- Support for column and table comments in BigQuery connector.
- S3 Select pushdown for JSON data in Hive connector.
- Faster
date_truncpredicates over partition columns in Iceberg connector. - Reduced query latency with Glue catalog in Iceberg connector.
- New Hudi connector.
- Improved performance for Parquet data in Delta Lake, Hive and Iceberg connectors.
- Support for column comments in Accumulo connector.
- Support for
timestamptype in Pinot connector.
- Faster joins.
- Faster reads of decimal values in Parquet data.
- Support for writing
array,row, andtimestampcolumns in BigQuery. - Support for predicate pushdown involving datetime types in MongoDB.
- Support for TRUNCATE in BigQuery connector.
- Support for the Pinot proxy.
- Improved latency when querying Iceberg tables with many files.
- Improved performance and reliability of
INSERTandMERGE. - Support for writing to Google Cloud Storage in Delta Lake.
- Support for IBM Cloud Object Storage in Hive.
- Support for writes with fault-tolerant execution in MySQL, PostgreSQL, and SQL Server.
Additional highlights worth a mention according to Cole:
- The new Hudi connector is worth mentioning twice. It was in the works for a while, and we’re really excited it has arrived and continues to improve.
- Trino 396 added support for version three of the Delta Lake writer, then Trino 401 added support for version four, so we’ve jumped from two to four since the last time you saw us!
- There have been a ton of fixes to table and column comments across a wide variety of connectors.
More detailed information is available in the release notes for Trino 396, Trino 397, Trino 398, Trino 399, Trino 400, and Trino 401.
Concept of the week: Intro to Hudi and the Hudi connector
This week we’re talking about the Hudi connector that was added in version 398.
What is Apache Hudi?
Apache Hudi (pronounced “hoodie”) is a streaming data lakehouse platform by combining warehouse and database functionality. Hudi is a table format that enables transactions, efficient upserts/deletes, advanced indexing, streaming ingestion services, data clustering/compaction optimizations, and concurrency.
Hudi is not just a table format, but has many services aimed at creating efficient incremental batch pipelines. Hudi was born out of Uber and is used at companies like Amazon, ByteDance, and Robinhood.
Merge on read (MOR) and copy on write (COW) tables
The Hudi table format and services aim to provide a suite of tools that make Hudi adaptive to realtime and batch use cases on the data lake. Hudi will lay out data following merge on read, which optimizes writes over reads, and copy on write, which optimizes reads over writes.
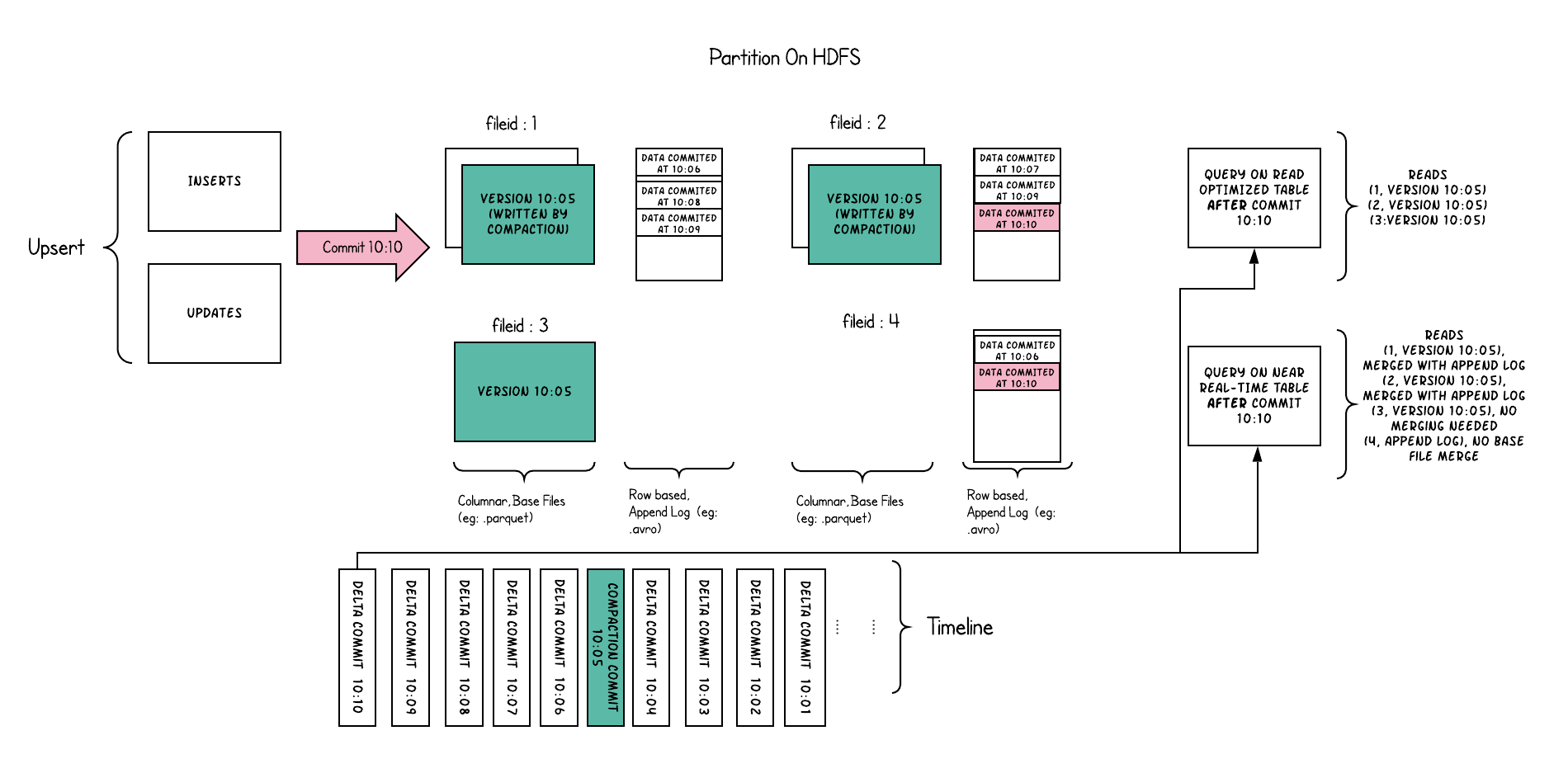
Hudi metadata table
The Hudi metadata table can improve read/write performance of your queries. The main purpose of this table is to eliminate the requirement for the “list files” operation. It is a result from how Hive-modelled SQL tables point to entire directories versus pointing to specific files with ranges. Using files with ranges help prune out files outside the query criteria.
Hudi data layout
Hudi uses multiversion concurrency control (MVCC), where compaction action merges logs and base files to produce new file slices a cleaning action gets rid of unused/older file slices to reclaim space on the file system.
Robinhood Trino and Hudi use cases
One of the well-known users of Trino and Hudi is Robinhood. Grace (Yue) Lu, who joined us at Trino Summit 2021, covers Robinhood’s architecture and use cases for Trino and Hudi.
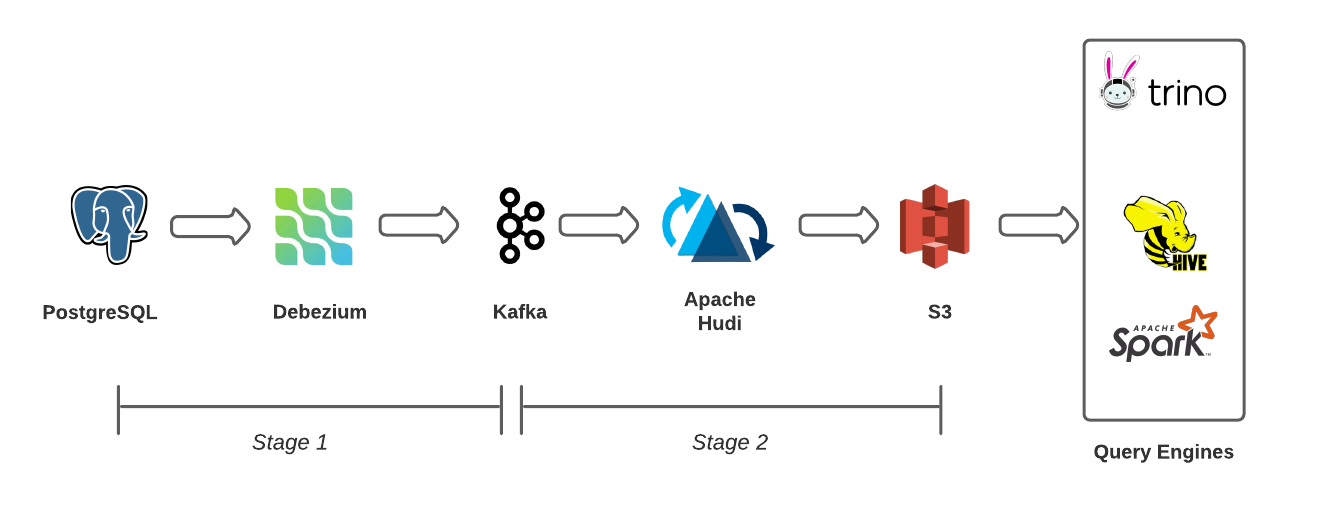
Robinhood ingests data via Debezium and streams it into Hudi. Then Trino is able to read data as it becomes available in Hudi.
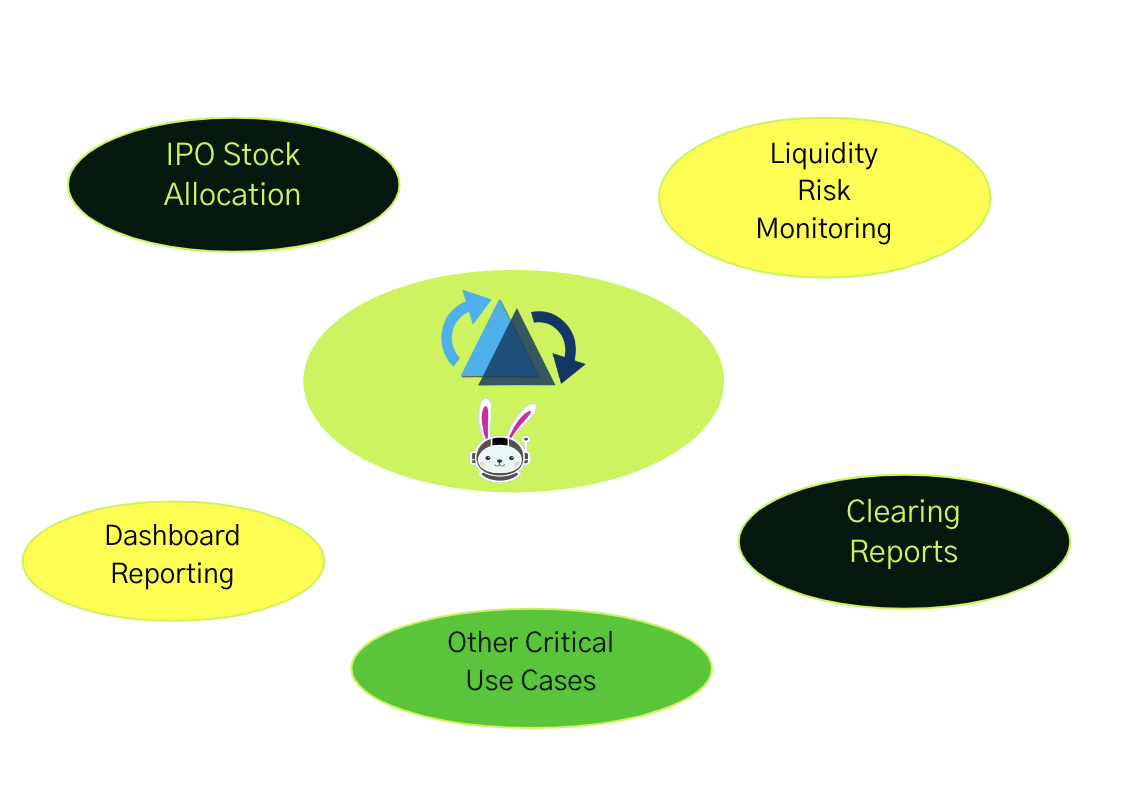
Hudi and Trino support critical use cases like IPO company stock allocation, liquidity risk monitoring, clearing settlement reports, and generally fresher metrics reporting and analysis.
The current state of the Trino Hudi connector
Before we had the official Hudi connector, many, like Robinhood, had to use the Hive connector. They were therefore not able to take advantage of the metadata table and many other optimizations Hudi provides out of the box.
The connector gets around that and now enables using some Hudi abstractions. However, the connector is currently limited to read-only mode and doesn’t support writes. Spark is the primary system used to stream data to Trino in Hudi. Check out the demo to see the connector in action.
Upcoming features in Hudi connector
First we want to get the read support improved and support all query types. As a next step we aim to add DDL support.
- The connector only supports copy on write tables, and soon we will add merge on read table support.
- Hudi has multiple query types. Adding snapshot querying support will be coming shortly.
- Integration with metadata table.
- Utilize the column statistics index.
PR 14445: Fault-tolerant execution for PostgreSQL and MySQL connectors
This PR of the episode was
contributed by Matthew Deady (@mwd410). The
improvements enable writes to PostgreSQL and MySQL when fault-tolerant execution
is enabled (retry-policy is set to TASK or QUERY). This update included a
few changes to core classes used for connectors using JDBC clients for Trino to
connect to the database. For example, Matthew was able to build on this PR by
adding a few additional changes to get this working in SQL Server in
PR 14730.
Thank you so much to Matthew for extending our fault-tolerant execution to connectors using JDBC clients! As usual, thanks to all the reviewers and maintainers who got these across the line!
Demo: Using the Hudi Connector
Let’s start up a local Trino coordinator and Hive metastore. Clone the
repository and navigate to the hudi/trino-hudi-minio directory. Then
start up the containers using Docker Compose.
git clone [email protected]:bitsondatadev/trino-getting-started.git
cd community_tutorials/hudi/trino-hudi-minio
docker-compose up -d
For now, you will need to import data using the Spark and Scala method we detail in the video. Eventually we will provide a SparkSQL in the near term, and update this to show the Trino DDL support when it lands.
SHOW CATALOGS;
SHOW SCHEMAS IN hudi;
SHOW TABLES IN hudi.default;
SELECT COUNT(*) FROM hudi.default.hudi_coders_hive;
SELECT * FROM hudi.default.hudi_coders_hive;
Events, news, and various links
Blog posts
Check out the in-person and virtual Trino Meetup groups.
If you want to learn more about Trino, check out the definitive guide from O’Reilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Slowikowski.