Video
- Release update: 404 Not Found (639s)
- Concept of the episode: Data caching and orchestration (998s)
- Concept of the episode: Trino without caching (1573s)
- Concept of the episode: What is Alluxio? (1785s)
- Concept of the episode: How does Alluxio work with table formats other than Hive? (2478s)
- Concept of the episode: Trino and Alluxio (4391s)
- PR of the episode: Alluxio/alluxio PR 13000 Add a doc for Trino (5463s)
- Demo of the episode: Running Trino on Alluxio (5675s)
Audio
Hosts
- Brian Olsen, Developer Advocate at Starburst (@bitsondatadev)
- Manfred Moser, Director of Information Engineering at Starburst (@simpligility)
Guests
- Bin Fan, VP of Open Source at Alluxio and PMC maintainer of Alluxio open source and TSC member of Presto (@binfan)
- Beinan Wang, Software Engineer at Alluxio and Presto committer

The Alluxio crew at Trino Summit 2022.
From left to right:
Beinan Wang,
Bin Fan,
Brian Olsen,
Denny Lee,
Hope Wang,
Jasmine Wang.
Somehow Denny Lee from Delta Lake snuck in there
😉. Love the data community vibes on this one.
Concept of the episode: Data caching and orchestration
Out of all those petabytes of data you store, only a small fraction of it is creating business value for you today. When you scan the same data multiple times and transfer it over the wire, you’re wasting time, compute cycles, and ultimately money. This gets worse when you’re pulling data across regions or clouds from disaggregate Trino clusters. In situations like these, caching solutions can make a tremendous impact on the latency and cost of your queries.
Trino without caching
There seems to be a sizeable portion of the community who aren’t using a caching solution. Not all workloads will really benefit from caching. If you are performing more writes than reads, the cache will need to constantly be invalidated before performing each read. If you are scanning all your data to run daily migrations, you would not benefit from caching. However, one of the most common use cases where Trino shines is interactive adhoc analytics. This type of querying is very fast in Trino, especially when using modern storage formats like Iceberg.
Two types of caching
There are two types of caching used with Trino. The first type caches the results of a common query or sub query to optimize performance for any query that overlaps with predicates to obtain the cached results.
The other type of query is object file caching. Rather than store the results of the query, you are caching the files from a file or object store that are scanned as part of the query.
In this episode, we will focus on the latter type of caching. This will apply to connectors like Hive, Iceberg, Delta Lake, and Hudi.
Hive connector caching
Trino has an embedded caching engine in the Hive connector. This is convenient as it ships with Trino, however, it does not work outside the Hive connector. The caching engine is Rubix. While this system works for simple Hive use cases, it fails to address use cases outside of Hive and hasn’t been maintained since 2020. There are many features missing like security features and support for more compute engines.
What is Alluxio?
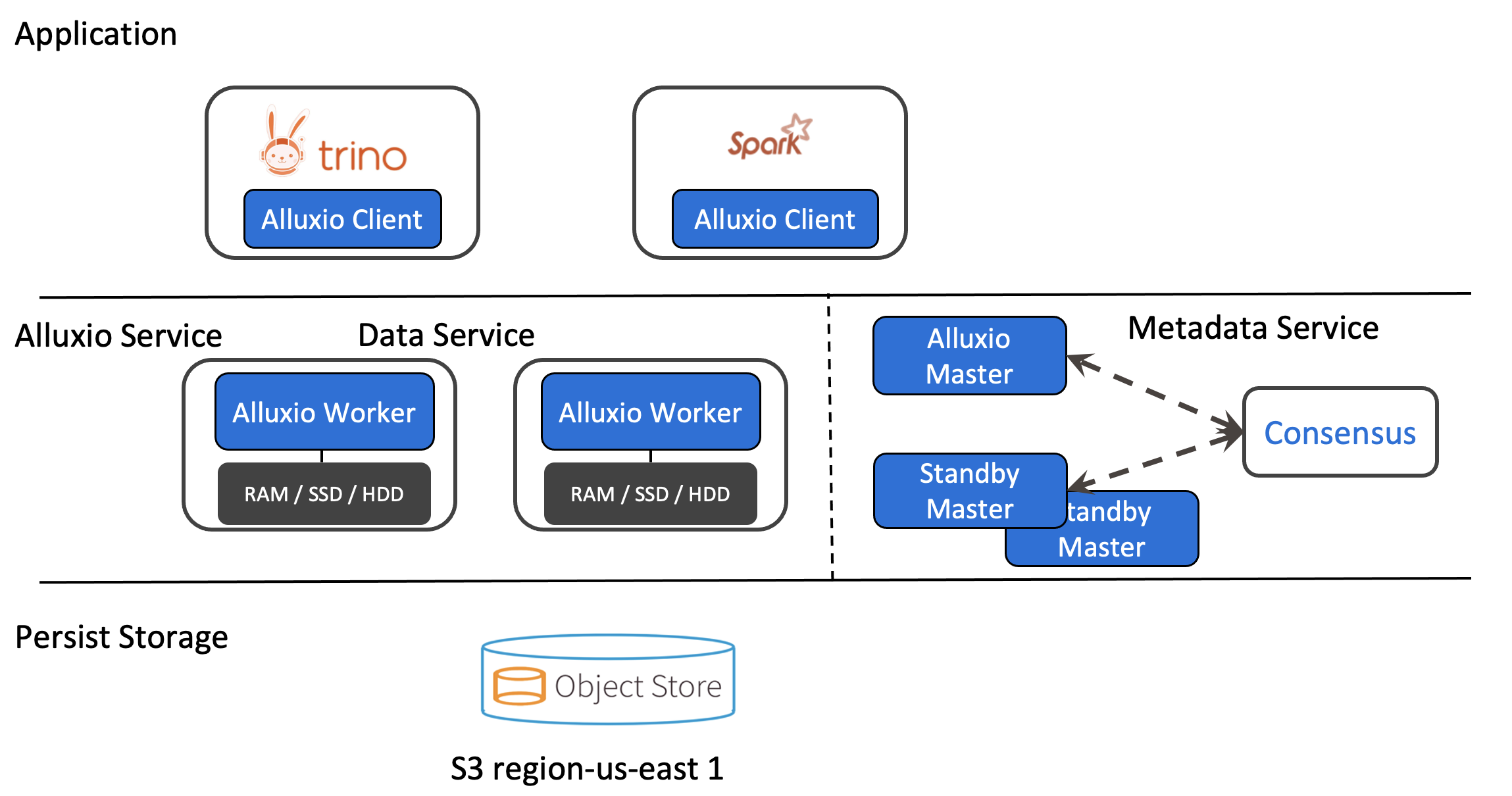
Alluxio is world’s first open source data orchestration technology for analytics and AI for the cloud. It provides a common interface enabling computation frameworks to connect to numerous storage systems through a common interface. Alluxio’s memory-first tiered architecture enables data access at speeds orders of magnitude faster than existing solutions. Alluxio was originally developed at Berkley Amp Labs, and was originally called Tachyon. It was less focused on caching and data orchestration and more focused on fault-tolerance via lineage and other techniques borrowed from Spark.
Alluxio lies between data driven applications, such as Trino and Apache Spark, and various persistent storage systems, such as Amazon S3, Google Cloud Storage, HDFS, Ceph, and MinIO. Alluxio unifies the data stored in these different storage systems, presenting unified client APIs and a global namespace to its upper layer data driven applications.
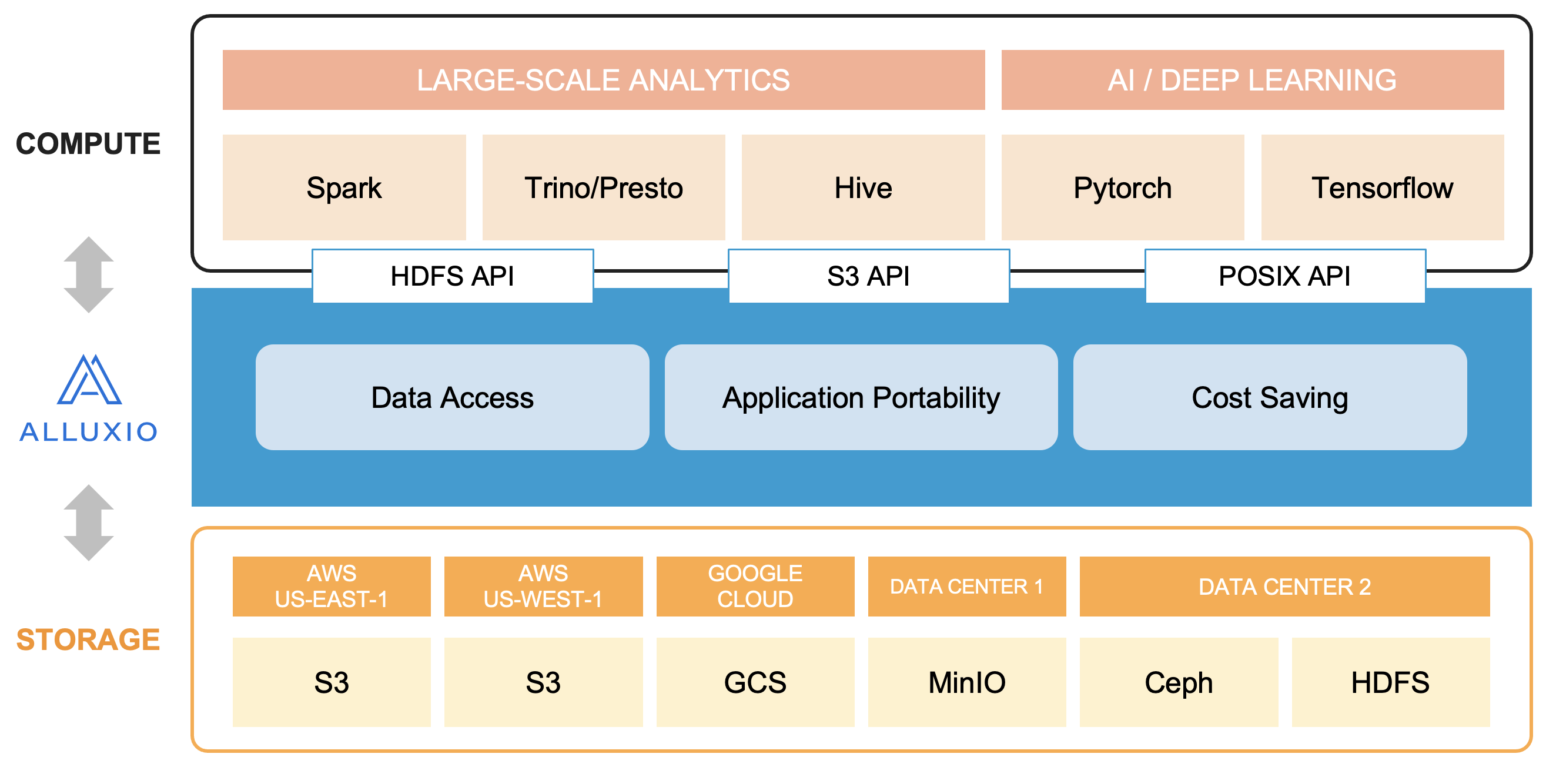
Alluxio is commonly used as a distributed shared caching service so compute engines talking to Alluxio can transparently cache frequently accessed data, especially from remote locations, to provide in-memory I/O throughput. Alluxio also enables unifying all data storage to a single namespace. This can make things simpler if your data is stored across different systems, have data stored in different regions, or stored across different clouds.
Source: https://docs.alluxio.io/os/user/stable/en/Overview.html
What is data orchestration?
A data orchestration platform abstracts data access across storage systems, virtualizes all the data, and presents the data via standardized APIs with global namespace to data-driven applications. In the meantime, it should have caching functionality to enable fast access to warm data. In summary, a data orchestration platform provides data-driven applications data accessibility, data locality, and data elasticity.
Source: https://www.alluxio.io/blog/data-orchestration-the-missing-piece-in-the-data-world/
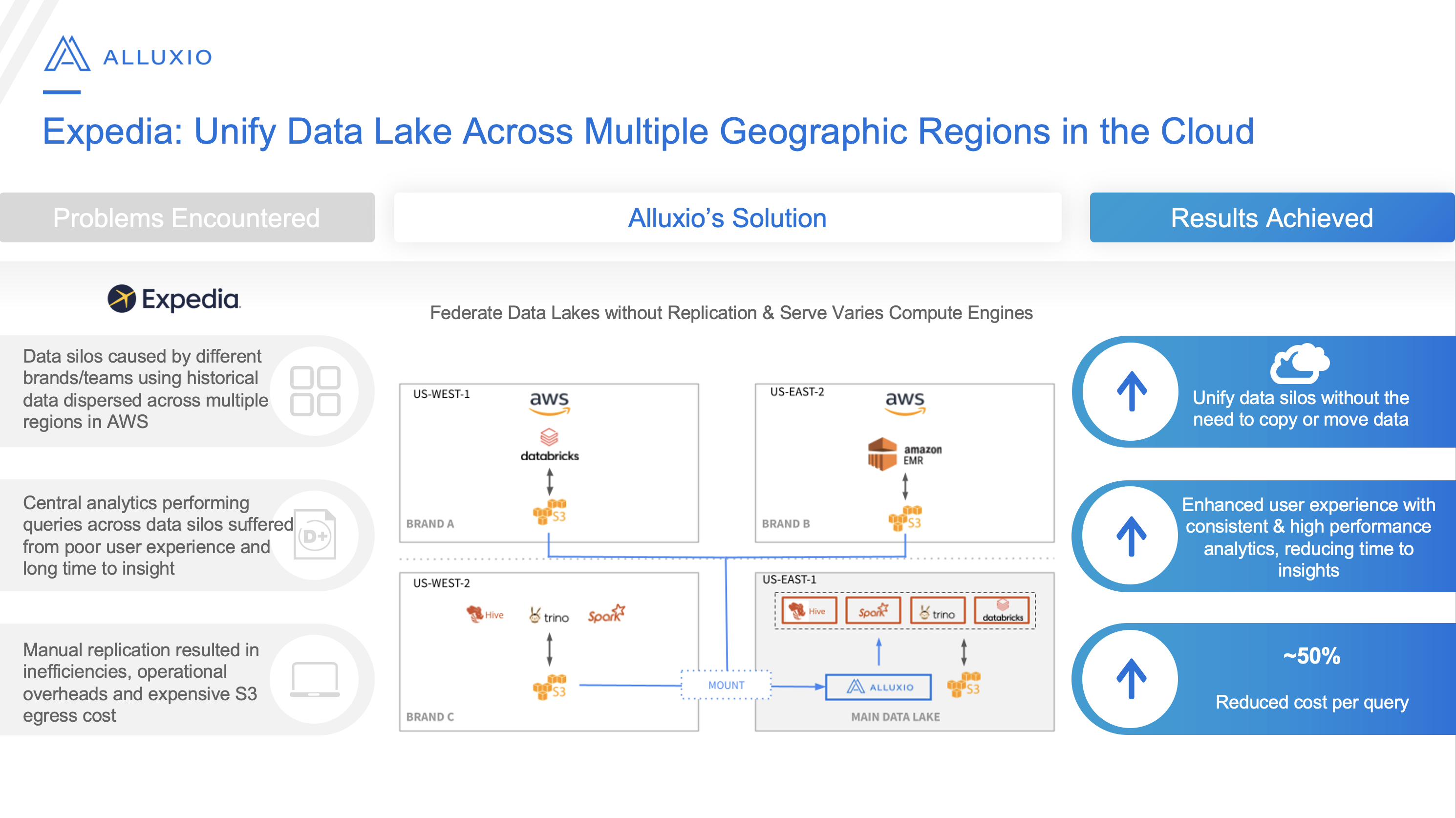
Trino and Alluxio: Expedia use case
Expedia needed to have the ability to query cross cluster over different regions while simplifying the interface to their local data sources.
PR of the episode: Alluxio/alluxio PR 13000 Add a doc for Trino
This episode’s PR is actually not located in a Trino repository. This PR comes from the Alluxio repository. It happened in the wake of the rebranding from Presto to Trino. PRs like this helped continue the Trino community as it grew awareness around the new name, as well as, fixed any potential issues that occurred with the hasty renaming we had to do.
This was submitted by Alluxio engineer, David Zhu. A huge thanks to David and his contributions to Trino as well!
Demo of the episode: Running Trino on Alluxio
This demo of the episode, covers how to configure Alluxio to use write-through caching to MinIO. This is done using the Iceberg connector with only one change to the location property on the table from the Trino perspective.
To follow this demo, copy the code located in the trino-getting-started repo.
Check out the in-person and virtual Trino Meetup groups.
If you want to learn more about Trino, check out the definitive guide from O’Reilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Slowikowski.