Video
- Trino Release: 407 (802s)
- Concept of the episode: What is workflow orchestration? (1272s)
- Concept of the episode: Why do we need a workflow orchestration tool for building a data lake? (1867s)
- Concept of the episode: What is Apache DolphinScheduler? (2255s)
- Concept of the episode: Does DolphinScheduler have any computing engine or storage layer? (3191s)
- Concept of the episode: What are the differences to other workflow orchestration systems (3526s)
- Demo of the episode: Creating a simple Trino workflow in DolphinScheduler (5204s)
- PR of the episode: Improve performance of Parquet files (6424s)
Audio
Hosts
- Brian Olsen, Developer Advocate at Starburst (@bitsondatadev)
- Cole Bowden, Developer Advocate at Starburst
Guests
- David Zollo, Apache DolphinScheduler PMC Chair
- Jay Chung, Apache DolphinScheduler PMC Member
- Niko Zeng, Apache DolphinScheduler Community Manager
- William Guo, Apache Software Foundation Member
Recap of Trino in 2022
Highlights from the blog post The rabbit reflects on Trino in 2022 touch upon various aspects.
Release 407
Official highlights from Martin Traverso:
- Improved performance for highly selective queries.
- Improved performance when reading numeric, string and timestamp values from Parquet files.
- New
querytable function for full query pass-through in Cassandra. - New
unregister_tableprocedure in Delta Lake and Iceberg. - Support for writing to the change data feed in Delta Lake.
Cole’s comments:
- For our contributors, we added a new action to track and ping the developer relations team on stale pull requests to further prompt maintainers to take a look. This doesn’t have any immediate impact on end users, but it’ll improve the development and contribution process.
- A Kerberos fix for the Kudu connector should make using it much less of a headache on long-running Trino instances.
- There were some really sophisticated performance improvements that came from shifting default config values and adding some new ones, all of which took a whole lot of testing.
More detailed information is available in the release notes for Trino 407.
What is workflow orchestration?
Workflow orchestration refers to the process of coordinating and automating complex sequence of operations known as workflows consisting of multiple interdependent tasks. This involves designing and defining the workflow, scheduling and executing the tasks, monitoring the progress and outcomes, and handling any errors or exceptions that may arise. In the context of Trino, the tasks are typically the processing of SQL queries on one or more Trino cluster and other related systems to create a data pipeline or similar automation.
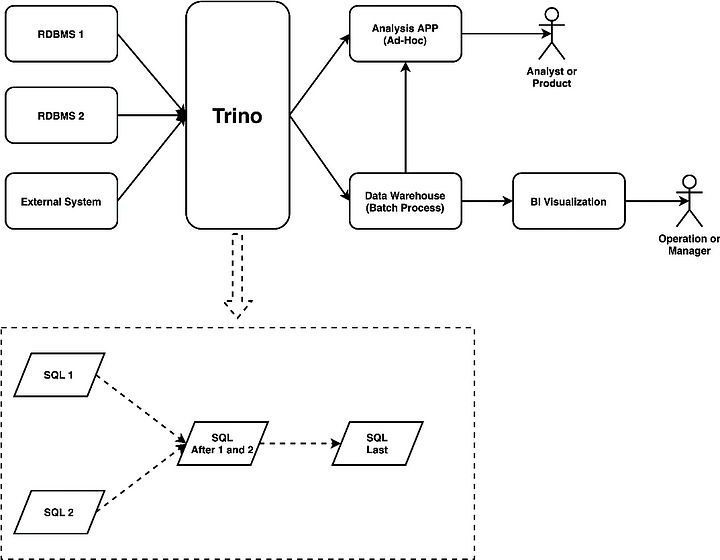
Why do we need a workflow orchestration tool for building a data lake?
Building a data lake can involve many complex and interdependent data processing tasks, which can be challenging to manage and scale without a workflow orchestration tool. Sometimes we can consider tools like Trino at the center of the universe, and perhaps it would be easier to schedule SQL queries with a much simpler tool. Most companies, however, require a larger variety of tasks to build a data lake that interoperate on more than just running SQL on Trino. Even if you primarily run Trino SQL scripts to run these jobs, it is better to have an orchestration tool instead of managing all processes manually.
What is Apache DolphinScheduler?
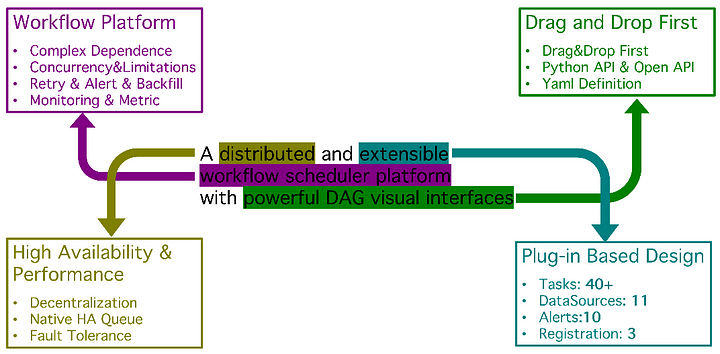
Apache DolphinScheduler is an open-source, distributed workflow scheduling platform designed to manage and execute batch jobs, data pipelines, and ETL processes. DolphinScheduler enables users to create and manage consecutive jobs run easily, including support for different types of tasks, such as SQL statements, shell scripts, Spark jobs, Kubernetes deployments, and many others. In short, it’s a powerful and user-friendly workflow orchestration platform that enables users to automate and manage their complex data processing tasks.
Read this blog on Trino and Apache DolphinScheduler to find out more.
Does DolphinScheduler have any computing engine or storage layer?
DolphinScheduler is a powerful tool for managing and orchestrating data processing workflows across a range of computing engines and storage systems, but it does not provide its own computing or storage capabilities.
What are the differences to other workflow orchestration systems?
Airflow is the incumbent de facto workload orchestrator. Many data engineers currently rely on Airflow to handle their workflow orchestration today so it helps to understand DolphinScheduler’s benefits in relation to Airflow. Both Dolphin Scheduler and Airflow are designed to be scalable and highly available to support large-scale distributed environments.
Airflow supports a wide range of third-party integrations, including popular data processing frameworks such as Trino, Spark, and Flink, as well as with cloud services such as AWS and Google Cloud. Dolphin Scheduler supports a similar range of data processing frameworks and tools. This makes both platforms suitable for managing diverse data processing tasks.
DolphinScheduler project believes that future data governance belongs to data engineers and consumers alike and should not be centralized to a single team. Product-focused engineering teams should have access to data and be able to orchestrate workflows without the need for extensive coding skills. DolphinScheduler uses a drag and drop web UI to create and manages workflows while also providing programmatic access using tools like Python SDK and Open API.
A positive feature of DolphinScheduler supporting users outside the data team through a UI is that it offers robust security features. This includes authentication, authorization, and data encryption, to ensure that users’ data and workflows are protected.
DolphinScheduler has relatively limited documentation and community support since they are a newer project, but they are working hard to improve the developer experience and documentation.
How does DolphinScheduler deal with failures?
Failure is an inevitable aspect of data workflow orchestration. The merits of many of these orchestration tools come from how well they aid users in responding to failures by monitoring health and notifying users when things go wrong.
Does DolphinScheduler have an alarm mechanism itself?
Apache DolphinScheduler supports user notifications as part of a workflow. This mechanism is designed to help users monitor and manage their workflows more effectively and respond quickly to any issues.
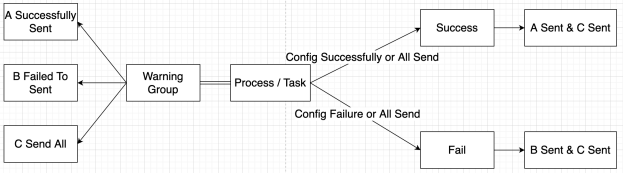
These alerts can be configured to notify users via email, SMS, or other communication channels, and can include details such as the name of the workflow, the name of the failed task, and the error message or stack trace associated with the failure.
In addition to these configurable alerts, DolphinScheduler provides a dashboard for monitoring the status and progress of workflows and tasks. It includes real-time updates and visualizations of workflow performance and status. The dashboard helps users quickly identify any issues or bottlenecks in their workflows and take corrective action as needed.
Demo of the episode: Creating a simple Trino workflow in DolphinScheduler
For this episodes’ demo, we look at creating a workflow consisting of a Trino query execution managed by a workflow in DolphinScheduler.
Run the demo by following the steps listed.
PR of the episode: Improve performance of Parquet files
While we’re on the topic of data lakes, we had several performance for Parquet files in release 407 from contributor and maintainer, @raunaqmorarka. This change includes an improvement on performance of reading Parquet files for decimal types, numeric types, string types, timestamp and boolean types.
While Trino has historically had better performance for the ORC format, the Parquet file type has grown drastically in popularity and so this is one of many examples of the improving support around Parquet files for data lakes.
Find out more about DolphinScheduler
- https://dolphinscheduler.apache.org/
- https://github.com/apache/dolphinscheduler
- https://twitter.com/dolphinschedule
Trino events
If you have an event that is related to Trino, let us know so we can add it to the Trino events calendar.
Rounding out
Check out the in-person and virtual Trino Meetup groups.
If you want to learn more about Trino, get the definitive guide from O’Reilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Slowikowski.