Video
- Concept of the week: Cost Based Optimizer (1008s)
- PR of the week: PR 1415 Decorrelate subqueries with Limit or TopN (2589s)
- PR Demo: EXPLAIN Decorrelate subqueries with Limit or TopN (3216s)
- Question of the week: Will running Presto on my relational database make processing faster? (3744s)
Audio
Release 348
Release Notes discussed: https://prestosql.io/docs/current/release/release-348.html
Martin’s announcement:
- Support for OAuth2 authorization in Web UI
- Support for S3 streaming uploads
- Support for DISTINCT aggregations in correlated subqueries
- Performance improvement for ORDER BY … LIMIT queries
- Many improvements and bug fixes to JDBC driver
Manfred’s observations:
- SHOW STATS to play around with
- switch for Hive view translation off, legacy or new coral system
- a bunch of other Hive connector improvements
- Iceberg on GCP and Azure
- Small SPI changes
Concept of the week: Cost Based Optimizer
We’re continuing our series covering some fundamental topics that build up to dynamic filtering! This week we’re discussing the cost-based optimizer with Presto co-creator Martin Traverso!
Parser/Analyzer
To recap, in episode 6 we discussed a little bit about the various forms a query takes from submission to the coordinator, to actually being executed. We discussed how the parser generates an abstract syntax tree (AST) and the analyzer checks for valid SQL including functions and making sure tables and columns being referenced actually exist.
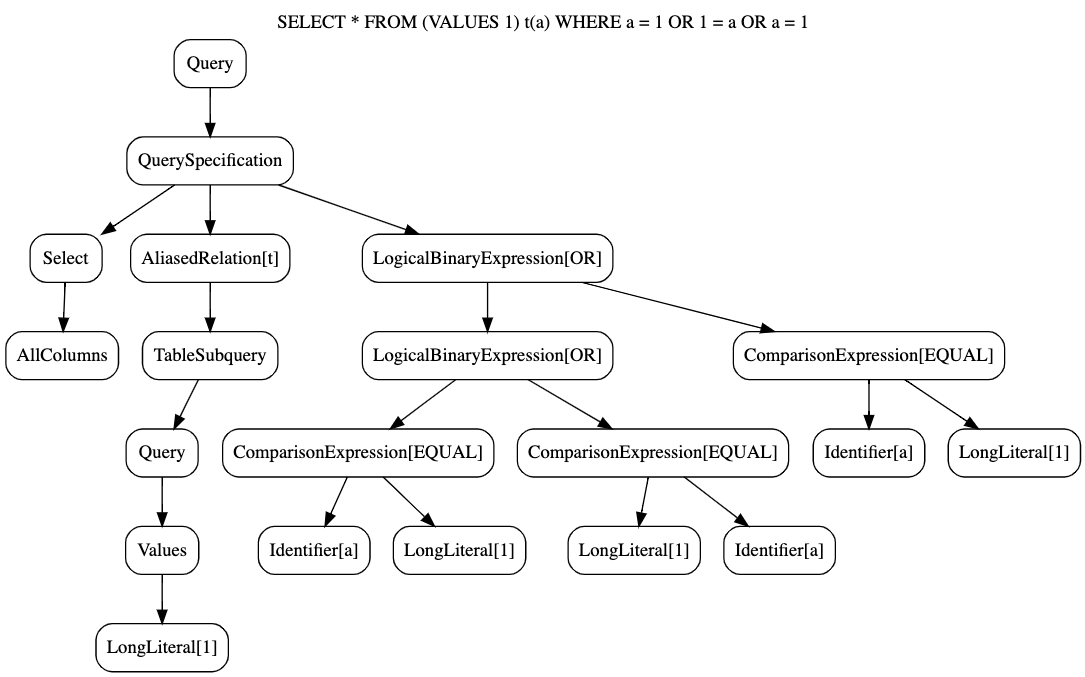
Here’s an example of an abstract syntax tree from last weeks episode for query
SELECT * FROM (VALUES 1) t(a) WHERE a = 1 OR 1 = a OR a = 1;.
Planner
The next phase we discussed was the planner. Internally, the planner and optimizer overlap substantially, but you can think of the planner as the early part of the planning phase that generates the logical query, and over several optimization iterations becomes an optimized distributed query. The planner generates a new tree data structure called the plan IR (intermediate representation) that contains nodes representing the steps that need to be performed in order to answer the query. The leaves of the tree get executed first, and the parents of each node are dependent on the action of its child completing before it can start.
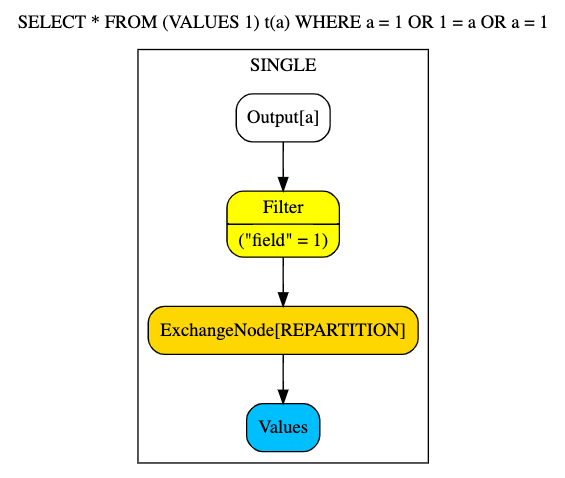
Here’s ab example of a logical plan tree using the same query form the AST above. Since this query isn’t pulling from a data source, the distributed plan is equivalent to the logical plan.
Cost-Based Optimizer (CBO)
In the cost-based optimizer phase, there are various rules that are applied to the Plan IR that slowly optimize the structure into the final distributed plan that is then executed. To do this, the optimizer retrieves some statistical metadata of the tables and their data. This information includes, table row counts, column data size, column low/high value, distinct column value count, and the percentage of null values in a column. With the list of rules that aim to leverage these statistics, the optimizer improves the query structure that improves on parallelism based on the number of workers to the number of sources.
If you want to jump into the code, start at the entry point for the planner/optimizer and the initial planning starts on this line. This loop is where the actual optimization occurs. So if you are interested, maybe grab a brandy 🥃 and take some time to set your debugger at these points and watch the optimizer do its thing!
Refer to chapter 4 in Trino: The Definitive Guide pg. 50.
PR of the week: PR 1415 Decorrelate subqueries with Limit or TopN
In this week’s pull request https://github.com/prestosql/presto/pull/1415, done by Presto contributer and Starburst Engineer kasiafi.
Before we can jump into this PR, let’s discuss what a subquery is and further
what a correlated subquery is. In SQL you have a nested query that runs within
another query, typically embedded within a WHERE clause or SELECT statement.
Take this query for example:
SELECT a, b, c
FROM table
WHERE a > (SELECT t2.a FROM table2 t2 WHERE t2.d < 60);In this example, we have a standard non-correlated subquery that runs on
table2. The reason it is not correlated is because there are no dependencies
on the parent query that is being run on table. This type of query enables the
SQL engine to run the subquery first and then use those results to run the
parent query after. In the case of a correlated query, you typically have at
least one criterion in the nested query that depends on the parent. This
requires that the nested query gets executed for each row of the parent query.
Take a look at this correlated query:
SELECT a, b, c
FROM table t1
WHERE a > (SELECT t2.a FROM table2 t2 WHERE t2.d < 60 AND t1.b <> t2.b);In this example, we are running the subquery in the context of the row in order
to evaluate the value of t1.b. Having this query run for every row of the
parent query is certainly not ideal if it is not required and that is why
subquery decorrelation is a common optimization technique if an equivalent
non-correlated subquery exists for a given correlated subquery.
This pull request adds a rule that added the ability for Presto to handle the
decorrelation of a subquery containing a LIMIT or (ORDER + LIMIT i.e.
TopN) clauses. So, the common trick during decorrelation is to turn it into a
query that can process the results from the inner table in one shot. The
approach is to flatten the results of executing the subquery for every row into
a single stream of rows before it is finally ready for execution.
This change also applies to a LATERAL join, which behaves a lot like a nested
subquery only that it acts as a table and returns multiple rows instead of
just a single row.
PR Demo: PR 1415 Decorrelate subqueries with Limit or TopN
SELECT (
SELECT t.a
FROM (VALUES 1, 2, 3) t(a)
WHERE t.a = t2.b
LIMIT 2
)
FROM (VALUES 1) t2(b);
SELECT (
SELECT t.a
FROM (VALUES (1, 2), (1, 3)) t(a, b)
WHERE t.a = t2.a AND t2.b > 1
LIMIT 1
) FROM (VALUES (1, 2)) t2(a, b);
SELECT (
SELECT t.b
FROM (VALUES (1, 2), (1, 3)) t(a, b)
WHERE t.a = t2.a AND t2.b > 1
ORDER BY t.b
LIMIT 1
) FROM (VALUES (1, 2)) t2(a, b)
### Fails
# 1) Returns more than one row from subquery.
# This query actually fails on execution on not during planning/optimizing where
# the other two below fail .
SELECT (
SELECT t.a
FROM (VALUES 1, 1, 2, 3) t(a)
WHERE t.a = t2.b
LIMIT 2
)
FROM (VALUES 1) t2(b);
# 2) Limit and correlated non-equality predicate in the subquery
SELECT (
SELECT t.b
FROM (VALUES (1, 2), (1, 3)) t(a, b)
WHERE t.a = t2.a AND t.b > t2.b
LIMIT 1
) FROM (VALUES (1, 2)) t2(a, b);
# 3) TopN and correlated non-equality predicate in the subquery
SELECT (
SELECT t.b
FROM (VALUES (1, 2), (1, 3)) t(a, b)
WHERE t.a = t2.a AND t.b > t2.b
ORDER BY t.b
LIMIT 1
) FROM (VALUES (1, 2)) t2(a, b)After the show Kasia pointed out that the failing queries were not all failing for the same reason. The first failing query above actually gets planned and executed, but the exception occurs during the execution. The rest actually fail during the planning and optimization phase as they were unable to be decorrelated due to the issue I line out in the comments above.
Question of the week:
In this week’s question, we answer: Will running Presto on my relational database make processing faster?
I have been going over the docs of PrestoSQL and it seems to fit some of my requirements. I am little concerned about the resources needed to run Presto in production. Because the size of my prod data is between 3-5GB and there will be very minimal data growth. Is Presto suitable for such a small data size?
Many times, the idea that Presto is fast gets conflated with the idea that Presto is a good fit for all use cases. It is important to understand that Presto is a) not a database b) not developed for OLTP workloads and c) built to handle data at the scale of Terabytes to Petabytes over distributed queries. Since Presto uses a connector framework, it also has an added benefit of running federated queries to whatever data source that returns data that can be represented in some columnar fashion.
For relatively small size data sets you should try directly using your relational database first. Doing this is better for small data sets. Database indexes are really nice if you’re not in big data world and if you give your SQL Server say 10 GB memory, it should be running fully in-memory and thus — fast.
Events, news, and various links
Blogs
- https://prestosql.io/blog/2019/05/21/optimizing-the-casts-away.html
- https://towardsdatascience.com/statistics-in-spark-sql-explained-22ec389bf71b
- https://www.infoworld.com/article/3597971/on-premises-data-warehouses-are-dead.html
- https://www.javahelps.com/2019/11/presto-sql-join-algorithms.html
Upcoming events
- Dec 16 https://www.evanta.com/cdo/boston/2020-boston-cdo-virtual-executive-summit
- Feb 9 - Feb 10 http://starburstdata.com/datanova
Latest training from David, Dain, and Martin(Now with timestamps!):
- https://prestosql.io/blog/2020/07/15/training-advanced-sql.html
- https://prestosql.io/blog/2020/07/30/training-query-tuning.html
- https://prestosql.io/blog/2020/08/13/training-security.html
- https://prestosql.io/blog/2020/08/27/training-performance.html
Presto Summit Series - Real world usage
- https://prestosql.io/blog/2020/05/15/state-of-presto.html
- https://prestosql.io/blog/2020/06/16/presto-summit-zuora.html
- https://prestosql.io/blog/2020/07/06/presto-summit-arm-td.html
- https://prestosql.io/blog/2020/07/22/presto-summit-pinterest.html
Podcasts:
- Presto with Martin Traverso, Dain Sundstrom and David Phillips
- Simplify Your Data Architecture With The Presto Distributed SQL Engine
- How Open Source Presto Unlocks a Single Point of Access to Data
- The Data Access Struggle is Real
- Presto with Justin Borgman
- The infrastructure renaissance and how it will power the modernization of analytics platforms
- Uber’s Data Platform with Zhenxiao Luo
If you want to learn more about Presto yourself, you should check out the O’Reilly Trino Definitive guide. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.