
Welcome to the Trino on ice series, covering the details around how the Iceberg table format works with the Trino query engine. The examples build on each previous post, so it’s recommended to read the posts sequentially and reference them as needed later. Here are links to the posts in this series:
- Trino on ice I: A gentle introduction to Iceberg
- Trino on ice II: In-place table evolution and cloud compatibility with Iceberg
- Trino on ice III: Iceberg concurrency model, snapshots, and the Iceberg spec
- Trino on ice IV: Deep dive into Iceberg internals
The first post covered how Iceberg is a table format and not a file format It demonstrated the benefits of hidden partitioning in Iceberg in contrast to exposed partitioning in Hive. There really is no such thing as “exposed partitioning.” I just thought that sounded better than not-hidden partitioning. If any of that wasn’t clear, I recommend either that you stop reading now, or go back to the first post before starting this one. This post discusses evolution. No, the post isn’t covering Darwinian nor Pokémon evolution, but in-place table evolution!

You may find it a little odd that I am getting excited over tables evolving in-place, but as mentioned in the last post, if you have experience performing table evolution in Hive, you’d be as happy as Ash Ketchum when Charmander evolved into Charmeleon discovering that Iceberg supports Partition evolution and schema evolution. That is, until Charmeleon started treating Ash like a jerk after the evolution from Charmander. Hopefully, you won’t face the same issue when your tables evolve.
Another important aspect that is covered, is how Iceberg is developed with cloud storage in mind. Hive and other data lake technologies were developed with file systems as their primary storage layer. This is still a very common layer today, but as more companies move to include object storage, table formats did not adapt to the needs of object stores. Let’s dive in!
Partition Specification evolution #
In Iceberg, you are able to update the partition specification, shortened to partition spec in Iceberg, on a live table. You do not need to perform a table migration as you do in Hive. In Hive, partition specs don’t explicitly exist because they are tightly coupled with the creation of the Hive table. Meaning, if you ever need to change the granularity of your data partitions at any point, you need to create an entirely new table, and move all the data to the new partition granularity you desire. No pressure on choosing the right granularity or anything!
In Iceberg, you’re not required to choose the perfect partition specification upfront, and you can have multiple partition specs in the same table, and query across the different sized partition specs. How great is that! This means, if you’re initially partitioning your data by month, and later you decide to move to a daily partitioning spec due to a growing ingest from all your new customers, you can do so with no migration, and query over the table with no issue.
This is conveyed pretty succinctly in this graphic from the Iceberg documentation. At the end of the year 2008, partitioning occurs at a monthly granularity and after 2009, it moves to a daily granularity. When the query to pull data from December 14th, 2008 and January 13th, 2009, the entire month of December gets scanned due to the monthly partition, but for the dates in January, only the first 13 days are scanned to answer the query.
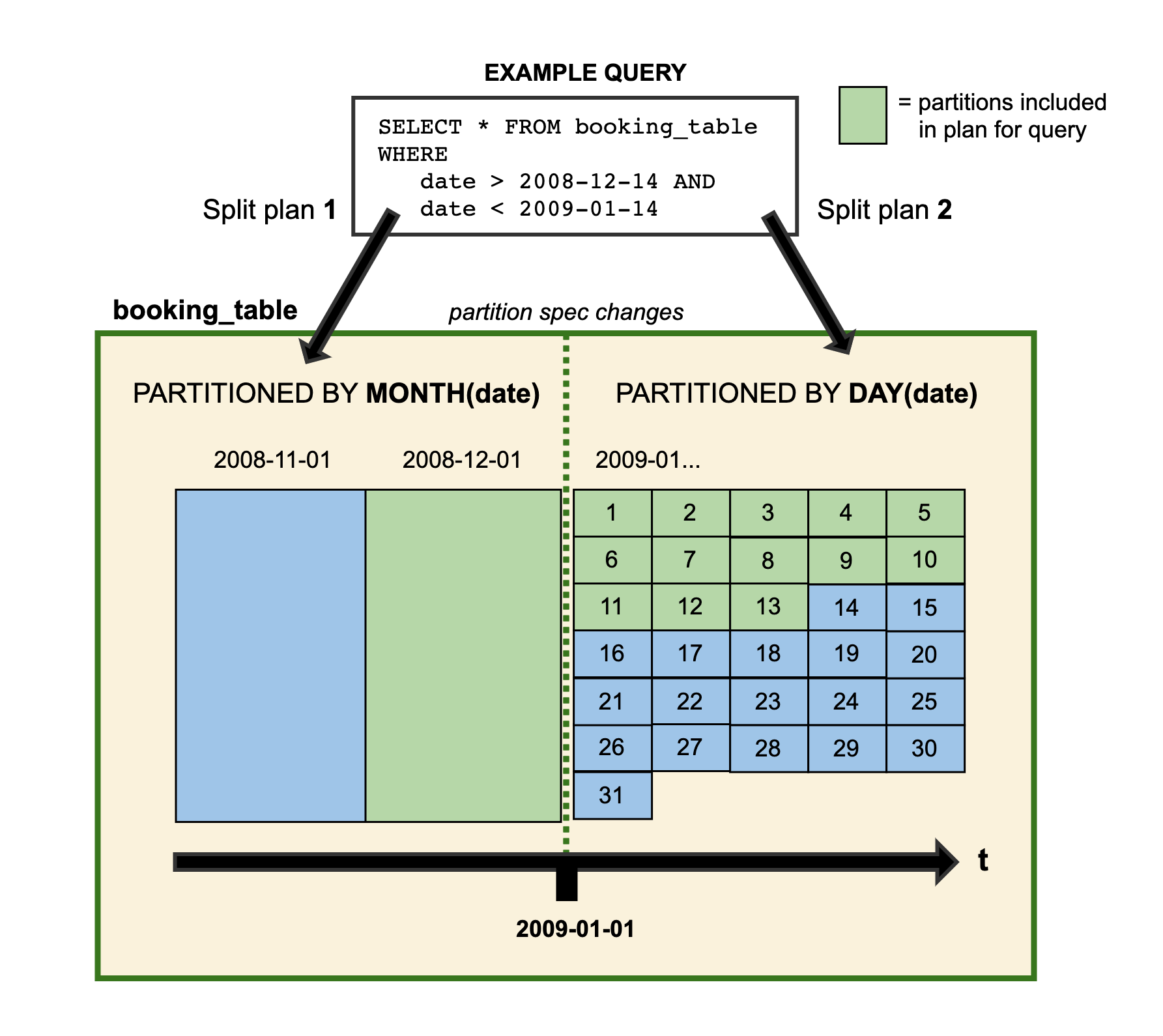
At the time of writing, Trino is able to perform reads from tables that have multiple partition spec changes but partition evolution write support does not yet exist. There are efforts to add this support in the near future.
Schema evolution #
Iceberg also handles schema evolution much more elegantly than Hive. In Hive, adding columns worked well enough, as data inserted before the schema change just reports null for that column. For formats that use column names, like ORC and Parquet, deletes are also straightforward for Hive, as it simply ignores fields that are no longer part of the table. For unstructured files like CSV that use the position of the column, deletes would still cause issues, as deleting one column shifts the rest of the columns. Renames for schemas pose an issue for all formats in Hive as data written prior to the rename is not modified to the new field. This effectively works the same as if you deleted the old field and added a new column with the new name. This lack of support for schema evolution across various file types in Hive requires a lot of memorizing the formats underneath various tables. This is very susceptible to causing user errors if someone executes one of the unsupported operations on the wrong table.
| Hive 2.2.0 schema evolution based on file type and operation. | |||
|---|---|---|---|
| Add | Delete | Rename | |
| CSV/TSV | ✅ | ❌ | ❌ |
| JSON | ✅ | ✅ | ❌ |
| ORC/Parquet/Avro | ✅ | ✅ | ❌ |
Currently in Iceberg, schemaless position-based data formats such as CSV and TSV are not supported, though there are some discussions on adding limited support for them. This would be good from a reading standpoint, to load data from the CSV, into an Iceberg format with all the guarantees that Iceberg offers.
While JSON doesn’t rely on positional data, it does have an explicit dependency
on names. This means, that if I remove a text column from a JSON table named
severity, then later I want to add a new int column called severity, I
encounter an error when I try to read in the data with the string type from
before when I try to deserialize the JSON files. Even worse would be if the new
severity column you add has the same type as the original but a semantically
different meaning. This results in old rows containing values that are
unknowingly from a different domain, which can lead to wrong analytics. After
all, someone who adds the new severity column might not even be aware of the
old severity column, if it was quite some time ago when it was dropped.
ORC, Parquet, and Avro do not suffer from these issues as they are columnar formats that keep a schema internal to the file itself, and each format tracks changes to the columns through IDs rather than name values or position. Iceberg uses these unique column IDs to also keep track of the columns as changes are applied.
In general, Iceberg can only allow this small set of file formats due to the
correctness guarantees it
provides. In Trino, you can add, delete, or rename columns using the
ALTER TABLE command. Here’s an example that continues from the table created
in the last post that inserted three rows. The DDL statement looked like this.
CREATE TABLE iceberg.logging.events (
level VARCHAR,
event_time TIMESTAMP(6),
message VARCHAR,
call_stack ARRAY(VARCHAR)
) WITH (
format = 'ORC',
partitioning = ARRAY['day(event_time)']
);
Here is an ALTER TABLE sequence that adds a new column named severity,
inserts data including into the new column, renames the column, and prints the
data.
ALTER TABLE iceberg.logging.events ADD COLUMN severity INTEGER;
INSERT INTO iceberg.logging.events VALUES
(
'INFO',
timestamp
'2021-04-01 19:59:59.999999' AT TIME ZONE 'America/Los_Angeles',
'es muy bueno',
ARRAY ['It is all normal'],
1
);
ALTER TABLE iceberg.logging.events RENAME COLUMN severity TO priority;
SELECT level, message, priority
FROM iceberg.logging.events;
Result:
| level | message | priority |
|---|---|---|
| ERROR | Double oh noes | NULL |
| WARN | Maybeh oh noes? | NULL |
| ERROR | Oh noes | NULL |
| INFO | es muy bueno | 1 |
ALTER TABLE iceberg.logging.events
DROP COLUMN priority;
SHOW CREATE TABLE iceberg.logging.events;
Result
CREATE TABLE iceberg.logging.events (
level varchar,
event_time timestamp(6),
message varchar,
call_stack array(varchar)
)
WITH (
format = 'ORC',
partitioning = ARRAY['day(event_time)']
)
Notice how the priority and severity columns are both not present in the schema. As noted in the table above, Hive renames cause issues for all file formats. Yet in Iceberg, performing all these operations causes no issues with the table and underlying data.
Cloud storage compatibility #
Not all developers consider or are aware of the performance implications of using Hive over a cloud object storage solution like S3 or Azure Blob storage. One thing to remember is that Hive was developed with the Hadoop Distributed File System (HDFS) in mind. HDFS is a filesystem and is particularly well suited to handle listing files on the filesystem, because they were stored in a contiguous manner. When Hive stores data associated with a table, it assumes there is a contiguous layout underneath it and performs list operations that are expensive on cloud storage systems.
The common cloud storage systems are typically object stores that do not lay out the files in a contiguous manner based on paths. Therefore, it becomes very expensive to list out all the files in a particular path. Yet, these list operations are executed for every partition that could be included in a query, regardless of only a single row, in a single file out of thousands of files needing to be retrieved to answer the query. Even ignoring the performance costs for a minute, object stores may also pose issues for Hive due to eventual consistency. Inserting and deleting can cause inconsistent results for readers, if the files you end up reading are out of date.
Iceberg avoids all of these issues by tracking the data at the file level, rather than the partition level. By tracking the files, Iceberg only accesses the files containing data relevant to the query, as opposed to accessing files in the same partition looking for the few files that are relevant to the query. Further, this allows Iceberg to control for the inconsistency issue in cloud-based file systems by using a locking mechanism at the file level. See the file layout below that Hive layout versus the Iceberg layout. As you can see in the next image, Iceberg makes no assumptions about the data being contiguous or not. It simply builds a persistent tree using the snapshot (S) location stored in the metadata, that points to the manifest list (ML), which points to manifests containing partitions (P). Finally, these manifest files contain the file (F) locations and stats that can quickly be used to prune data versus needing to do a list operation and scanning all the files.
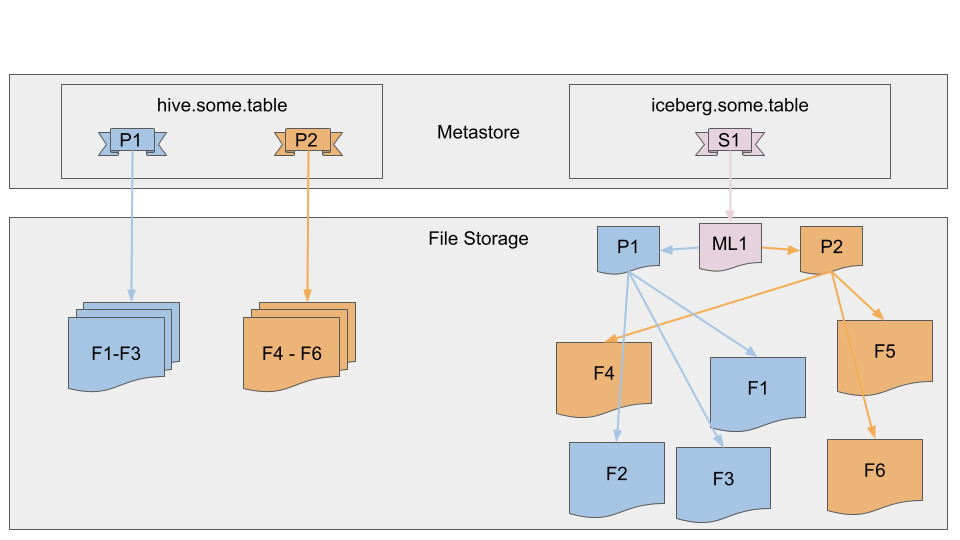
Referencing the picture above, if you were to run a query where the result set only contains rows from file F1, Hive would require a list operation and scanning the files, F2 and F3. In Iceberg, file metadata exists in the manifest file, P1, that would have a range on the predicate field that prunes out files F2 and F3, and only scans file F1. This example only shows a couple of files, but imagine storage that scales up to thousands of files! Listing becomes expensive on files that are not contiguously stored in memory. Having this flexibility in the logical layout is essential to increase query performance. This is especially true on cloud object stores.
If you want to play around with Iceberg using Trino, check out the Trino Iceberg docs. To avoid issues like the eventual consistency issue, as well as other problems of trying to sync operations across systems, Iceberg provides optimistic concurrency support, which is covered in more detail in the next post.