
Welcome to the Trino on ice series, covering the details around how the Iceberg table format works with the Trino query engine. The examples build on each previous post, so it’s recommended to read the posts sequentially and reference them as needed later. Here are links to the posts in this series:
- Trino on ice I: A gentle introduction to Iceberg
- Trino on ice II: In-place table evolution and cloud compatibility with Iceberg
- Trino on ice III: Iceberg concurrency model, snapshots, and the Iceberg spec
- Trino on ice IV: Deep dive into Iceberg internals
So far, this series has covered some very interesting user level concepts of the Iceberg model, and how you can take advantage of them using the Trino query engine. This blog post dives into some implementation details of Iceberg by dissecting some files that result from various operations carried out using Trino. To dissect you must use some surgical instrumentation, namely Trino, Avro tools, the MinIO client tool and Iceberg’s core library. It’s useful to dissect how these files work, not only to help understand how Iceberg works, but also to aid in troubleshooting issues, should you have any issues during ingestion or querying of your Iceberg table. I like to think of this type of debugging much like a fun game of operation, and you’re looking to see what causes the red errors to fly by on your screen.

Understanding Iceberg metadata #
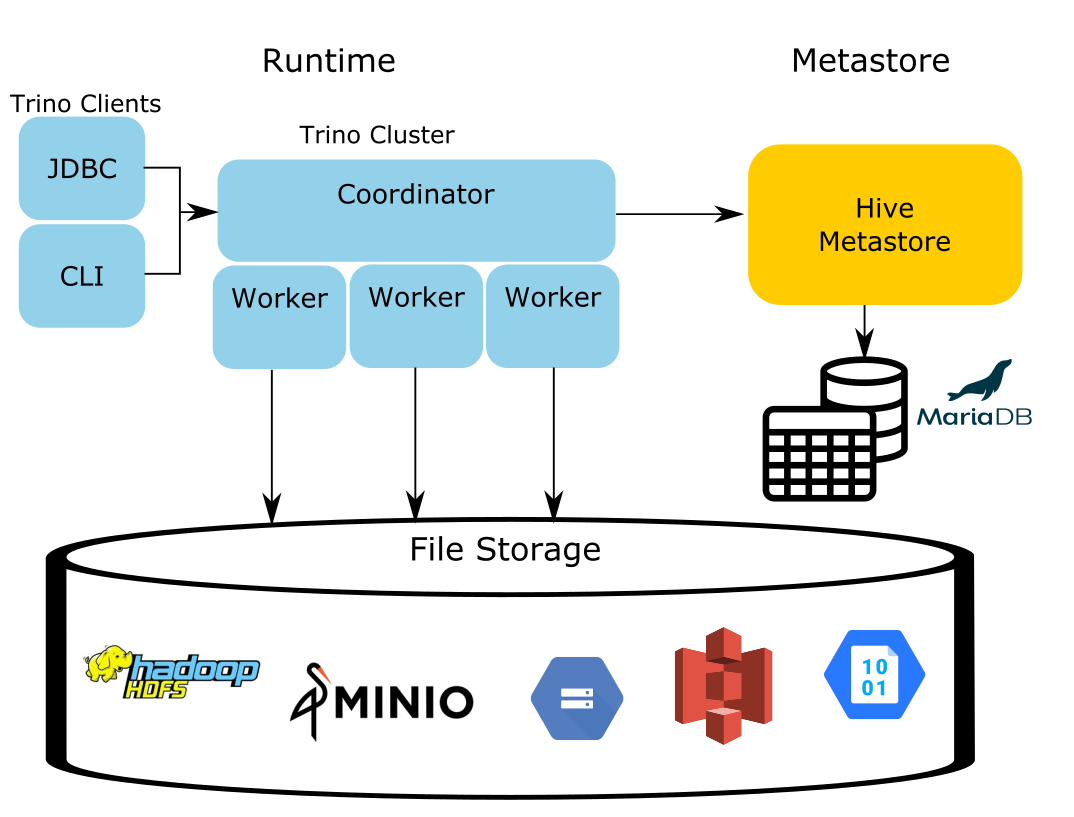
Iceberg can use any compatible metastore, but for Trino, it only supports the Hive metastore and AWS Glue similar to the Hive connector. This is because there is already a vast amount of testing and support for using the Hive metastore in Trino. Likewise, many Trino use cases that currently use data lakes already use the Hive connector and therefore the Hive metastore. This makes it convenient to have as the leading supported use case as existing users can easily migrate between Hive to Iceberg tables. Since there is no indication of which connector is actually executed in the diagram of the Hive connector architecture, it serves as a diagram that can be used for both Hive and Iceberg. The only difference is the connector used, but if you create a table in Hive, you can view the same table in Iceberg.
To recap the steps taken from the first three blogs; the first blog created an events table, while the first two blogs ran two insert statements. The first insert contained three records, while the second insert contained a single record.
Up until this point, the state of the files in MinIO haven’t really been shown except some of the manifest list pointers from the snapshot in the third blog post. Using the MinIO client tool, you can list files that Iceberg generated through all these operations and then try to understand what purpose they are serving.
% mc tree -f local/
local/
└─ iceberg
└─ logging.db
└─ events
├─ data
│ ├─ event_time_day=2021-04-01
│ │ ├─ 51eb1ea6-266b-490f-8bca-c63391f02d10.orc
│ │ └─ cbcf052d-240d-4881-8a68-2bbc0f7e5233.orc
│ └─ event_time_day=2021-04-02
│ └─ b012ec20-bbdd-47f5-89d3-57b9e32ea9eb.orc
└─ metadata
├─ 00000-c5cfaab4-f82f-4351-b2a5-bd0e241f84bc.metadata.json
├─ 00001-27c8c2d1-fdbb-429d-9263-3654d818250e.metadata.json
├─ 00002-33d69acc-94cb-44bc-b2a1-71120e749d9a.metadata.json
├─ 23cc980c-9570-42ed-85cf-8658fda2727d-m0.avro
├─ 92382234-a4a6-4a1b-bc9b-24839472c2f6-m0.avro
├─ snap-2720489016575682283-1-92382234-a4a6-4a1b-bc9b-24839472c2f6.avro
├─ snap-4564366177504223943-1-23cc980c-9570-42ed-85cf-8658fda2727d.avro
└─ snap-6967685587675910019-1-bcbe9133-c51c-42a9-9c73-f5b745702cb0.avro
There are a lot of files here, but here are a couple of patterns that you can observe with these files.
First, the top two directories are named data and metadata.
/<bucket>/<database>/<table>/data//<bucket>/<database>/<table>/metadata/
As you might expect, data contains the actual ORC files split by partition.
This is akin to what you would see in a Hive table data directory. What is
really of interest here is the metadata directory. There are specifically
three patterns of files you’ll find here.
/<bucket>/<database>/<table>/metadata/<file-id>.avro/<bucket>/<database>/<table>/metadata/snap-<snapshot-id>-<version>-<file-id>.avro
/<bucket>/<database>/<table>/metadata/<version>-<commit-UUID>.metadata.json
Iceberg has a persistent tree structure that manages various snapshots of the data that are created for every mutation of the data. This enables not only a concurrency model that supports serializable isolation, but also cool features like time travel across a linear progression of snapshots.

This tree structure contains two types of Avro files, manifest lists and
manifest files. Manifest list files contain pointers to various manifest files
and the manifest files themselves point to various data files. This post starts
out by covering these manifest files, and later covers the table metadata files
that are suffixed by .metadata.json.
The last blog covered the command in Trino that shows the snapshot information that is stored in the metastore. Here is that command and its output again for your review.
SELECT manifest_list
FROM iceberg.logging."events$snapshots";
Result:
| snapshots |
|---|
| s3a://iceberg/logging.db/events/metadata/snap-6967685587675910019-1-bcbe9133-c51c-42a9-9c73-f5b745702cb0.avro |
| s3a://iceberg/logging.db/events/metadata/snap-2720489016575682283-1-92382234-a4a6-4a1b-bc9b-24839472c2f6.avro |
| s3a://iceberg/logging.db/events/metadata/snap-4564366177504223943-1-23cc980c-9570-42ed-85cf-8658fda2727d.avro |
You’ll notice that the manifest list returns the Avro files prefixed with
snap- are returned. These files are directly correlated with the snapshot
record stored in the metastore. According to the diagram above, snapshots are
records in the metastore that contain the url of the manifest list in the Avro
file. Avro files are binary files and not something you can just open up in a
text editor to read. Using the
avro-tools.jar tool
distributed by the
Apache Avro project,
you can actually inspect the contents of this file to get a better understanding
of how it is used by Iceberg.
The first snapshot is generated on the creation of the events table. Upon
inspecting this file, you notice that the file is empty. The output is an
empty line that the jq JSON command line utility removes on pretty printing
the JSON that is returned, which is just a newline. This snapshot represents an
empty state of the table upon creation. To investigate the snapshots you need to
download the files to your local filesystem. Let’s move them to the home
directory:
% java -jar ~/Desktop/avro_files/avro-tools-1.10.0.jar tojson ~/snap-6967685587675910019-1-bcbe9133-c51c-42a9-9c73-f5b745702cb0.avro | jq .
Result (is empty):
The second snapshot is a little more interesting and actually shows us the contents of a manifest list.
% java -jar ~/Desktop/avro_files/avro-tools-1.10.0.jar tojson ~/snap-2720489016575682283-1-92382234-a4a6-4a1b-bc9b-24839472c2f6.avro | jq .
Result:
{
"manifest_path":"s3a://iceberg/logging.db/events/metadata/92382234-a4a6-4a1b-bc9b-24839472c2f6-m0.avro",
"manifest_length":6114,
"partition_spec_id":0,
"added_snapshot_id":{
"long":2720489016575682000
},
"added_data_files_count":{
"int":2
},
"existing_data_files_count":{
"int":0
},
"deleted_data_files_count":{
"int":0
},
"partitions":{
"array":[
{
"contains_null":false,
"lower_bound":{
"bytes":"\u001eI\u0000\u0000"
},
"upper_bound":{
"bytes":"\u001fI\u0000\u0000"
}
}
]
},
"added_rows_count":{
"long":3
},
"existing_rows_count":{
"long":0
},
"deleted_rows_count":{
"long":0
}
}
To understand each of the values in each of these rows, you can refer to the Iceberg specification in the manifest list file section. Instead of covering these exhaustively, let’s focus on a few key fields. Below are the fields, and their definition according to the specification.
manifest_path- Location of the manifest file.partition_spec_id- ID of a partition spec used to write the manifest; must be listed in table metadata partition-specs.added_snapshot_id- ID of the snapshot where the manifest file was added.partitions- A list of field summaries for each partition field in the spec. Each field in the list corresponds to a field in the manifest file’s partition spec.added_rows_count- Number of rows in all files in the manifest that have status ADDED, when null this is assumed to be non-zero.
As mentioned above, manifest lists hold references to various manifest files. These manifest paths are the pointers in the persistent tree that tells any client using Iceberg where to find all of the manifest files associated with a particular snapshot. To traverse this tree, you can look over the different manifest paths to find all the manifest files associated with the particular snapshot you want to traverse. Partition spec ids are helpful to know the current partition specification which are stored in the table metadata in the metastore. This references where to find the spec in the metastore. Added snapshot ids tells you which snapshot is associated with the manifest list. Partitions hold some high level partition bound information to make for faster querying. If a query is looking for a particular value, it only traverses the manifest files where the query values fall within the range of the file values. Finally, you get a few metrics like the number of changed rows and data files, one of which is the count of added rows. The first operation consisted of three rows inserts and the second operation was the insertion of one row. Using the row counts you can easily determine which manifest file belongs to which operation.
The following command shows the final snapshot after both operations executed and filters out only the fields pointed out above.
% java -jar ~/Desktop/avro_files/avro-tools-1.10.0.jar tojson ~/snap-4564366177504223943-1-23cc980c-9570-42ed-85cf-8658fda2727d.avro | jq '. | {manifest_path: .manifest_path, partition_spec_id: .partition_spec_id, added_snapshot_id: .added_snapshot_id, partitions: .partitions, added_rows_count: .added_rows_count }'
Result:
{
"manifest_path":"s3a://iceberg/logging.db/events/metadata/23cc980c-9570-42ed-85cf-8658fda2727d-m0.avro",
"partition_spec_id":0,
"added_snapshot_id":{
"long":4564366177504223700
},
"partitions":{
"array":[
{
"contains_null":false,
"lower_bound":{
"bytes":"\u001eI\u0000\u0000"
},
"upper_bound":{
"bytes":"\u001eI\u0000\u0000"
}
}
]
},
"added_rows_count":{
"long":1
}
}
{
"manifest_path":"s3a://iceberg/logging.db/events/metadata/92382234-a4a6-4a1b-bc9b-24839472c2f6-m0.avro",
"partition_spec_id":0,
"added_snapshot_id":{
"long":2720489016575682000
},
"partitions":{
"array":[
{
"contains_null":false,
"lower_bound":{
"bytes":"\u001eI\u0000\u0000"
},
"upper_bound":{
"bytes":"\u001fI\u0000\u0000"
}
}
]
},
"added_rows_count":{
"long":3
}
}
In the listing of the manifest file related to the last snapshot, you notice the first operation where three rows were inserted is contained in the manifest file in the second JSON object. You can determine this from the snapshot id, as well as, the number of rows that were added in the operation. The first JSON object contains the last operation that inserted a single row. So the most recent operations are listed in reverse commit order.
The next command does the same listing of the file that you ran with the manifest list, except you run this on the manifest files themselves to expose their contents and discuss them. To begin with, you run the command to show the contents of the manifest file associated with the insertion of three rows.
% java -jar ~/avro-tools-1.10.0.jar tojson ~/Desktop/avro_files/92382234-a4a6-4a1b-bc9b-24839472c2f6-m0.avro | jq .
Result:
{
"status":1,
"snapshot_id":{
"long":2720489016575682000
},
"data_file":{
"file_path":"s3a://iceberg/logging.db/events/data/event_time_day=2021-04-01/51eb1ea6-266b-490f-8bca-c63391f02d10.orc",
"file_format":"ORC",
"partition":{
"event_time_day":{
"int":18718
}
},
"record_count":1,
"file_size_in_bytes":870,
"block_size_in_bytes":67108864,
"column_sizes":null,
"value_counts":{
"array":[
{
"key":1,
"value":1
},
{
"key":2,
"value":1
},
{
"key":3,
"value":1
},
{
"key":4,
"value":1
}
]
},
"null_value_counts":{
"array":[
{
"key":1,
"value":0
},
{
"key":2,
"value":0
},
{
"key":3,
"value":0
},
{
"key":4,
"value":0
}
]
},
"nan_value_counts":null,
"lower_bounds":{
"array":[
{
"key":1,
"value":"ERROR"
},
{
"key":3,
"value":"Oh noes"
}
]
},
"upper_bounds":{
"array":[
{
"key":1,
"value":"ERROR"
},
{
"key":3,
"value":"Oh noes"
}
]
},
"key_metadata":null,
"split_offsets":null
}
}
{
"status":1,
"snapshot_id":{
"long":2720489016575682000
},
"data_file":{
"file_path":"s3a://iceberg/logging.db/events/data/event_time_day=2021-04-02/b012ec20-bbdd-47f5-89d3-57b9e32ea9eb.orc",
"file_format":"ORC",
"partition":{
"event_time_day":{
"int":18719
}
},
"record_count":2,
"file_size_in_bytes":1084,
"block_size_in_bytes":67108864,
"column_sizes":null,
"value_counts":{
"array":[
{
"key":1,
"value":2
},
{
"key":2,
"value":2
},
{
"key":3,
"value":2
},
{
"key":4,
"value":2
}
]
},
"null_value_counts":{
"array":[
{
"key":1,
"value":0
},
{
"key":2,
"value":0
},
{
"key":3,
"value":0
},
{
"key":4,
"value":0
}
]
},
"nan_value_counts":null,
"lower_bounds":{
"array":[
{
"key":1,
"value":"ERROR"
},
{
"key":3,
"value":"Double oh noes"
}
]
},
"upper_bounds":{
"array":[
{
"key":1,
"value":"WARN"
},
{
"key":3,
"value":"Maybeh oh noes?"
}
]
},
"key_metadata":null,
"split_offsets":null
}
}
Now this is a very big output, but in summary, there’s really not too much to these files. As before, there is a Manifest section in the Iceberg spec that details what each of these fields means. Here are the important fields:
snapshot_id- Snapshot id where the file was added, or deleted if status is two. Inherited when null.data_file- Field containing metadata about the data files pertaining to the manifest file, such as file path, partition tuple, metrics, etc…data_file.file_path- Full URI for the file with FS scheme.data_file.partition- Partition data tuple, schema based on the partition spec.data_file.record_count- Number of records in the data file.data_file.*_count- Multiple fields that contain a map from column id to number of values, null, nan counts in the file. These can be used to quickly filter out unnecessary get operations.data_file.*_bounds- Multiple fields that contain a map from column id to lower or upper bound in the column serialized as binary. Each value must be less than or equal to all non-null, non-NaN values in the column for the file.
Each data file struct contains a partition and data file that it maps to. These files only be scanned and returned if the criteria for the query is met when checking all of the count, bounds, and other statistics that are recorded in the file. Ideally only files that contain data relevant to the query should be scanned at all. Having information like the record count may also help in the query planning process to determine splits and other information. This particular optimization hasn’t been completed yet as planning typically happens before traversal of the files. It is still in ongoing discussion and is discussed a bit by Iceberg creator Ryan Blue in a recent meetup. If this is something you are interested in, keep posted on the Slack channel and releases as the Trino Iceberg connector progresses in this area.
As mentioned above, the last set of files that you find in the metadata
directory which are suffixed with .metadata.json. These files at baseline are
a bit strange as they aren’t stored in the Avro format, but instead the JSON
format. This is because they are not part of the persistent tree structure.
These files are essentially a copy of the table metadata that is stored in the
metastore. You can find the fields for the table metadata listed
in the Iceberg specification.
These tables are typically stored persistently in a metasture much like the Hive
metastore but could easily be replaced by any datastore that can support
an atomic swap (check-and-put) operation
required for Iceberg to support the optimistic concurrency operation.
The naming of the table metadata includes a table version and UUID:
<table-version>-<UUID>.metadata.json. To commit a new metadata version, which
just adds 1 to the current version number, the writer performs these steps:
- It creates a new table metadata file using the current metadata.
- It writes the new table metadata to a file following the naming with the next version number.
-
It requests the metastore swap the table’s metadata pointer from the old location to the new location.
- If the swap succeeds, the commit succeeded. The new file is now the current metadata.
- If the swap fails, another writer has already created their own. The current writer goes back to step 1.
If you want to see where this is stored in the Hive metastore, you can reference
the TABLE_PARAMS table. At the time of writing, this is the only method of
using the metastore that is supported by the Trino Iceberg connector.
SELECT PARAM_KEY, PARAM_VALUEFROM metastore.TABLE_PARAMS;
Result:
| PARAM_KEY | PARAM_VALUE |
|---|---|
| EXTERNAL | TRUE |
| metadata_location | s3a://iceberg/logging.db/events/metadata/00002-33d69acc-94cb-44bc-b2a1-71120e749d9a.metadata.json |
| numFiles | 2 |
| previous_metadata_location | s3a://iceberg/logging.db/events/metadata/00001-27c8c2d1-fdbb-429d-9263-3654d818250e.metadata.json |
| table_type | iceberg |
| totalSize | 5323 |
| transient_lastDdlTime | 1622865672 |
So as you can see, the metastore is saying the current metadata location is the
00002-33d69acc-94cb-44bc-b2a1-71120e749d9a.metadata.json file. Now you can
dive in to see the table metadata that is being used by the Iceberg connector.
% cat ~/Desktop/avro_files/00002-33d69acc-94cb-44bc-b2a1-71120e749d9a.metadata.json
Result:
{
"format-version":1,
"table-uuid":"32e3c271-84a9-4be5-9342-2148c878227a",
"location":"s3a://iceberg/logging.db/events",
"last-updated-ms":1622865686323,
"last-column-id":5,
"schema":{
"type":"struct",
"fields":[
{
"id":1,
"name":"level",
"required":false,
"type":"string"
},
{
"id":2,
"name":"event_time",
"required":false,
"type":"timestamp"
},
{
"id":3,
"name":"message",
"required":false,
"type":"string"
},
{
"id":4,
"name":"call_stack",
"required":false,
"type":{
"type":"list",
"element-id":5,
"element":"string",
"element-required":false
}
}
]
},
"partition-spec":[
{
"name":"event_time_day",
"transform":"day",
"source-id":2,
"field-id":1000
}
],
"default-spec-id":0,
"partition-specs":[
{
"spec-id":0,
"fields":[
{
"name":"event_time_day",
"transform":"day",
"source-id":2,
"field-id":1000
}
]
}
],
"default-sort-order-id":0,
"sort-orders":[
{
"order-id":0,
"fields":[
]
}
],
"properties":{
"write.format.default":"ORC"
},
"current-snapshot-id":4564366177504223943,
"snapshots":[
{
"snapshot-id":6967685587675910019,
"timestamp-ms":1622865672882,
"summary":{
"operation":"append",
"changed-partition-count":"0",
"total-records":"0",
"total-data-files":"0",
"total-delete-files":"0",
"total-position-deletes":"0",
"total-equality-deletes":"0"
},
"manifest-list":"s3a://iceberg/logging.db/events/metadata/snap-6967685587675910019-1-bcbe9133-c51c-42a9-9c73-f5b745702cb0.avro"
},
{
"snapshot-id":2720489016575682283,
"parent-snapshot-id":6967685587675910019,
"timestamp-ms":1622865680419,
"summary":{
"operation":"append",
"added-data-files":"2",
"added-records":"3",
"added-files-size":"1954",
"changed-partition-count":"2",
"total-records":"3",
"total-data-files":"2",
"total-delete-files":"0",
"total-position-deletes":"0",
"total-equality-deletes":"0"
},
"manifest-list":"s3a://iceberg/logging.db/events/metadata/snap-2720489016575682283-1-92382234-a4a6-4a1b-bc9b-24839472c2f6.avro"
},
{
"snapshot-id":4564366177504223943,
"parent-snapshot-id":2720489016575682283,
"timestamp-ms":1622865686278,
"summary":{
"operation":"append",
"added-data-files":"1",
"added-records":"1",
"added-files-size":"746",
"changed-partition-count":"1",
"total-records":"4",
"total-data-files":"3",
"total-delete-files":"0",
"total-position-deletes":"0",
"total-equality-deletes":"0"
},
"manifest-list":"s3a://iceberg/logging.db/events/metadata/snap-4564366177504223943-1-23cc980c-9570-42ed-85cf-8658fda2727d.avro"
}
],
"snapshot-log":[
{
"timestamp-ms":1622865672882,
"snapshot-id":6967685587675910019
},
{
"timestamp-ms":1622865680419,
"snapshot-id":2720489016575682283
},
{
"timestamp-ms":1622865686278,
"snapshot-id":4564366177504223943
}
],
"metadata-log":[
{
"timestamp-ms":1622865672894,
"metadata-file":"s3a://iceberg/logging.db/events/metadata/00000-c5cfaab4-f82f-4351-b2a5-bd0e241f84bc.metadata.json"
},
{
"timestamp-ms":1622865680524,
"metadata-file":"s3a://iceberg/logging.db/events/metadata/00001-27c8c2d1-fdbb-429d-9263-3654d818250e.metadata.json"
}
]
}
As you can see, these JSON files can quickly grow as you perform different updates on your table. This file contains a pointer to all of the snapshots and manifest list files, much like the output you found from looking at the snapshots in the table. A really important piece to note is the schema is stored here. This is what Trino uses for validation on inserts and reads. As you may expect, there is the root location of the table itself, as well as a unique table identifier. The final part I’d like to note about this file is the partition-spec and partition-specs fields. The partition-spec field holds the current partition spec, while the partition-specs is an array that can hold a list of all partition specs that have existed for this table. As pointed out earlier, you can have many different manifest files that use different partition specs. That wraps up all of the metadata file types you can expect to see in Iceberg!
This post wraps up the Trino on ice series. Hopefully these blog posts serve as a helpful initial dialogue about what is expected to grow as a vital portion of an open data lakehouse stack. What are you waiting for? Come join the fun and help us implement some of the missing features or instead go ahead and try Trino on Ice(berg) yourself!