
Trino Summit 2022 was in a word, invigorating. I’m still coming off the high from the amount of energy I gained from being at this summit, meeting many of you face-to-face for the first time. Most surprisingly, I learned that Trino contributor James Petty from AWS was actually not famous painter Bob Ross.

If you’ve ever planned a conference, you know that there are a lot of details to iron out, and you can be left exhausted by the end. After this year’s Trino Summit though, rather than being worn out, I felt like it ended too quickly and I simply wanted more time to chat with everyone. A single day was simply not enough, and now all I can think about is the next summit. We not only got to hear an incredible lineup of talks and discussions from first-time Trino Summit speakers like Apple, Shopify, and Lyft, but also had many engaging discussions outside the auditorium.




There were cross-community discussions between Delta Lake, Airflow, and Alluxio about how to turbo-charge Trino integrations with these communities. There were many companies talking about best practices and gotchas while migrating from Hive to Iceberg or Delta Lake. Others wanted to learn how to use fault-tolerant execution. I spoke with managers of companies like LinkedIn and Bloomberg who wanted to help develop their engineers to get more involved with contributing to Trino. We all finally got to see the faces of people we had been talking to for the past two to three years for the first time. People were getting their free copies of Trino: The Definitive Guide signed by Manfred, Matt, and Martin and brought home other swag. After a long day of talks, we wrapped Trino Summit up with two happy hours on the roof of the Commonwealth club watching the sunset over the San Francisco bay bridge.


Session summaries #
I would like to quickly summarize a few short takeaways I had from each talk at the summit. I highly recommend you watch the full videos on the Trino YouTube which are linked in the titles:
Keynote: State of Trino (Read more)
- Trino co-creator, Martin, covers recently developed features, community statistics, and discusses roadmap features like Project Hummingbird.
-
Dain and David join Martin on the stage to answer audience questions.

- Apple has an in-house k8s operator to manage Trino cluster lifecycles, and an orchestrator to provision and simplify cluster creation and management.
-
Apple has a heavy focus on Apache Iceberg as their table format and has contributed a significant amount of PRs to improve interoperability between Trino and Spark and increased coverage of Iceberg APIs.

Enterprise-ready Trino at Bloomberg: One Giant Leap Toward Data Mesh! (Read more)
- Bloomberg uses Trino to centralize access to their massive amounts of catalogs under many different departments.
-
To offer Trino-as-a-Service for varying workloads, they use a Trino Load Balancer (a fork of the popular presto-gateway project at Lyft) to add new functionality. In talking with them after their presentation, the Bloomberg team expressed an interest in wanting to open source this work to the community as a more generalized solution than the gateway project.

Optimizing Trino using spot instances (Read more)
- In an attempt to minimize costs, Zillow is measuring the efficacy of running Trino ETL jobs on spot instances.
-
This currently runs the risk of retries for failure but future work will look at utilizing the new fault-tolerant execution method to mitigate retries in the event of failure.

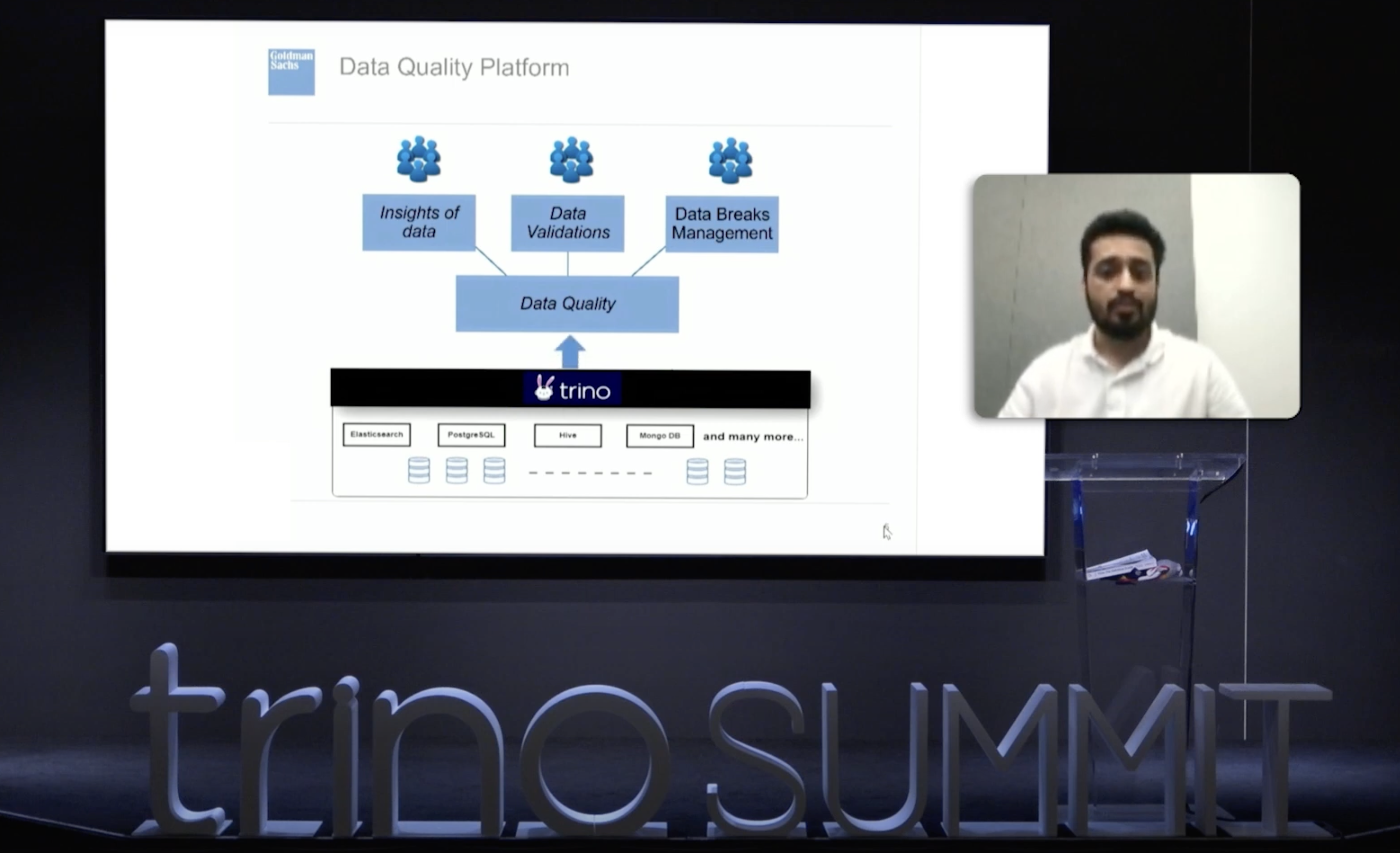
Leveraging Trino to Power Data at Goldman Sachs (Read more)
- Goldman Sachs uses Trino to power their data quality service, taking advantage of the fact that Trino centralizes all visibility across their platform.
Elevating data fabric to data mesh: Solving data needs in hybrid datalakes (Read more)
-
Comcast takes us through their Trino architecture journey by providing the history of their Data Fabric service, and now discusses the data governance and culture changes required to realize a Data Mesh with Trino.

Rewriting History: Migrating petabytes of data to Apache Iceberg using Trino (Read more)
- Shopify has recently migrates of its workloads to Trino. One of the first hurdles was dealing with many issues in the Hive table format, so they quickly upgraded to the Iceberg table format.
- They initially encountered numerous issued, but experienced incredibly fast turnaround of fixes from the Trino project that resolved their issues during the migration.
-
There’s also a benchmark of how updating to a columnar format and Iceberg table format drastically improves the results.

Trino for Large Scale ETL at Lyft (Read more)
- Lyft is using Trino to perform ETL jobs scanning 10PB of data per day, and writing 100TB per day. They are not using fault-tolerant execution.
- In the last year, Lyft cut their number of Trino nodes in half, while increasing the volume of their workloads due to recent improvements in Trino and upgrades in Java versions.
-
Keeping up with the rapid release cycle of Trino was a challenge and Lyft showcases their regression testing using their query replay framework.

Federating them all on Starburst Galaxy (Read more)
- Running and scaling Trino is difficult. Starburst showcases Starburst Galaxy, a SaaS data platform built around the Trino query engine.
-
This demoes running federated queries over Pokémon data scattered across MongoDB and Iceberg tables.

Trino at Quora: Speed, Cost, Reliability Challenges and Tips (Read more)
- Quora uses a large number of Trino clusters for ad-hoc, ETL, time series, A/B testing, and backfill data.
- Quora faced some initially high costs on Trino due to inefficient uses of resources.
-
To address this they migrated to use Graviton instances, implemented autoscaling, and optimized query efficiency.

Journey to Iceberg with SK Telecom (Read more)
- The speakers travelled all the way from South Korea to join us in person.
- SK Telecom had a multitude of performance issues that all stemmed from the lack of flexibility in the Hive model and metastore.
- They migrated to Iceberg to address performance issues and had added benefits of Iceberg’s table format to improve developer workflow.
- Housekeeping operations like optimize were already addressed by the Iceberg community and quickly added to Trino.
-
This reduced query processing time by 80%.

Using Trino with Apache Airflow for (almost) all your data problems (Read more)
- Airflow is a highly functional and well-adopted workflow management platform to schedule jobs on your data platform.
-
The Trino integration for Airflow recently landed and this coincided with the GA arrival of fault-tolerance execution mode in Trino.

How we use Trino to analyze our Product-led Growth (PLG) user activation funnel (Read more)
- Upsolver solves a lot of common data problems on their platform.
- One such problem is measuring activation rates in a product-led growthteam. This requires taking action on many sources of data.
-
Trino makes a natural fit to address the issues of joining this data together.

Federate ‘em all #
After a whole day of throwing Trino balls out to the crowd, we got to see a nice metaphor for federated data by throwing them all in the air and yelling, “Federate ‘em all!”

Trino Contributor Congregation #
The day after the summit, we invited a relatively small group of our contributors to meet for the inaugural Trino Contributor Congregation (TCC). This gathered many of our long-time and heavy Trino contributors. We had folks from companies like Starburst, AWS, Apple, Bloomberg, Lyft, Comcast, LinkedIn, Treasure Data, and others. Let’s dive into some of the topics we discussed.

We discussed feature proposals like:
- The Trino loadbalancer which is an adaption of the popular gateway project from Lyft.
- A Ranger plugin to be maintained by the Trino community rather than rely on the Ranger project.
- A Snowflake connector that was traditionally held back by the lack of infrastructure.
We discussed the need for better shared testing datasets outside of the TPC-H and TPC-DS that are more representative of real workloads that many are using.
We discussed the need for a clearer process for contributors to follow to minimize the time to get features merged and avoid stale PRs. This is being addressed by the backlog grooming performed by the developer relations team, and assigning maintainers to own various PRs. While there is never a promise to merge a PR, improving the turnaround and communication on PRs is crucial to keep happy contributors and improve the health of the project.
While we were sad that not everyone could make the in-person TCC, we plan to have virtual TCCs on a more frequent cadence and have the in-person TCCs alongside larger in-person events. Getting these TCCs right is core to growing the maintainership and continued success of the Trino project.
We hope all of you who could join us in-person and online enjoyed yourselves. We all had such a blast! Stay tuned for updates on the next Trino Summit location!
