
In the data lake world, data partitioning is a technique that is critical to the performance of read operations. In order to avoid scanning large amounts of data accidentally, and also to limit the number of partitions that are being processed by a query, a query engine must push down constant expressions when filtering partitions.
Partitions in an Iceberg table tend to be fairly large, containing up to tens or even hundreds of data files. It is therefore crucial to be able to skip irrelevant partitions while scanning a table in order to ensure high performance query processing speed. When a table is created in a data lake, its partitioning scheme constitutes a de-facto index, speeding up queries against it by pruning out irrelevant partitions from the scan operation.
Date and time are natural and universal partitioning candidates. Common
partition patterns revolve around month, day, hour. One exciting feature of the
Iceberg table format is its hidden
partitioning.
Iceberg uses handy
transforms
such as year, month, day, hour to deal with the complexities of mapping
a raw timestamp value to an actual partition value in a manner that is
transparent to the user.
Let’s look at a typical example of an Iceberg table containing log events which are partitioned by day:
CREATE TABLE logs (
event_time timestamp(6) with time zone,
level varchar,
message varchar)
WITH (partitioning=ARRAY['day(event_time)'])
When dealing with logs, it often happens that we want to know what happened today or within the last few days:
SELECT *
FROM logs
WHERE
event_time >= CURRENT_DATE
SELECT *
FROM logs
WHERE
event_time >= CURRENT_DATE - INTERVAL '7' DAY
Constant folding #
Trino uses the constant folding optimization technique for dealing with these types of queries by internally rewriting the filter expression as a comparison predicate against a constant evaluated before executing the query in order to avoid recalculating the same expression for each row scanned:

Predicate pushdown #
Another common query scenario for log data is to query for a specific date in the past. A seasoned SQL user, being aware of the underlying data type of the partitioning column, would likely specify the date to be queried explicitly as two timestamp constant filter expressions:
SELECT *
FROM logs
WHERE
event_time >= TIMESTAMP '2022-01-20 00:00:00.000000 UTC'
AND event_time < TIMESTAMP '2022-01-21 00:00:00.000000 UTC'
A different flavor of the above-mentioned query would be to use the BETWEEN range operator:
SELECT *
FROM logs
WHERE
event_time BETWEEN TIMESTAMP '2022-01-20 00:00:00.000000 UTC'
AND TIMESTAMP '2022-01-20 23:59:59.999999 UTC'
Users can focus on writing queries that are concise and readable by other human readers, and leave the eventual grunt optimization work to the query engine.
A succinct way of querying the logs for a specific day would be to cast the
timestamp field value to its corresponding date value and compare it with
the day containing the relevant logs:
SELECT *
FROM logs
WHERE
CAST(event_time AS date) = DATE '2022-01-20'
In this case, Trino unwraps the initial temporal
filter to a filter that tests
whether the column event_time is within the constant timestamp range
corresponding to the date used in the initial filter, which is equivalent to the
most efficient of the explicit filters mentioned above.
A different approach of querying the log data for a specific date is to use the date_trunc function:
SELECT *
FROM logs
WHERE
date_trunc('day', event_time) = DATE '2022-01-20'
Trino again replaces the initial temporal
filter to a filter testing
whether the column event_time is within the constant timestamp range
corresponding to the date used in the initial filter.
A slightly different use case is querying the log data to see whether an exotic error type is recorded in the logs during previous months of the current year by making use of the year() function:
SELECT *
FROM logs
WHERE
year(event_time) = 2023
This time, Trino rewrites the temporal
filter
applied on the column event_time with a BETWEEN filter for the unfolded date
range corresponding to the entire span of the specified year:
event_time BETWEEN TIMESTAMP '2023-01-01 00:00:00.000000 UTC'
AND '2023-12-31 23:59:59.999999'
Without predicate pushdown, the filtering is done by Trino on each tuple, after scanning the entire content of the table:
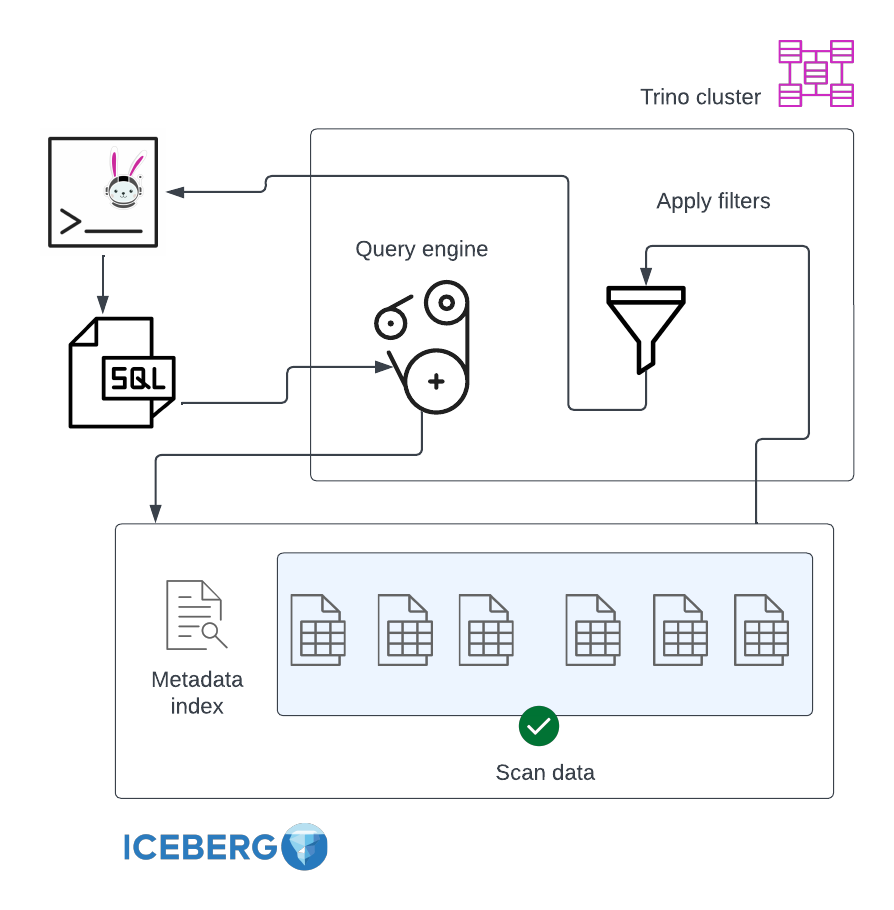
The optimization techniques employed by Trino to speed up the above mentioned types of queries all involve replacing the provided filter with an equivalent filter expression. Constant replacement optimizations compare the table column against a constant or a constant range with the purpose of literally pushing the filter down to Iceberg.
As a consequence, the partition pruning happens on the metadata layer of the table instead of filtering on top of the data itself, dramatically reducing the amount of actual data files scanned:
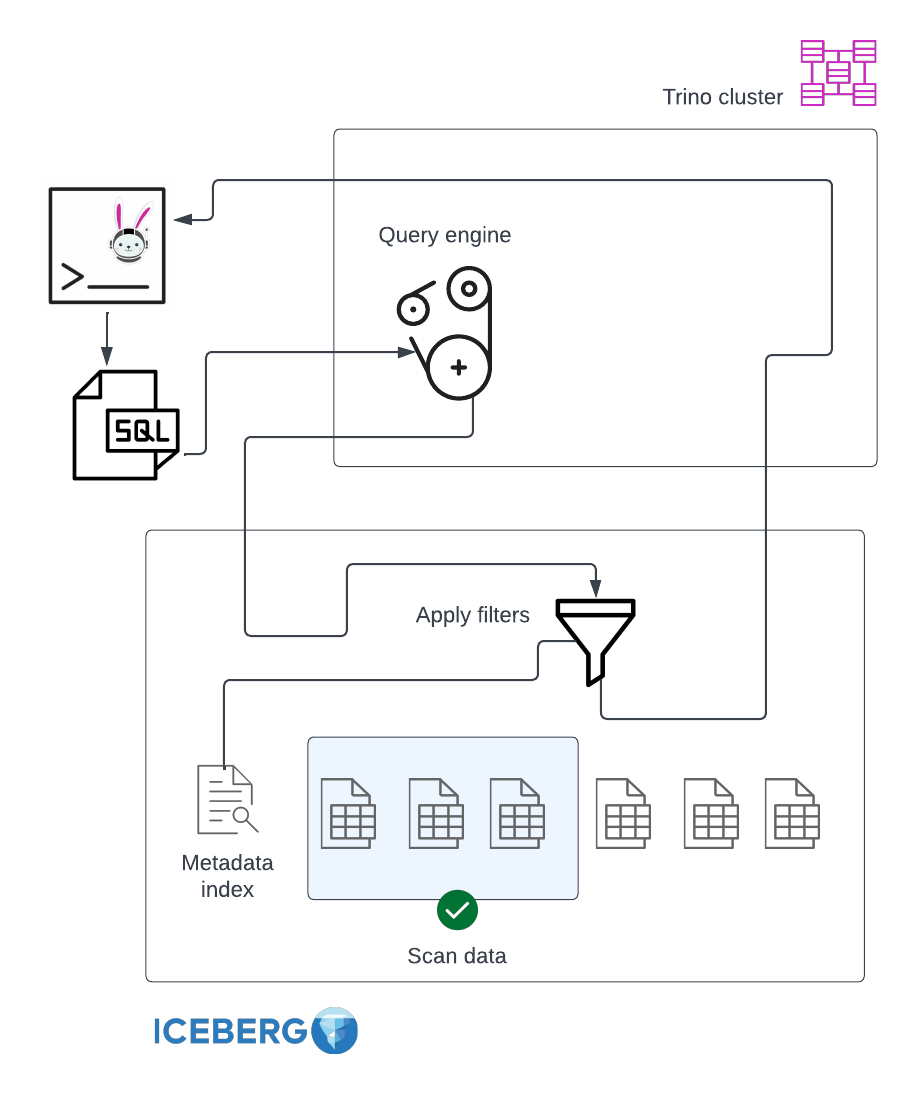
As described in the Iceberg Table Spec, for
any snapshot of the table, Iceberg tracks each individual data file and the
partition to which it belongs. Iceberg uses a hierarchical index in its metadata
layer by storing lower_bounds and upper_bounds for:
- each partition in the manifest list files
- each data file in the manifest files
Desugaring seemingly variable filter expressions to comparison predicates involving only columns and constants or constant ranges pays off. Not only does it prune out partitions, but it also skips portions of the data file (for example a Apache Parquet row group) or even the data file altogether in certain circumstances. For instance, pruning and skipping can occur if the queried range value does not overlap with the indexed Iceberg metadata range of values contained in the file, in case of a non-partition column filter.
To put things in perspective, the optimization techniques presented in this article, which have been already integrated in Trino, can cause the execution of queries containing temporal filters with selective filters to complete in seconds compared (depending on the size of the table scanned) to hours.
A reader keen to experiment and discover whether the previously mentioned optimization techniques are actually effective can use EXPLAIN to examine the output of the query planning stage. If the temporal predicate employed in the query is being pushed down, the scan operation should definitely have fewer rows than the count of all rows contained in the table.
The queries in this post showcase just a tiny fraction of the myriad of techniques which can be employed to perform queries on date and time columns. Trino continuously strives to streamline its users’ workflows by providing the results of queries as fast as possible.