Video
- Concept of the week: Change Data Capture (934s)
- Concept of the week: Debezium (1652s)
- Concept of the week: Debezium + Trino at Zomato (2747s)
- PR of the week: PR 4140 Implement aggregation pushdown in Pinot (3865s)
- Question of the week: Is there an array function that flattens a row into three rows? (4265s)
Audio
Guests
- Ayush Chauhan, Data Platform Engineer at Zomato (Ayush Chauhan).
- Gunnar Morling, Lead of Debezium and Open source software engineer at Red Hat (@gunnarmorling).
- Ashhar Hasan, Software Engineer at Starburst (@hashhar).
Release 361
Official announcement items from Martin:
- Support for OAuth2/OIDC opaque access tokens
- Aggregation pushdown for Pinot
- Better performance for Parquet files with column indexes
- Support for reading fields as JSON values in Elasticsearch
Manfred’s additional notes:
- Predicate pushdown in Cassandra
- Metadata cache size limitation in a few connectors
- Lots of improvements for Hive view support
- Glue table statistics improvements
More info at https://trino.io/docs/current/release/release-361.html.
Concept of the week: Change Data Capture
If you know Trino, you know it allows for flexible architectures that include many systems with varying use cases they support. We’ve come to accept this potpourri of systems as a general modus operandi for most businesses.
Many times the data gets copied to different systems to accomplish varying use cases from performance and data warehousing to merge cross cutting data into a single store. When copying data between systems, how do these systems stay in sync? It’s a critical need especially for Trino to know that the state across the data sources we query is valid.
To answer this, we can use the concept of Change Data Capture (CDC). CDC is a powerful concept that considers a data source(s), called a systems of record(s), that store the true state of a system. The systems of records are monitored for changes, and upon detecting changes, the CDC system propogates changes to a number of target systems.
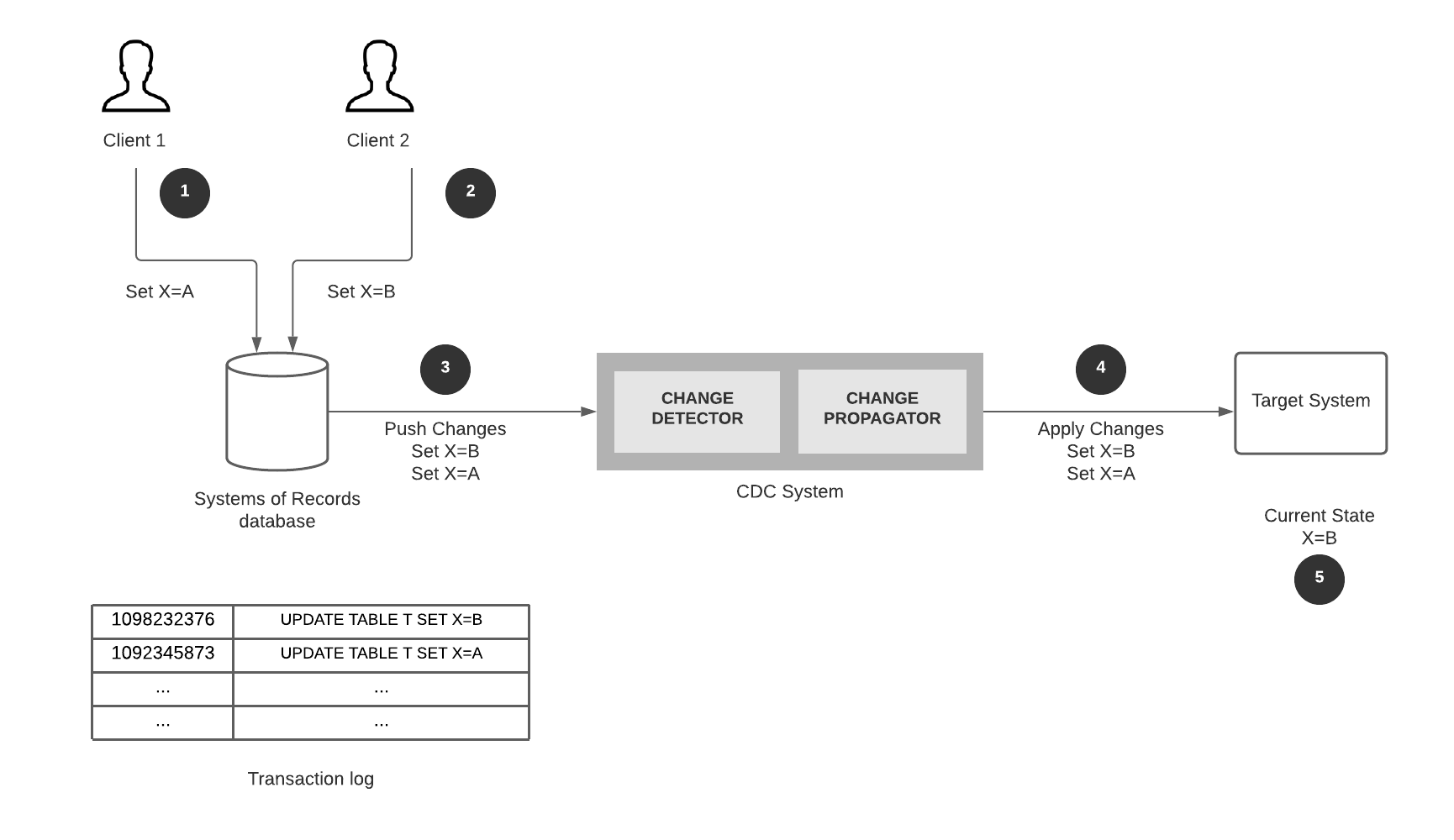
Change Data Capture: Source.
Debezium for CDC
One implemention of CDC that has grown tremendously in popularity since its inception is called Debezium. According to https://debezium.io:
Debezium is an open-source distributed platform for change data capture. Start it up, point it at your databases, and your apps can start responding to all of the inserts, updates, and deletes that other apps commit to your databases. Debezium is durable and fast, so your apps can respond quickly and never miss an event, even when things go wrong.
The common way Debezium is deployed in the wild is using [Kafka Connect(https://docs.confluent.io/platform/current/connect/index.html) and defining the Debezium source connectors. You can then use the Kafka Connect ecosystem to create to different targets downstream.
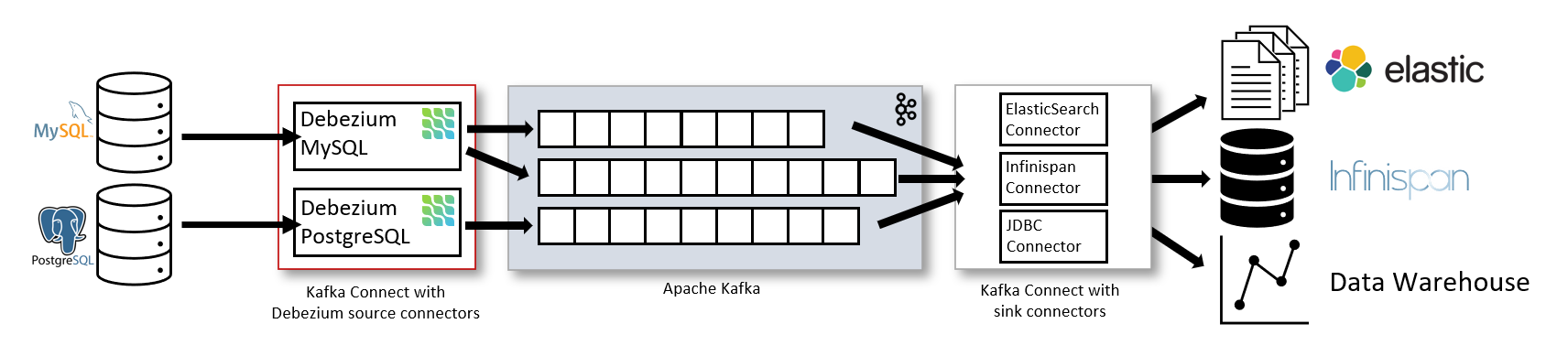
The Debezium architecture with Kafka Connect: Source.
Another alternative, if you don’t want to use Kafka, is to use dedicated Debezium servers to implement CDC and push the logs to the target database downstram using Debezium connectors.
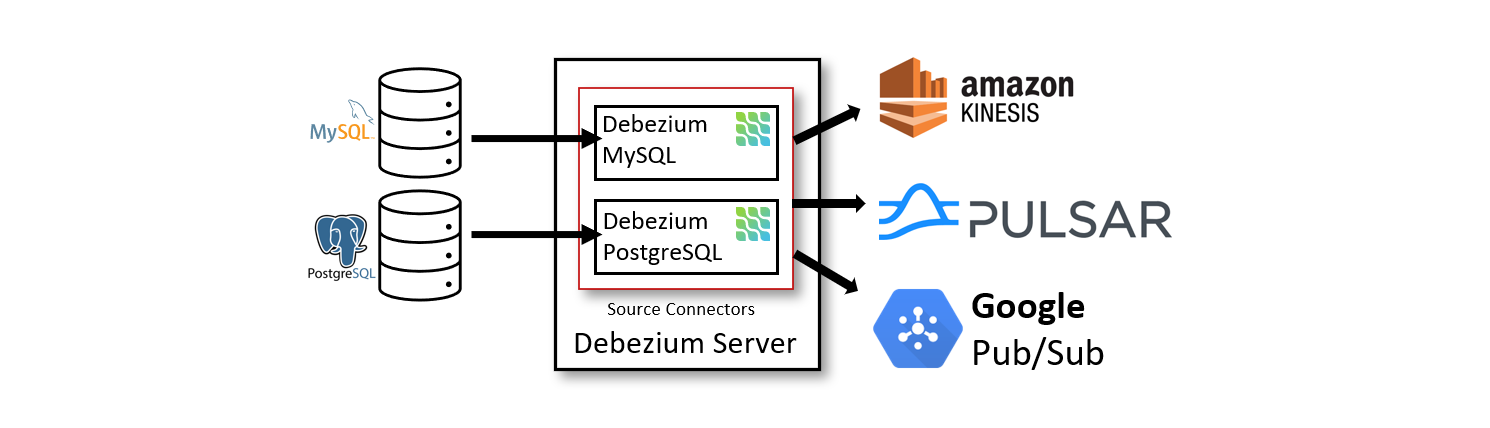
The Debezium standalone server architecture: Source.
While CDC is the primary focus, Debezium also provides support for more advanced concepts such as the outbox pattern support for Quarkus apps.
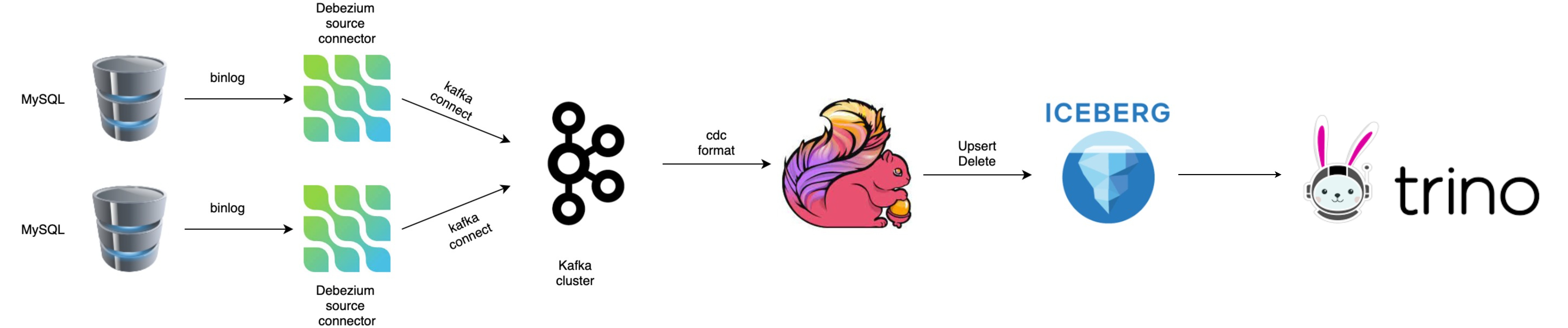
Debezium + Trino at Zomato
Zomato is a technology platform that connects customers, restaurant partners and delivery partners, serving their multiple needs. Customers use their platform to search and discover restaurants, read and write customer generated reviews and view and upload photos, order food delivery, book a table and make payments while dining-out at restaurants. Clearly there’s a lot of data that can flow through a platform like this. You’ll have both operational databases to support the applications in this platform, but also need big data stores to store and analyze all of this data.
Here is one of the earlier iterations of Zomato’s big data architecture before they were able to integrate Debezium. Ayush covers some of the pain points they experienced before implementing CDC.
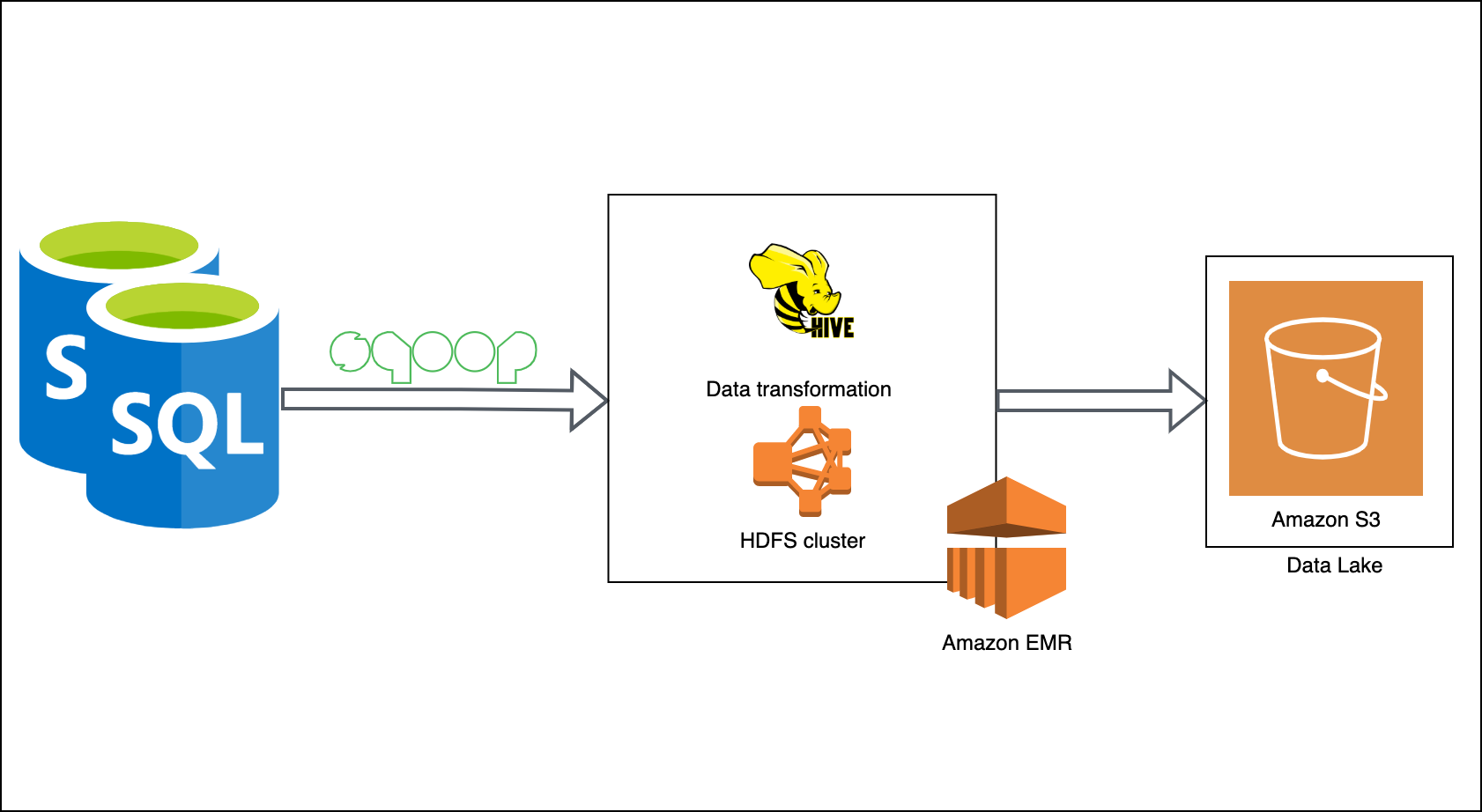
Once Zomato implemented CDC, they were able to keep their downstream Iceberg stores in sync across multiple operational systems. As a result the analytics data is now much more dependable.
PR of the week: PR 4140 Implement aggregation pushdown in Pinot
The PR of the week is actually a throwback to episode thirteen, Trino takes a sip of Pinot, where our guest Elon Azoulay discussed some of the upcoming features coming to the Pinot connector were. Push down aggregates was on that list and this just landed in the 361 release!
This PR implements aggregation pushdown for COUNT, AVG, MIN, MAX, SUM,
COUNT(DISTINCT) and approx_distinct. It is enabled by default and can be
disabled using the configuration property pinot.aggregation-pushdown.enabled
or the catalog session property aggregation_pushdown_enabled.
FYI: https://github.com/trinodb/trino/pull/9208
Thanks Elon!
Question of the week: Is there an array function that flattens a row like 1 | [a, b, c] into three rows?
Our question of the week
comes from Brian Hudson on our Trino community Slack. Brian is dealing with an ARRAY
type in one column and an INTEGER column in another. This is common when
processing nested denormalized data. The goal is to make this row 1 | [a, b, c],
split the array into three rows.
1 | a
1 | b
1 | c
Kasia answered this question by using the UNNEST on the array column. This
UNNEST statement produces a single column of the size of the array and a
JOIN is performed with the original INTEGER column.
WITH t(x, y) AS (VALUES (1, ARRAY['a', 'b', 'c']))
SELECT x, y_unnested
FROM t
LEFT JOIN UNNEST (t.y) t2(y_unnested) ON true;
trino> WITH t(x, y) AS (VALUES (1, ARRAY['a', 'b', 'c']))
-> SELECT x, y_unnested
-> FROM t
-> LEFT JOIN UNNEST (t.y) t2(y_unnested) ON true;
x | y_unnested
---+------------
1 | a
1 | b
1 | c
(3 rows)
Events, news, and various links
Blogs and Resources
- A gentle introduction to Event Driven Change Data Capture
- A Visual Introduction to Debezium
- Debezium Blog
- Debezium Docs
- Debezium Examples
- Debezium Resources
Videos
- Practical Change Data Streaming Use Cases with Apache Kafka & Debezium
- Apache Kafka and Debezium / DevNation Tech Talk
Trino Meetup groups
- Virtual
- East Coast (US)
- West Coast (US)
- Mid West (US)
If you want to learn more about Trino, check out the definitive guide from OReilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.