Video
- Concept of the week: Data cubes and Apache Pinot (840s)
- Interview: Apache Pinot (840s)
- PR of the week: PR 2028 Add Pinot connector (3231s)
- Question of the week: Why does my passthrough query not work in the Pinot connector? (3983s)
- Demo: Pinot batch insertion and query using Trino Pinot connector (4338s)
Audio
Commander Bun Bun loves sippin' on Pinot after a hard day of data exploration!
Pinot links
Guests
- Xiang Fu, project management chair and committer at Apache Pinot and co-founder of stealth mode startup (@xiangfu0)
- Elon Azoulay, software engineer at stealth mode startup (@ElonAzoulay)
Release 353
Release notes discussed: https://trino.io/docs/current/release/release-353.html Martin’s list:
- New ClickHouse connector
- Support for correlated subqueries involving UNNEST
- CREATE/DROP TABLE in BigQuery connector
- Reading and writing column stats in Glue Metastore
- Support for Apache Phoenix 5.1
Manfred’s notes:
- New geometry functions
- A whole bunch of correctness and performance improvements
- Env var (and hence secrets) support for RPM-based installs
- Hive - performance for bucketed table inserts
- Kafka - schema registry improvements
- Experimental join pushdown in a bunch of JDBC connectors
- Also a bunch of fixes on JDBC connectors
- Quite a list of changes on the SPI - ensure to check if you have a plugin
Concept of the week: Data cubes and Apache Pinot
Before diving into Pinot, I think it’s worthwhile to discuss some theoretical background to motivate some of the use cases Pinot solves for. We cover the concept of data cubes and how they are used in traditional data warehousing to speed up queries and minimize unnecessary work on your OLAP system.
Data cubes and MOLAP (Multi-dimensional online analytics processing)
In data analytics, there are many access patterns that tend to repeat themselves over and over again. It is very common to need to split and merge data based on the date and time values. Or perhaps you ask a lot of questions based on a specific customer, or even a specific product. Answering these questions typically involves aggregation of data like sums, averages, counts, etc… Wouldn’t it make sense to cache some of these intermediary results?
A common way to visualize the columns that are commonly bucketed to some values or range of values is to show them as a cube, that is sliced up into smaller dimensions. This actually derives from the traditional form of OLAP, multi-dimensional OLAP (MOLAP).
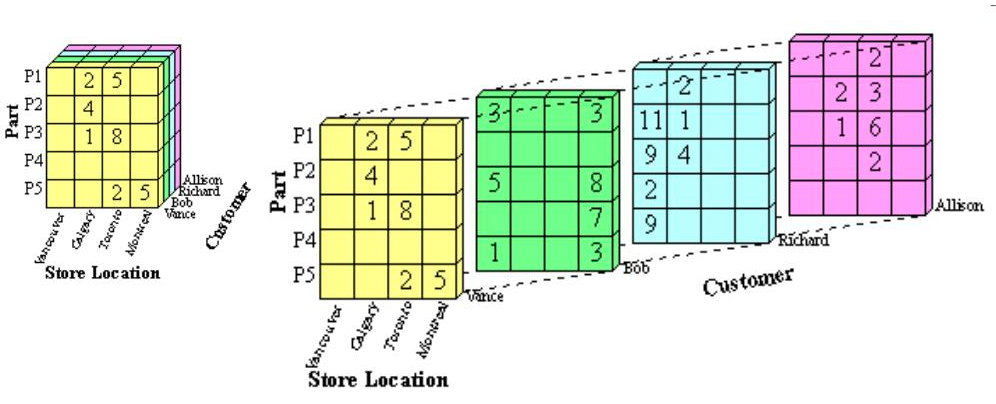
This cube represents a caching of data aggregations that are grouped by commonly used dimensions. For example, the displayed cube would be the pre-aggregation of the following query:
SELECT part, store, customer, COUNT(*)
FROM cube_table
GROUP BY part, store, customer
If we want to get the data for a particular customer, we can take a “slice” of that cube by specifying a particular customer. The following query returns the green square above from our cube.
SELECT part, store, COUNT(*)
FROM cube_table
WHERE customer = "Bob"
GROUP BY part, store
Now what if we want to flatten one of the dimensions? While this can be managed
with a GROUP BY as before, but depending on the system may ignore any cached
data and scan over all the rows. For this, SQL reserved a special set of
keywords around cubes. We won’t dive into that in depth now, but for our current
goal of flattening a dimension, we can use ROLLUP. Using the keyword ROLLUP
indicates to the underlying system that you intend to aggregate over the
pre-materialized data rather than scan over all rows to compute again. This
gives you the total count of parts per store using the counts of the data cube.
SELECT part, store, COUNT(*)
FROM cube_table
GROUP BY ROLLUP (part, store)
Now, although we used simple counts, you can precompute a lot of other aggregate data like sums, min, max, percentile, etc… These can service various queries that are commonly queried and don’t require a new computation every time. That is the goal of MOLAP and data cubes.
Apache Pinot
Now let’s move on to Apache Pinot. It is a realtime distributed OLAP datastore, designed to answer OLAP queries with low latency. Although there may be a lot of words there that overlap with the Trino description, the key differentiators are realtime and low latency. Trino performs batch processing and is not a realtime system where Pinot is great for ingesting data in batch or stream. The other key word, low latency could technically apply to both Pinot and Trino but in the context of realtime subsecond latency, Trino is slow compared to Pinot. This is due to the specialized indexes that Pinot uses to store the data that we cover shortly. Importantly, another big distinction is that Trino does not store any data itself. It is purely a query engine. Xiang has a really great summary slide that easily shows the strengths of each system and why they work so well together.
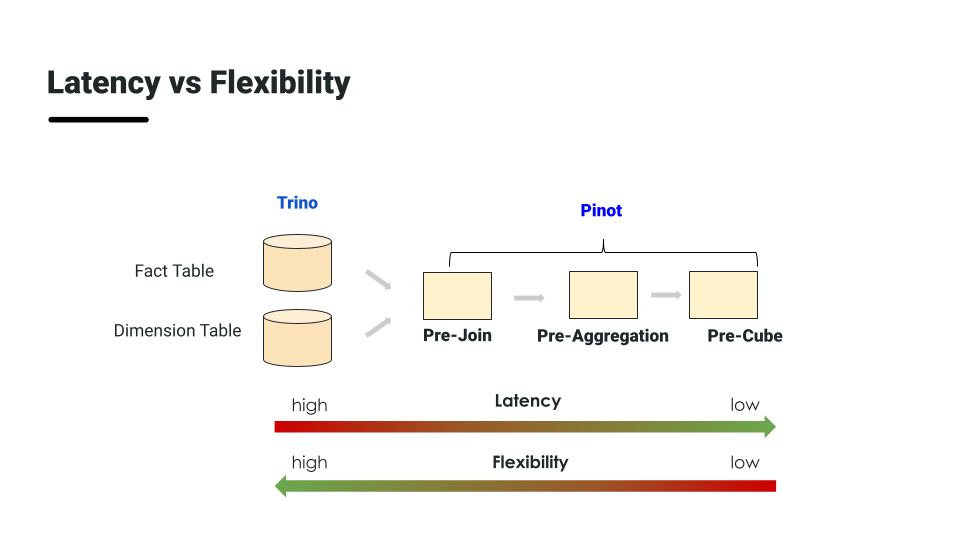
While Trino is not as fast as Pinot, it is able to handle a broader set of use cases like performing broad joins over open data formats in data lakes. This is what motivated work on the Trino Pinot connector. You can have the speed of Pinot, while having the flexibility of Trino.
Now that you understand the common use case for Pinot, it’s important to know the main goals of Pinot.
- One primary goal is the keep response times of aggregation queries
predictable, regardless of how many requests Pinot handles. As it scales
you won’t see a degradation of performance. This is achieved by Pinot’s
custom indices and storage formats.
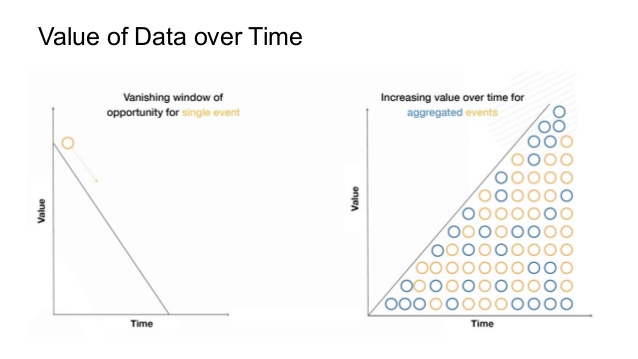
-
Another goal of Pinot is to revive the value of data from a historical context. Data reaches a particular point in its lifecycle where it becomes less valuable as it ages. While all data is able to add some value no matter what the age, there’s a tradeoff of scanning multiple rows to glean information from antiquated data. Pinot aims to remove this tradeoff as most questions around historical data are queried in aggregate and this can be summarized and queried at a low cost.
- The final goal is to manage dimension explosion. One of the difficulties with managing a system that caches all this historic data is handling dimension explosion that occurs when you cache every possible combination of data. Above we showed a three-dimensional cube, but Pinot can handle a much larger number of dimensions. However, just because you can, doesn’t mean you should. Pinot has a lot of smarts around using the data, and some good defaults to determine the maximum number of buckets per dimension. This helps balance an exploding cache yet maintains fast results.
Pinot architecture
We just covered Pinot theory and goals, let’s take a quick look at the architecture.
A Pinot cluster consists of a controller, broker, server, and optionally a minion to purge data.

PR of the week: PR 2028 Add Pinot connector
Our guest on the show today, Elon Azoulay, is the author of this PR, so we can ask him all about it now.
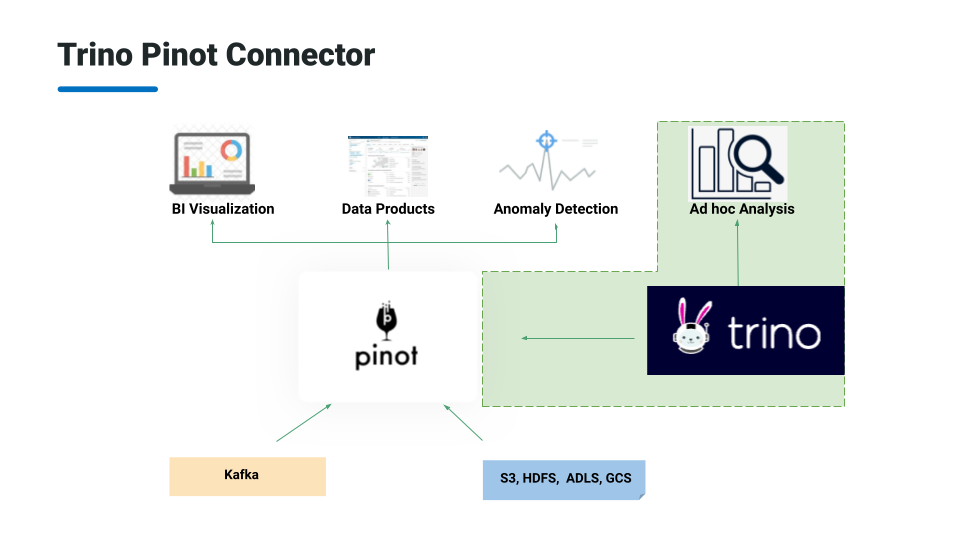
- Basic configuration (Pinot controller url, Pinot segment limit)
- 2 ways to connect to Pinot - broker and server, and their tradeoffs (i.e. segment limit for server)
- Talk about broker passthrough queries, i.e select * from “select … from pinot_table …
- Server limit that we eventually want to eliminate broker query parsing
- How to crash the Pinot server.
- Streaming server alternative
Future Pinot features in Trino
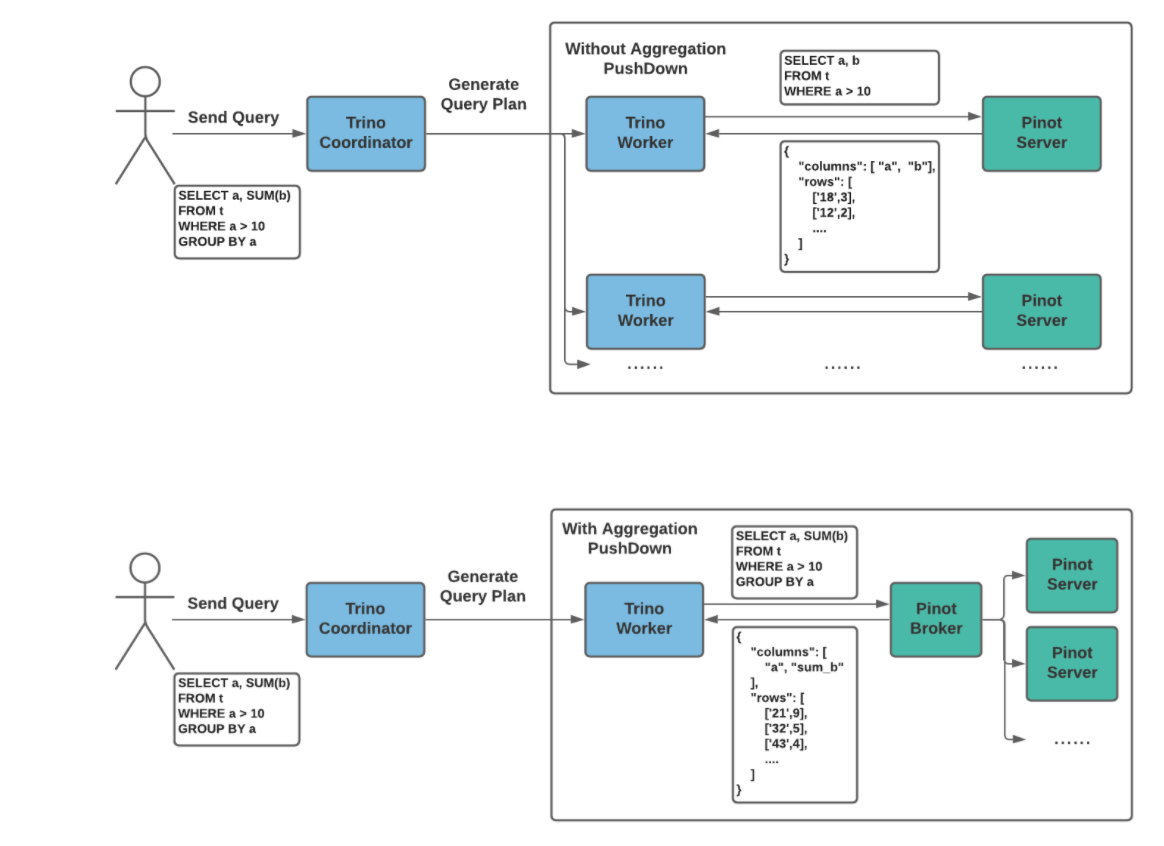
- Pinot insert (PR 7162)
- Pinot create table (PR 7164)
- Pinot drop table (PR 7160)
- Pinot 6 (PR 7163)
- Pinot filter clause parsing (see question of the week below)
Demo: Pinot batch insertion and query using Trino Pinot connector
To put this PR to the test, we set up a Pinot cluster using Docker Compose.
To load the data, we’re going to use a simple batch import, but you can also insert the data in a stream using Kafka.
Let’s start up the Pinot cluster along with the required Zookeeper and Kafka
broker. Clone this repository and navigate to the pinot/trino-pinot directory.
git clone [email protected]:bitsondatadev/trino-getting-started.git
cd community_tutorials/pinot/trino-pinot
docker-compose up -d
To do batch insert, we will stage a csv file to read the data in. Create a directory underneath a temp folder locally and then submit this to Pinot.
mkdir -p /tmp/pinot-quick-start/rawdata
echo "studentID,firstName,lastName,gender,subject,score,timestampInEpoch
200,Lucy,Smith,Female,Maths,3.8,1570863600000
200,Lucy,Smith,Female,English,3.5,1571036400000
201,Bob,King,Male,Maths,3.2,1571900400000
202,Nick,Young,Male,Physics,3.6,1572418800000" > /tmp/pinot-quick-start/rawdata/transcript.csv
In order for Pinot to understand the CSV data, we must provide it a schema.
echo "{
\"schemaName\": \"transcript\",
\"dimensionFieldSpecs\": [
{
\"name\": \"studentID\",
\"dataType\": \"INT\"
},
{
\"name\": \"firstName\",
\"dataType\": \"STRING\"
},
{
\"name\": \"lastName\",
\"dataType\": \"STRING\"
},
{
\"name\": \"gender\",
\"dataType\": \"STRING\"
},
{
\"name\": \"subject\",
\"dataType\": \"STRING\"
}
],
\"metricFieldSpecs\": [
{
\"name\": \"score\",
\"dataType\": \"FLOAT\"
}
],
\"dateTimeFieldSpecs\": [{
\"name\": \"timestampInEpoch\",
\"dataType\": \"LONG\",
\"format\" : \"1:MILLISECONDS:EPOCH\",
\"granularity\": \"1:MILLISECONDS\"
}]
}" > /tmp/pinot-quick-start/transcript-schema.json
Now we are almost ready to create the table. Instead of adding table configurations as part of the SQL command, Pinot enables you to store table configurations as a file. This is a nice option that decouples the DDL which makes for simpler scripting in batch setups.
echo "{
\"tableName\": \"transcript\",
\"segmentsConfig\" : {
\"timeColumnName\": \"timestampInEpoch\",
\"timeType\": \"MILLISECONDS\",
\"replication\" : \"1\",
\"schemaName\" : \"transcript\"
},
\"tableIndexConfig\" : {
\"invertedIndexColumns\" : [],
\"loadMode\" : \"MMAP\"
},
\"tenants\" : {
\"broker\":\"DefaultTenant\",
\"server\":\"DefaultTenant\"
},
\"tableType\":\"OFFLINE\",
\"metadata\": {}
}" > /tmp/pinot-quick-start/transcript-table-offline.json
Once you create these three files and verify that docker containers are running,
we can now run the Add Table command:
docker run --rm -ti \
--network=trino-pinot_trino-network \
-v /tmp/pinot-quick-start:/tmp/pinot-quick-start \
--name pinot-batch-table-creation \
apachepinot/pinot:latest AddTable \
-schemaFile /tmp/pinot-quick-start/transcript-schema.json \
-tableConfigFile /tmp/pinot-quick-start/transcript-table-offline.json \
-controllerHost pinot-controller \
-controllerPort 9000 -exec
Now that the table exists, we can see it in the Pinot web UI. Let’s insert some data using a batch job specification:
echo "executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: '/tmp/pinot-quick-start/rawdata/'
includeFileNamePattern: 'glob:**/*.csv'
outputDirURI: '/tmp/pinot-quick-start/segments/'
overwriteOutput: true
pinotFSSpecs:
- scheme: file
className: org.apache.pinot.spi.filesystem.LocalPinotFS
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'transcript'
schemaURI: 'http://pinot-controller:9000/tables/transcript/schema'
tableConfigURI: 'http://pinot-controller:9000/tables/transcript'
pinotClusterSpecs:
- controllerURI: 'http://pinot-controller:9000'" > /tmp/pinot-quick-start/docker-job-spec.yml
Now run this batch job by running the LaunchDataIngestionJob task.
docker run --rm -ti \
--network=trino-pinot_trino-network \
-v /tmp/pinot-quick-start:/tmp/pinot-quick-start \
--name pinot-data-ingestion-job \
apachepinot/pinot:latest LaunchDataIngestionJob \
-jobSpecFile /tmp/pinot-quick-start/docker-job-spec.yml
We modified this demo from the tutorials available on the Pinot website:
- https://docs.pinot.apache.org/basics/getting-started/pushing-your-data-to-pinot
- https://docs.pinot.apache.org/basics/getting-started/running-pinot-in-docker
Question of the week: Why does my passthrough query not work in the Pinot connector?
The passthrough queries may be failing due to upper case constants that need to
be surrounded with UPPER(). For example 'Foo' in this query would be
rendered as all lowercase once it is passed to Pinot:
SELECT *
FROM "SELECT col1, col2, COUNT(*) FROM pinot_table WHERE col2 = 'FOO' GROUP BY col1, col2"
The fix is to pass 'Foo' to UPPER() in the passthrough query.
SELECT *
FROM "SELECT col1, col2, COUNT(*) FROM pinot_table WHERE col2 = UPPER('FOO') GROUP BY col1, col2"
It could also be due to parsing of functions in filters. A workaround is to put
the filter outside of the double quotes, which can work in some cases. For
example, column table names can be mixed case as the connector will auto resolve
them. If there are mixed case constants would not work with upper():
SELECT *
FROM "SELECT col1, col2, COUNT(*) FROM pinot_table WHERE col2 = 'Foo' GROUP BY col1, col2"
The filter can be hoisted into the outer query:
SELECT *
FROM "SELECT col1, col2, COUNT(*) FROM pinot_table GROUP BY col1, col2" WHERE col2 = 'Foo';
There is ongoing work to improve this parsing: Pinot filter clause parsing (PR 7161).
Events, news, and various links
Blogs
- https://medium.com/apache-pinot-developer-blog/real-time-analytics-with-presto-and-apache-pinot-part-i-cc672caea307
- https://medium.com/apache-pinot-developer-blog/real-time-analytics-with-presto-and-apache-pinot-part-ii-3d09ff937713
- https://medium.com/apache-pinot-developer-blog/exploring-olap-on-kubernetes-with-apache-pinot-32f12233dc0b
- https://medium.com/apache-pinot-developer-blog/building-a-climate-dashboard-with-apache-pinot-and-superset-d3ee8cb7941d
- https://medium.com/apache-pinot-developer-blog
- https://leventov.medium.com/comparison-of-the-open-source-olap-systems-for-big-data-clickhouse-druid-and-pinot-8e042a5ed1c7
Trino Meetup Groups
- Virtual
- https://www.meetup.com/trino-americas/
- https://www.meetup.com/trino-emea/
- Trino APAC - Coming Soon
- East Coast
- West Coast
- Mid West
Latest training from David, Dain, and Martin(Now with timestamps!):
- https://trino.io/blog/2020/07/15/training-advanced-sql.html
- https://trino.io/blog/2020/07/30/training-query-tuning.html
- https://trino.io/blog/2020/08/13/training-security.html
- https://trino.io/blog/2020/08/27/training-performance.html
If you want to learn more about Trino, check out the definitive guide from OReilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.