Video
- Concept of the week: Trino and dbt, a hot data mesh (935s)
- PR of the week: Partitioned table tests and fixed PR 9757 (5055s)
- Question of the week: What’s the difference between location and external_location? (5298s)
Audio
Guests
- José Cabeda, Data Engineer at Talkdesk (@jecabeda).
- Przemek Denkiewicz, Cloud Ecosystem Engineer at Starburst (@hovaesco).
Trino Summit 2021
If you missed Trino Summit 2021, you can watch it on demand, for free!
Release 364
Trino 364 shipped on the first of November, just after our last episode. Martin’s official announcement mentioned the following highlights:
- Support for dynamic filtering in Iceberg connector
- Performance improvements when querying small files
- Procedure to merge small files in Hive tables
- Support for Cassandra UUID type
- Support for MemSQL datetime and timestamp types
Manfred’s additional notes:
ALTER MATERIALIZED VIEW ... RENAME TO- A whole bunch of performance improvements
- Elasticsearch connector no longer fails with unsupported types
- A lot of improvements on Hive and Iceberg connectors
- Hive connector has optimize procedure now!
- Parquet and avro fixes and improvements
- Web UI performance improvement for long query texts
More detailed information is available in the release notes.
Concept of the week: Trino and dbt, a hot data mesh
Data mesh, the buzzword that follows data lakehouse, may feel rather irrelevant for many. This is especially true for those that just want to move from a Hive and HDFS cluster to storing data in object store, or from a cloud data warehouse and query it with Trino.
While data mesh is certainly in the hype cycle phase, it’s actually not a new idea and has very sound principles. Many companies have written their own software and created organizational policies that align with the strategies outlined by the data mesh principles. In essence, these principles aim to make data management for analytics platforms decentralized. This means decentralizing the infrastructure and data engineers managing it to different domains (or products) within a company.
What’s really exciting about data mesh is that much of the technology today makes these theoretical principles more of a reality without having to invent your own services. The author of data mesh, Zhamak Dehghani, lays out 4 principles that characterize a data mesh:
- Domain-oriented, decentralized data ownership and architecture
- Data as a product
- Self-serve data infrastructure as a platform
- Federated computational governance
Let’s see what the engineers from Talkdesk are doing to implement their data mesh.
Talkdesk
Talkdesk is a contact center as a service. Talkdesk was created at a Twilio Hackathon in 2011. They just hit a 10 billion dollar valuation. As a fast growing startup, they are growing their product strategy at a fast pace, and deal with a large data sets to analyze regularly.

The Talkdesk product is deployed in cloud infrastructure and provides all the infrastructure for operating a call center. Its architecture is heavily event-driven. Dealing with realtime events at scale is difficult and requires a reactive and flexible architecture.
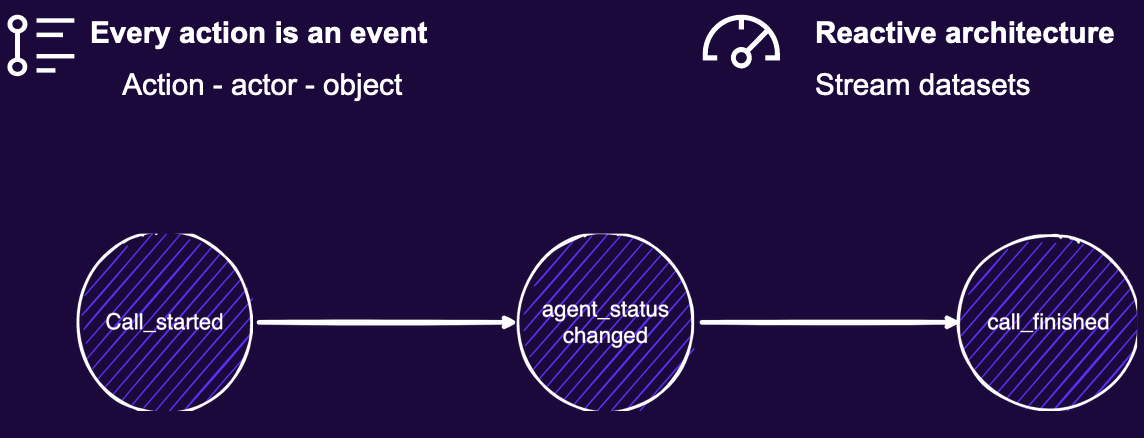
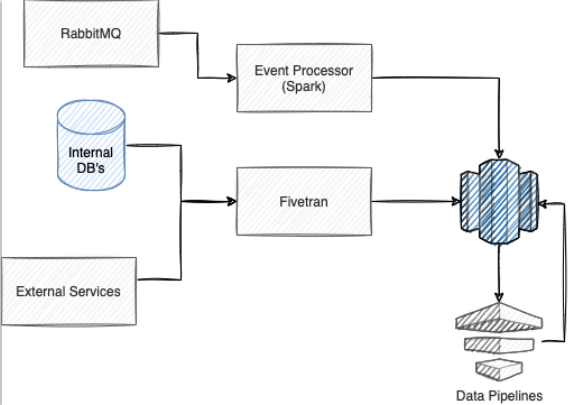
The early architecture for the analytics platform followed a traditional approach using Spark and Fivetran to ingest data into Redshift. It had various pipelines to update the data for downstream consumption.
This centralized workflow made communication across data entity management much simpler as it all exists on the same team. However, scaling caused increased backlogs, which delayed analysis and deployments. It also made it difficult to handle different use cases like realtime and historical use cases.
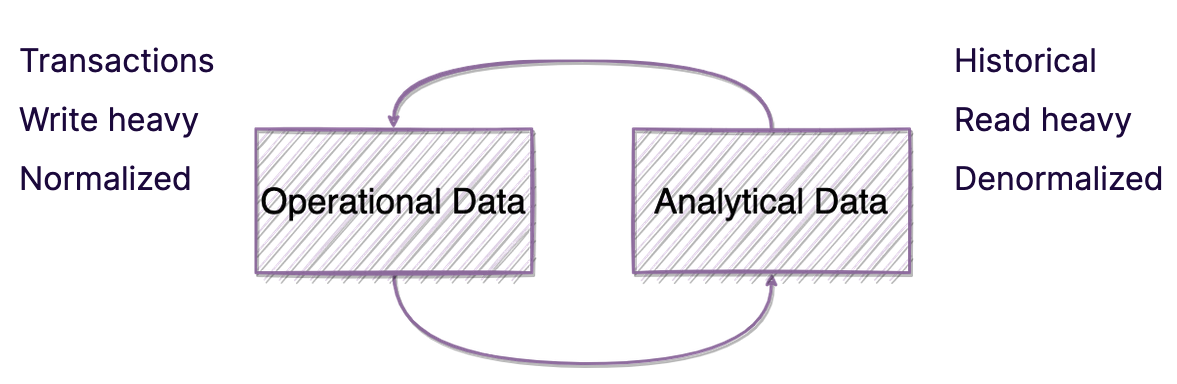
The use cases between analytics and transactional are varied and overlapping. Live data typically feeds into stateful databases that updates as data arrives. To analyze data in motion, you need a realtime database. Historical data exists to keep a backup of multiple copies of different states over time. This enables trend analysis over longer periods of time versus right now. One challenge Talkdesk faced was realizing a robust architecture that satisfies analyzing live data that gets the latest changes as they arrive to OLTP databases while meeting all the analytics use cases.
To enable analytics across the various use cases, Talkdesk integrated Trino into their workflow to read data across both live and historic data and merge them. Using Trino enabled reading from live data feeding into their stateful data stores, and reads across historic data stores to produce data in the form needed to support Talkdesk products.
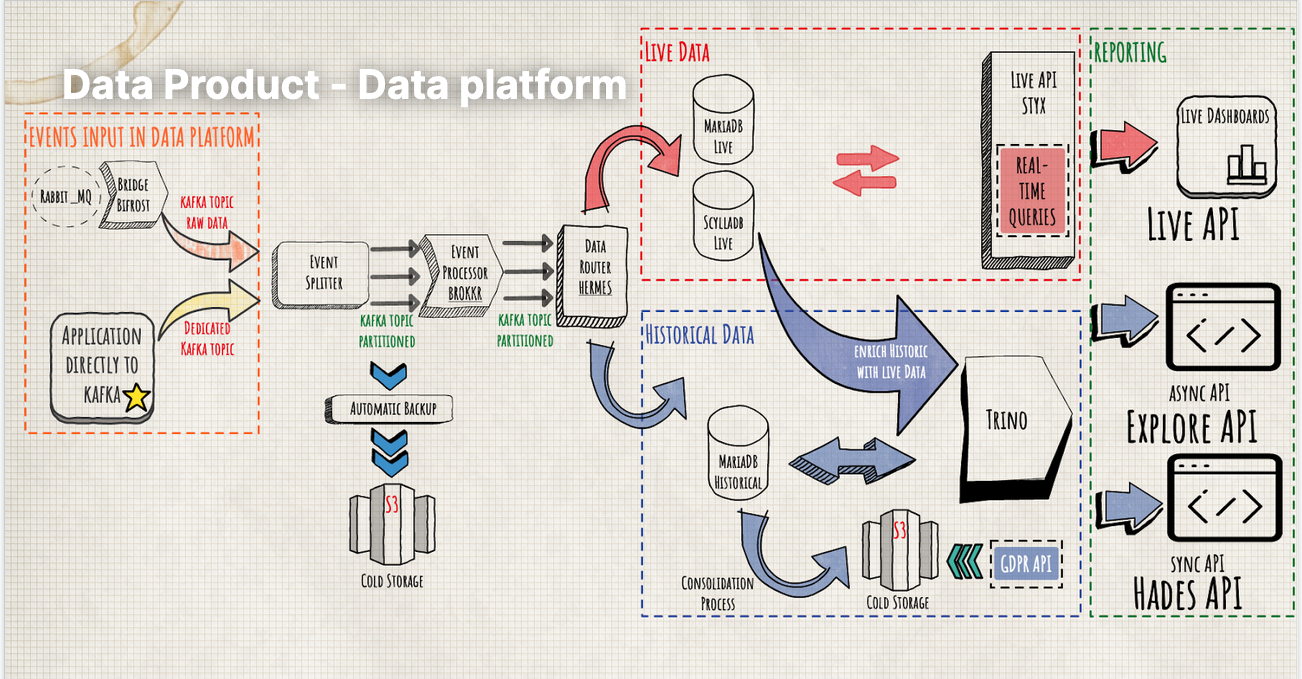
Trino is also used to hide the complexity of the data platform, and allows merging data across mulitple relational and object stores.
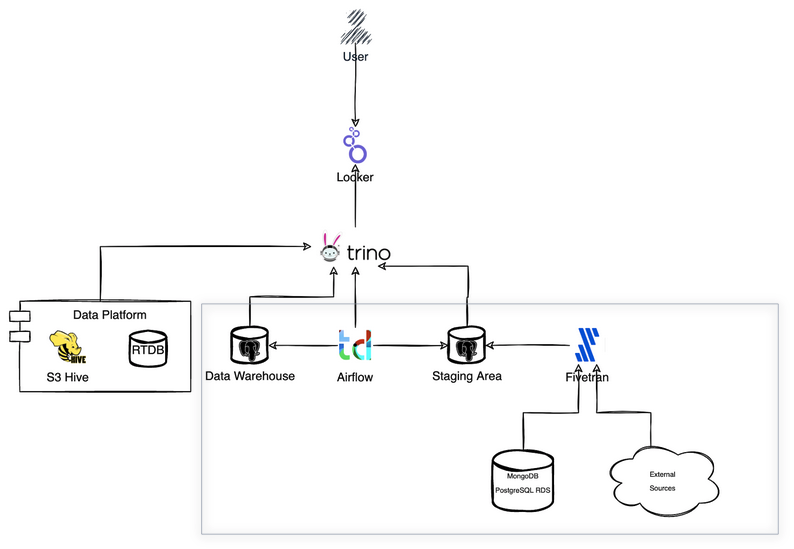
Why dbt?
In episode 21 we discussed using dbt and Trino in detail. As we mentioned there:
dbt is a transformation workflow tool that lets teams quickly and collaboratively deploy analytics code, following software engineering best practices like modularity, CI/CD, testing, and documentation. It enables anyone who knows SQL to build production-grade data pipelines.
You can achieve modular, repeatable, and testable units of processing by defining various models and definitions to the data pipelines. For example:
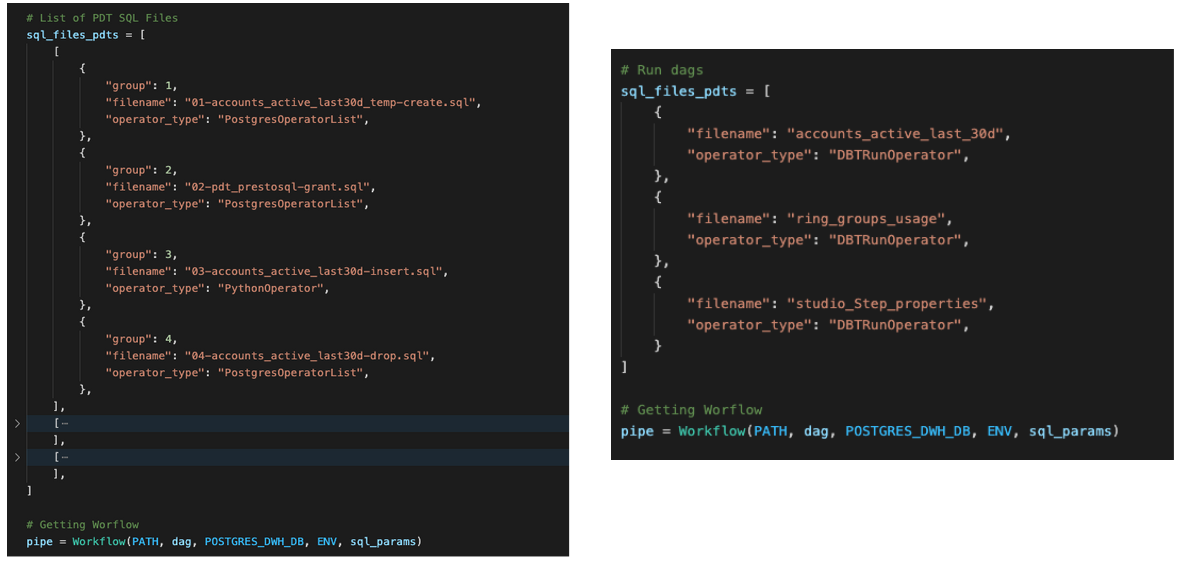
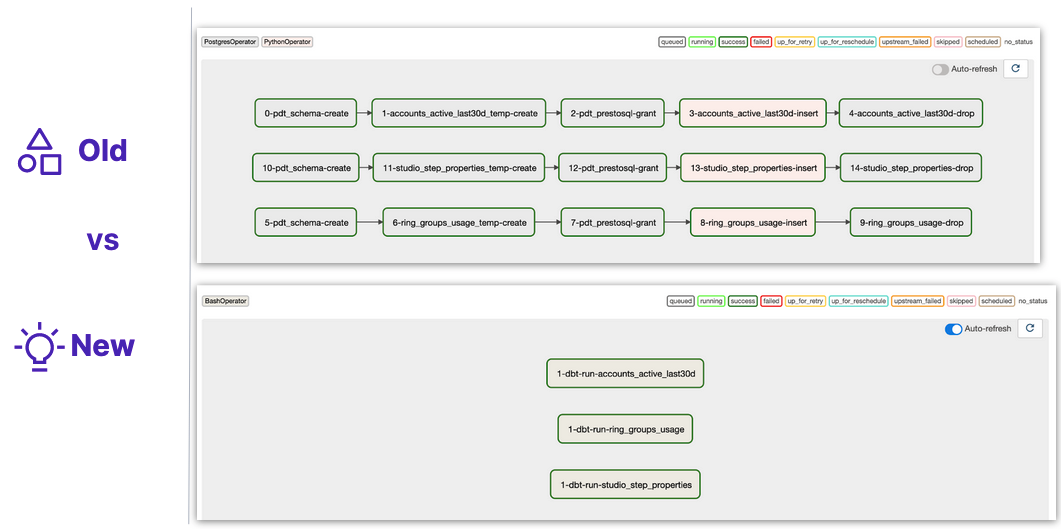
Using the definitions above, Talkdesk engineers were able to consolidate all these tasks into a much more simplified graph of operations.
Why data mesh?
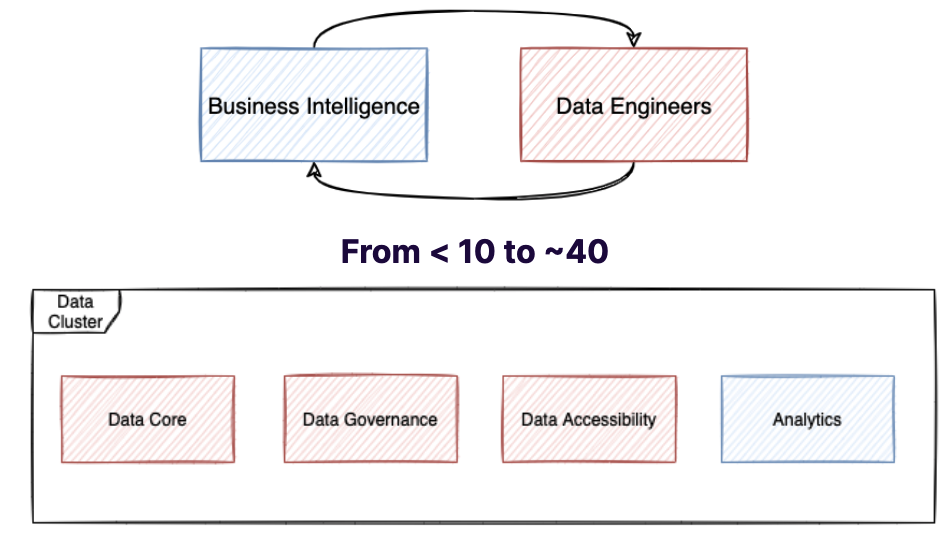
While a lot of focus has gone into the technology aspects of data mesh, there is also a lot to be said about the implications on the data team and socio-political policies that come with data mesh. Talkdesk also made structural changes to their team to improve their data mesh strategy.
How data mesh affects the everyday life of data engineers?
There is a real fear that comes around when management changes business policies. It can be hard to tell how these policies trickle down and affect the engineer’s every day work life. In general, engineers become more entrenched in different domains rather than trying to manage all domains under one architecture. Data engineers are distributed to product teams and specialize in the domain’s data models. They also have specific knowledge of how to use the self-service platform to integrate across other teams.
Comparing microservices-based applications to the data mesh
When we think of a functional system for deploying and managing microservices-based applications, there are several features that we’ve come to expect. It is very easy to compare the features of microservices-based applications to features of a data mesh. Data Mesh: A Software Engineer’s Perspective blog.
PR of the week: Partitioned table tests and fixed PR 9757
This weeks PR of the week is for the Iceberg connector. Release 364 had quite a few improvements for Iceberg and handled small issues that could cause query failure in some scenarios. This PR addressed a query failure when reading a partition on a UUID column.
Thanks to Piotr Findeisen for fixing this and many other bugs, as well as, improving performance in the Iceberg connector!
Question of the week: What’s the difference between location and external_location?
This week’s question of the week comes from Aakash Nand on Slack and ported to Trino Forum. Aakash asks:
When creating a Hive table in Trino, what is the difference between
external_locationandlocation. If I have to create external table I have to useexternal_locationright? What is the difference between these two?
This was answered Arkadiusz Czajkowski:
Tables created with
locationare managed tables. You have full control over them from their creation to modification. tables created withexternal_locationare tables created by third party systems. We just access them mostly for read. I would encourage you to use location in your case.
Events, news, and various links
Blogs and resources
- Trino + dbt = a match made in SQL heaven? Blog
- Trino + dbt = a match made in SQL heaven? TCB episode
- Data Mesh Principles
- Data Mesh: A Software Engineer’s Perspective
Trino Meetup groups
- Virtual
- East Coast (US)
- West Coast (US)
- Mid West (US)
If you want to learn more about Trino, check out the definitive guide from OReilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.