Video
- Concept of the week: Trino clients, Python, and Apache Superset (463s)
- PR of the week: Superset PR 13105 feat: first step native support Trino (1076s)
- Demo: Superset querying Trino to create visualization dashboard (2523s)
- Question of the week: How do I use the Trino REST api? (2523s)
Audio
Guests
- Srini Kadamati, Developer Advocate at Preset (@SriniKadamati)
- Dr. Beto Dealmeida, Staff Engineer at Preset (@dealmeida)
Release 353 – Almost
353 is right around the corner. Last show we said this would be a small release. While there was a correctness issue we resolved, there didn’t seem to be much demand to get it out quick as we initially thought. So it was decided to continue adding more features to 353. It should be coming out shortly!
Concept of the week: Trino clients, Python, and Apache Superset
What is the general data flow from a connected data source?
- Trino workers request data from the data source with specific connector
- Workers process data and send it to the coordinator
- Coordinator does final processing
- Supplies the data via HTTP / REST stream to requestor
- Requestor is a “client” such as JDBC driver, or Trino CLI
- Client translates data further and provides to application (Java application using JDBC driver) or user interface/directly to user (output in CLI)
- User views part of data and scrolls down
- Client requests more data from coordinator via HTTP / REST (and see above)
What clients are provided by Trino project?
What other clients are there?
- ODBC driver from Starburst
- Various other clients from the open source community
- R
- NodeJS/Javascript
What happens in the Python world?
Disclaimer: I am not a Pythonista or Pythoneer.
- DB-API 2.0
- PEP 249 https://www.python.org/dev/peps/pep-0249/
- Python standard library
- trino-python-client
- Wraps complexity of Trino HTTP / REST
- Supports authentication and such
- Provides DB API endpoints / implementation
- Preferred method to query Trino
- SQLAlchemy https://www.sqlalchemy.org/
- SQL toolkit
- ORM mapper
- Widely used, eg. in Apache Superset
- Supports dialects
- PyHive
- Not really a SQL wrapper
- Aimed at Hive QL
- Only kind of useful for Trino, limited compatibility
- JDBC driver (Java !) and PySpark
- Possible, but a hack really
- PyJDBC
- Wraps DB API around any JDBC driver
- Kind of a hack since it goes through JDBC to HTTP, when Trino python client does the same more directly
- PyODBC
- Similar hack to PyJDBC
- Potentially also possible to talk to via HTTP directly
- That’s like reimplementing the trino-python-client
- Also see question of the week later
Beyond that, it will vary from application to application.
Let’s find out from our guests how this hangs together in Apache Superset, since it is using Python.
PR of the week: Superset PR 13105 feat: first step native support Trino
In this week’s pull request https://github.com/apache/superset/pull/13105 that was graciously added by dungdm93.
The first thing we need to understand about this addition is the concept of a database engine in Superset. A database engine handles a lot of the custom interactions between various databases and maps them to the interface that Superset understands. If certain concepts are missing in a certain database, like time granularity or SQL syntax, the database engine for that database indicated to Superset that this is not available. As a result the option does not show in Superset, or a concise error message is reported. By default, database engines use the base.py methods, but each engine, like Trino, add the custom mappings with a specific engine implementation, trino.py.
The pull request adds a few basic custom changes to enable Trino usage with Superset. One change ensures that complex timestamps from Trino are truncated to a format that Superset is able to support during time aggregation operations.
This opens a vast amount of functionality for using Trino and Superset. We wanted to feature this because it goes to show how a small code change, even one that is not in the Trino repository, can have a vast effect on those using Superset and Trino.
Thank you so much to dungdm93 for making this change and further linking Trino into a fantastic project like Apache Superset!
Demo: Superset querying Trino to create visualization dashboard
To put this PR to the test, we need to connect Apache Superset to Trino as our datasource.
First, you need to follow these instructions to install Docker (if you don’t already have it installed), and then clone the Superset repository:
$ git clone https://github.com/apache/superset.git
Next, you need to set up the database driver for Trino. Navigate to the root directory of the local Superset repository you just downloaded and run the following.
echo "sqlalchemy-trino" >> ./docker/requirements-local.txt
This tells Superset scripts to install the sqlalchemy-trino library upon startup. We know the name by looking up the Trino driver page for the driver documentation and how to use the connection string. If you were to install these directly on a Superset node, you would refer to this database drivers page.
Now run the following command to start up Superset and make sure you’re in the root folder of the repo.
docker-compose -f docker-compose-non-dev.yml up.
After Superset is running, you need to start Trino as well. We did so using a separate docker-compose app.
As soon as this is done, you can navigate to Superset’s homepage http://localhost:8088 and scroll to the Data > Databases menu.
Click the +Database button.
Set Name to “Trino” and URI to trino://[email protected]:8080
and click Add.
If you want to allow CTAS, CVAS, or DML operations, you’ll want to edit the Database you just created and click on the SQL LAB SETTINGS tab and select in the operations you want to allow.
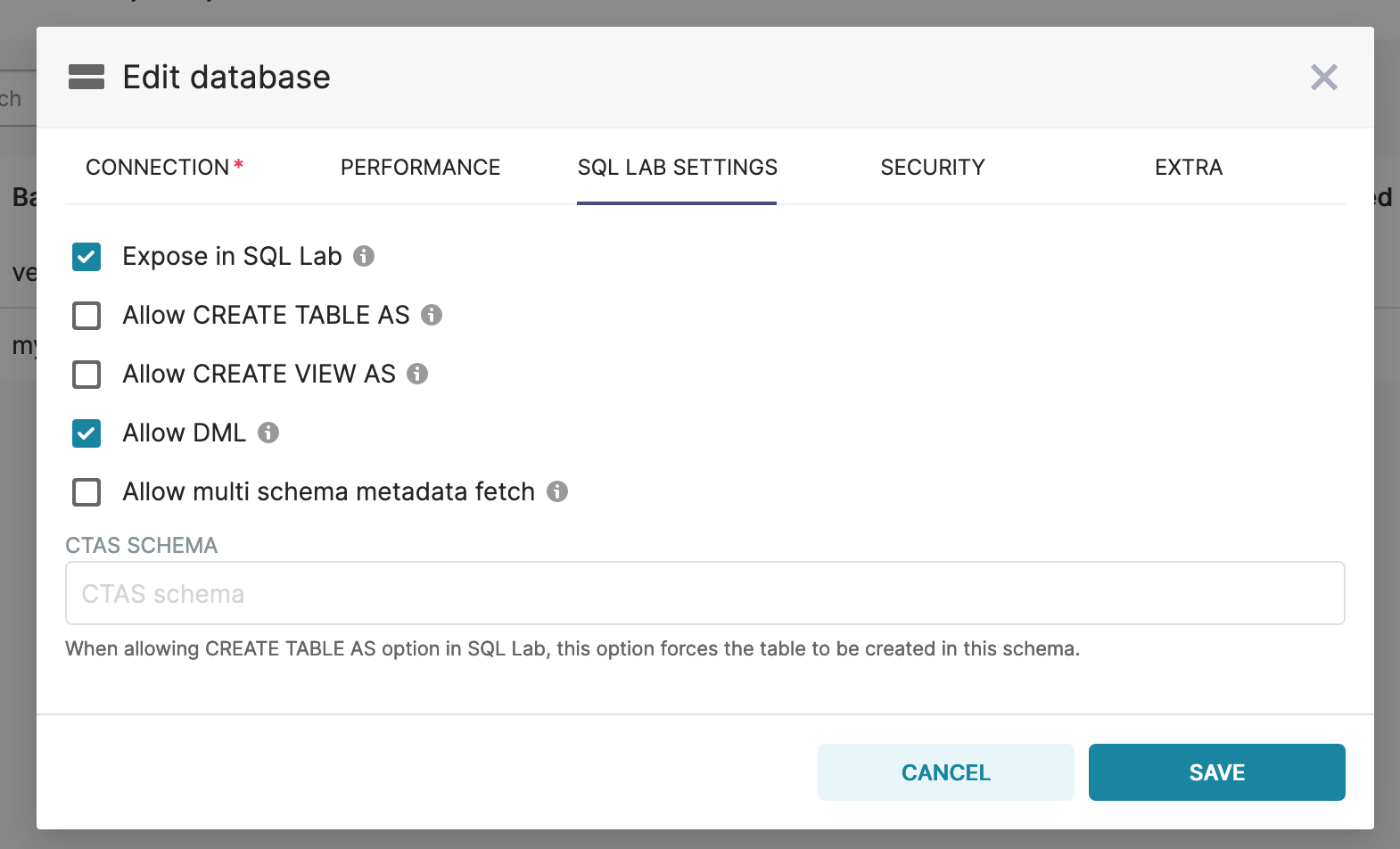
Connection settings that allows for creation/manipulation of tables.
You should be able to verify under SQL Lab > SQL Editor and run a SELECT query.
We cover adding charts and creating a dashboard in the show. We linked some blogs from Preset around how to do a lot of this workflow in great detail. Find these blogs linked below! Here’s a taste of what we created in Superset with some BTS On-Time : Reporting Carrier On-Time Performance (1987-present) and Covid Cases reported by the CDC.
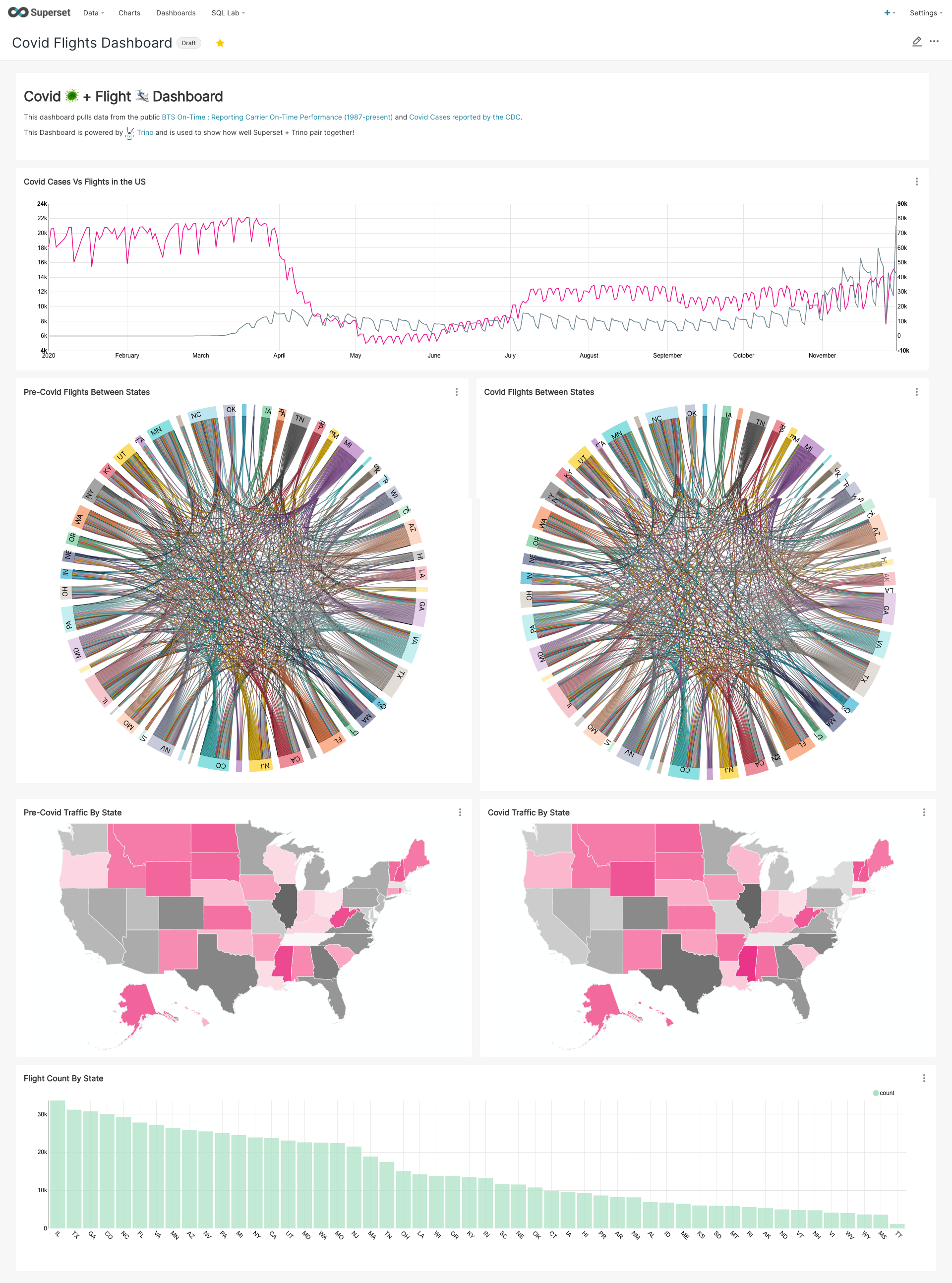
COVID-19 and flights data dashboard!
Question of the week: How do I use the Trino REST api?
I want to just use the REST API of Trino. Where is the documentation? How do I do that?
The short answer:
Don’t do that. Use a Trino client instead.
The long answer:
The typical desired use case for using the REST API is to run a query and get the result. However that part of the API is not really a traditional REST API (HTTP POST, HTTP GET). That just doesn’t work for large datasets to be returned. Instead, it is a constant open connection and stream of data and interaction between client and Trino.
The clients take care of all this complexity and provide it in standard API for the various platforms (JDBC, …). Use the clients!
And if there is no client, or the existing client is not good enough. Create an open source one or contribute improvements.
The exception:
There are other simple, pure REST API endpoints that you can use just straight out of the box. Try http://localhost:8080/v1/info or http://localhost:8080/v1/status. You could use those for a liveness/readiness probe in k8s or for cluster status display. By the way, the Web UI uses those and others..
Last note
If you really can’t help yourself, here are some docs. https://github.com/trinodb/trino/wiki/HTTP-Protocol
Events, news, and various links
Blogs
- https://preset.io/blog/2021-03-03-druid-prophet-pt1/
- https://preset.io/blog/2021-02-11-superset-geodata/
- https://preset.io/blog/2021-01-18-superset-1-0/
- https://preset.io/blog/2021-1-18-recap-2020/
- https://preset.io/blog/2020-09-22-slack-dashboard/
- https://preset.io/blog/2020-10-02-slack-dashboard-part-2/
- https://preset.io/blog/2020-10-08-bigquery-superset-part-2/
Latest training from David, Dain, and Martin(Now with timestamps!):
- https://trino.io/blog/2020/07/15/training-advanced-sql.html
- https://trino.io/blog/2020/07/30/training-query-tuning.html
- https://trino.io/blog/2020/08/13/training-security.html
- https://trino.io/blog/2020/08/27/training-performance.html
If you want to learn more about Trino, check out the definitive guide from OReilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.