Audio
Video
Video sections
- Concept of the week: Apache Druid and realtime analytics (891s)
- PR of the week: PR 3522 Add Druid connector (2015s)
- Demo: Using the Druid Web UI to create an ingestion spec querying via Trino (3689s)
- Question of the week: Does the Druid connector? (4220s)

Commander Bun Bun the speedy druid!
Druid links
Guests
- Samarth Jain, Software Engineer at Netflix (@samarthjain11)
- Parth Brahmbhatt, Senior Software Engineer at Netflix (@brahmbhattparth)
- Rachel Pedreschi, VP Community and Developer Relations at Imply (@rachelpedreschi)
Release 356
Release notes discussed: https://trino.io/docs/current/release/release-356.html
- General:
- MATCH_RECOGNIZE clause support, used to detect patterns in a set of rows within a single query
- soundex function
- Property to limit planning time (and improved behavior about cancel during planning)
- A bunch of performance improvements around pushdown (and start of docs for pushdowns)
- Misc improvements around materialized views support
- JDBC driver - OAuth2 token caching in memory
- BigQuery - create and drop schema
- Hive - Parquet, ORC and Azure ADL improvements
- Iceberg - SHOW TABLES even when tables created elsewhere
- Kafka - SSL support
- Metadata caching improvements for a bunch of connectors
- SPI: couple of changes
Concept of the week: Apache Druid and realtime analytics
This week covers Apache Druid, a modern, real-time OLAP database. Joining us is the head of developer relations at Imply, the company that creates an enterprise version of Druid, to cover what Druid is, and the use cases it solves.
Here are the slides that Rachel uses in the show:
Druid Architecture
Druid has several process types:
- Coordinator processes manage data availability on the cluster.
- Overlord processes control the assignment of data ingestion workloads.
- Broker processes handle queries from external clients.
- Router processes are optional processes that can route requests to Brokers, Coordinators, and Overlords.
- Historical processes store queryable data.
- MiddleManager processes are responsible for ingesting data.
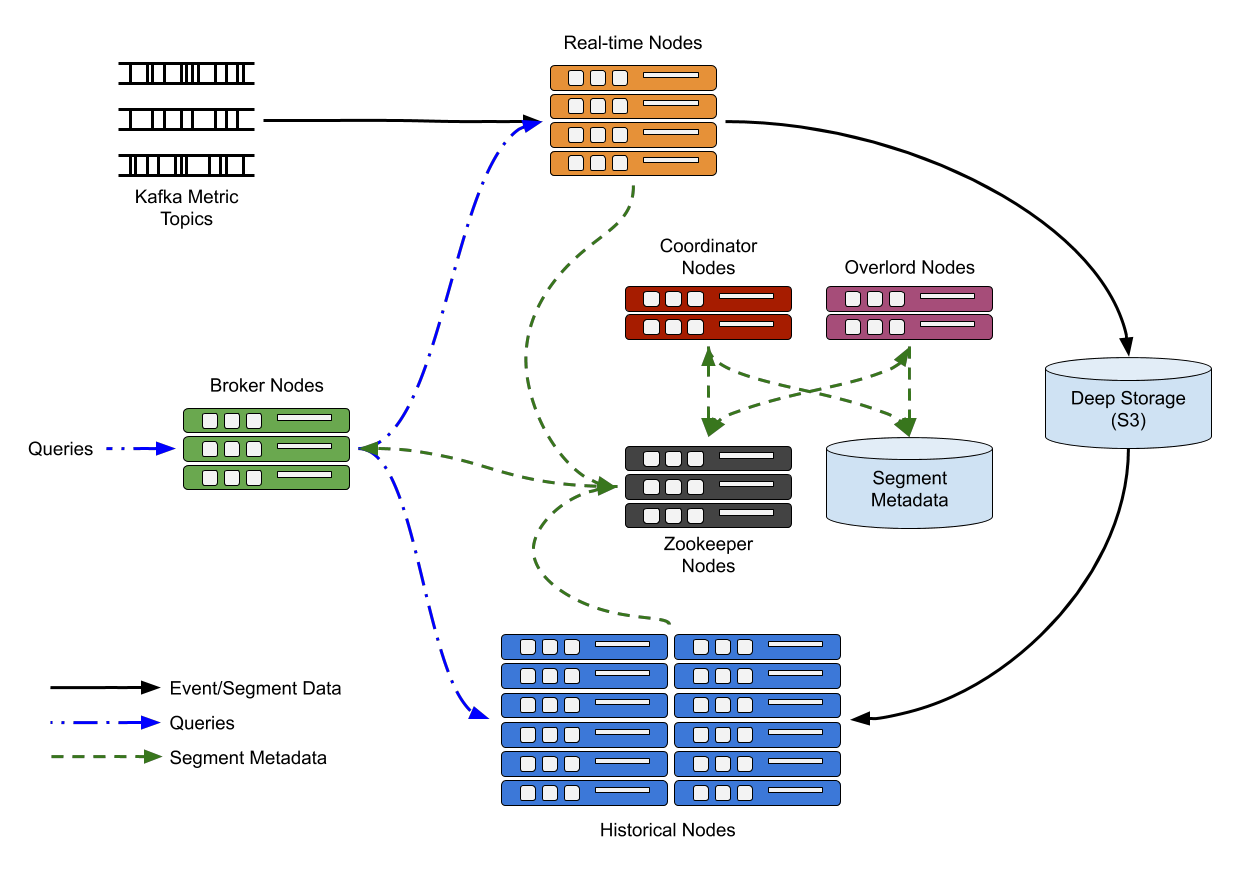
The Druid architecture.
Druid processes can be deployed any way you like, but for ease of deployment we suggest organizing them into three server types: Master, Query, and Data.
- Master: Runs Coordinator and Overlord processes, manages data availability and ingestion.
- Query: Runs Broker and optional Router processes, handles queries from external clients.
- Data: Runs Historical and MiddleManager processes, executes ingestion workloads and stores all queryable data.
Source: https://druid.apache.org/docs/latest/design/architecture.html.
PR of the week: PR 3522 Add Druid connector
Our guest, Samarth, is the author of this weeks PR of the week. Puneet Jaiswal is the first engineer that started work to add a Druid connector. Later, Samarth picked up the torch and the Trino Druid connector became available in release 337.
An honorable mention goes to our other guest, Parth, for doing some preliminary work that enabled aggregation pushdown in the SPI. This enabled the use of the Druid connector to actually scale well with the completion of PR 4313 (see future work below).
A third honorable PR, that was completed by @findepi, was adding pushdown to the jdbc client which appeared in release 337 along with the Druid connector.
It is incredible to see the amount of hands that various features and connectors pass through to get to the final release.
Future work:
- SPI and optimizer rule for connectors that can support complete topN (PR 4249)
- Implement aggregate pushdown for Druid (PR 4313)
- Optimizer rule to support aggregate pushdown with grouping sets (PR 4554)
Demo: Using the Druid Web UI to create an ingestion spec querying via Trino
Let’s start up the Druid cluster along with the required Zookeeper and
PostgreSQL instance. Clone this repository and navigate to the trino-druid
directory.
git clone [email protected]:bitsondatadev/trino-getting-started.git
cd druid/trino-druid
docker-compose up -d
To do batch insert, navigate to the Druid Web UI once it has finished starting up at http://localhost:8888. Once that is done, click the “Load data” button, choose, “Example data”, and follow the prompts to create the native batch ingestion spec. Once the spec is created, run the job and ingest the data. More information can be found here: https://druid.apache.org/docs/latest/tutorials/index.html
The Druid architecture.
Once Druid completes the task, open up a Trino connection and validate that the
druid catalog exists.
docker exec -it trino-druid_trino-coordinator_1 trino
trino> SHOW CATALOGS;
Catalog
---------
druid
system
tpcds
tpch
(4 rows)
Now show the tables under the druid.druid schema.
trino> SHOW TABLES IN druid.druid;
Table
-----------
wikipedia
(1 row)
Run a SHOW CREATE TABLE to see the column definitions.
trino> SHOW CREATE TABLE druid.druid.wikipedia;
Create Table
--------------------------------------
CREATE TABLE druid.druid.wikipedia (
__time timestamp(3) NOT NULL,
added bigint NOT NULL,
channel varchar,
cityname varchar,
comment varchar,
commentlength bigint NOT NULL,
countryisocode varchar,
countryname varchar,
deleted bigint NOT NULL,
delta bigint NOT NULL,
deltabucket bigint NOT NULL,
diffurl varchar,
flags varchar,
isanonymous varchar,
isminor varchar,
isnew varchar,
isrobot varchar,
isunpatrolled varchar,
metrocode varchar,
namespace varchar,
page varchar,
regionisocode varchar,
regionname varchar,
user varchar
)
(1 row)
Finally, query the first 5 rows of data showing the user and how much they added.
trino> SELECT user, added FROM druid.druid.wikipedia LIMIT 5;
user | added
-----------------+-------
Lsjbot | 31
ワーナー成増 | 125
181.230.118.178 | 2
JasonAQuest | 0
Kolega2357 | 0
(5 rows)
Question of the week: Why doesn’t the Druid connector use the native json over http calls?
To answer this question I’m going to quote Samarth and Parth on this from this super long but enlightening thread on the subject.
Samarth’s take:
Pro JDBC:
-
Going forward, Druid SQL is going to be the de-facto way of accessing Druid data with native JSON queries being more of an advanced level use case. A benefit of down the SQL route is that we can take advantage of all the changes made in the Druid SQL optimizer land like using vectorized query processing when possible, when to use a TopN vs group by query type, etc. If we were to hit historicals directly, which don’t support SQL querying, we potentially won’t be taking advantages of such optimizations unless we keep porting/applying them to the trino-druid connector which may not always be possible.
-
If we end up letting a Trino node act as a Druid broker (which is what would happen I assume when you let a Trino node do the final merging), then, you would need to allocate similar kinds of resources (direct memory buffers, etc.) to all the Trino worker nodes as a Druid broker which may not be ideal.
-
This is not necessarily a limitation but adds complexity - with your proposed implementation, the Trino cluster will need to maintain state about what Druid segments are hosted on what data nodes (middle managers and historicals). The Druid broker already maintains that state and having to replicate and store all that state on the Trino coordinator will demand more resources out of it.
-
To your point on SCAN query overwhelming the broker - that shouldn’t be the case as Druid scan query type streams results through broker instead of materializing all of them in memory. See: https://druid.apache.org/docs/latest/querying/scan-query.html
Pro HTTP:
- One use case where directly hitting the historicals may help is when the group by key space is large (like a group by on UUID like column). For a very large data set, a Druid broker can get overwhelmed when performing the giant merge. By hitting historicals directly, we can let historicals do first level merge followed by multiple Trino workers doing the second level merge. I am not sure if solving for this limited use case is worth going the http native query route, though. IMHO, Druid generally isn’t built for pulling lots of data out of it. You can do it, but whether you want to push that work down to Druid cluster or let Trino directly pull it down for you is debatable.
I would advocate for going the Druid SQL route at least for the initial version of the connector. This would provide a solution for the majority of the use cases that Druid generally is used for (OLAP style queries over pre-aggregated data). We could in the next version of the connector, possibly focus on adding a new mode of the connector which can make native JSON queries directly to the Druid historicals and middle managers instead of submitting SQL queries to the broker.
Parth’s take:
Our general take is that Druid is designed as OLAP cube and so it is really fast when it comes to aggregate queries over reasonable cardinality dimensions and will not work well for use cases that are treating it like a regular data warehouse and trying to do pure select scans with filter. The primary reason most of our users would look to Trino’s Druid connector is:
-
To be able to join already aggregated data in Druid to some other datastore in our warehouse.
-
To gain access through tooling that doesn’t have good support for Druid inherently for dashboarding use cases (think Tableau).
Even if we wanted to support the use cases that Druid is not designed for in a more efficient manner by going thorough historicals directly, it has other implications. We are now talking about partial aggregation pushdown which is more complicated IMO than our current approach of complete pushdown. We could choose to take the approach that others have taken where we can incrementally add a mode to Druid connector to either use JDBC or go directly to historical, but I really don’t think it’s a good idea to block the current development in hopes of a more efficient future version specially when this is just implementation detail that we can switch anytime without breaking any user queries.
Events, news, and various links
Trino Summit: http://starburst.io/trinosummit2021
Blogs
- https://netflixtechblog.com/how-netflix-uses-druid-for-real-time-insights-to-ensure-a-high-quality-experience-19e1e8568d06
- https://imply.io/post/apache-druid-joins
- https://medium.com/gumgum-tech/optimized-real-time-analytics-using-spark-streaming-and-apache-druid-d872a86ed99d
- https://www.inovex.de/blog/a-close-look-at-the-workings-of-apache-druid/
- https://leventov.medium.com/comparison-of-the-open-source-olap-systems-for-big-data-clickhouse-druid-and-pinot-8e042a5ed1c7
Videos
- https://www.youtube.com/watch?v=mf8Hb0coI6o
- https://www.youtube.com/watch?v=Kxbzr7UP1dI&t=1274s
- https://www.youtube.com/watch?v=QNmSXMQ-gY4
Trino Meetup groups
- Virtual
- East Coast (US)
- West Coast (US)
- Mid West (US)
Latest training from David, Dain, and Martin(Now with timestamps!):
If you want to learn more about Trino, check out the definitive guide from OReilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.