Video
- Concept of the week: Resurface and the Resurface connector (538s)
- PR of the week: PR 4022 Add Soundex function (4097s)
- Demo: Using the soundex function (4227s)
- Question of the week: Question of the week: How to export query results into a file (e.g. CTAS, but into a single file)? (4726s)
Audio

Commander Bun Bun is diving deep to find anomalies!
Resurface links
Guests
- Rob Dickinson, Co-founder and CEO of Resurface (@robfromboulder)
- Martin Traverso, creator of Trino/Presto, and CTO at Starburst (@mtraverso)
Concept of the week: Resurface and the Resurface connector
What is Resurface?
Resurface is an API system of record, which is a fancy way of saying that Resurface is a purpose-built database for API requests and responses. Like a weblog or access log, but on steroids because Resurface runs on Trino.
Why do you need a system of record for your APIs? Because otherwise you’re guessing about how your APIs are used and attacked, and guessing doesn’t feel good. Resurface helps your DevOps and security teams instantly find API failures, slowdowns, and attacks – easily, responsibly, and at scale.
How Resurface differs from logs & metrics
You probably use system monitoring tools, which tell you about what’s happening on your systems. What code is running, what code is slow, and what error codes are returned. That’s all great — but it still leaves a big gap between the system-level events you can see, and what your API consumers actually see.
Resurface helps you fill this gap with your own API system of record. Now your customers, your DevOps team, and your security team all have the same view of every transaction, because there is a record of the requests and responses.
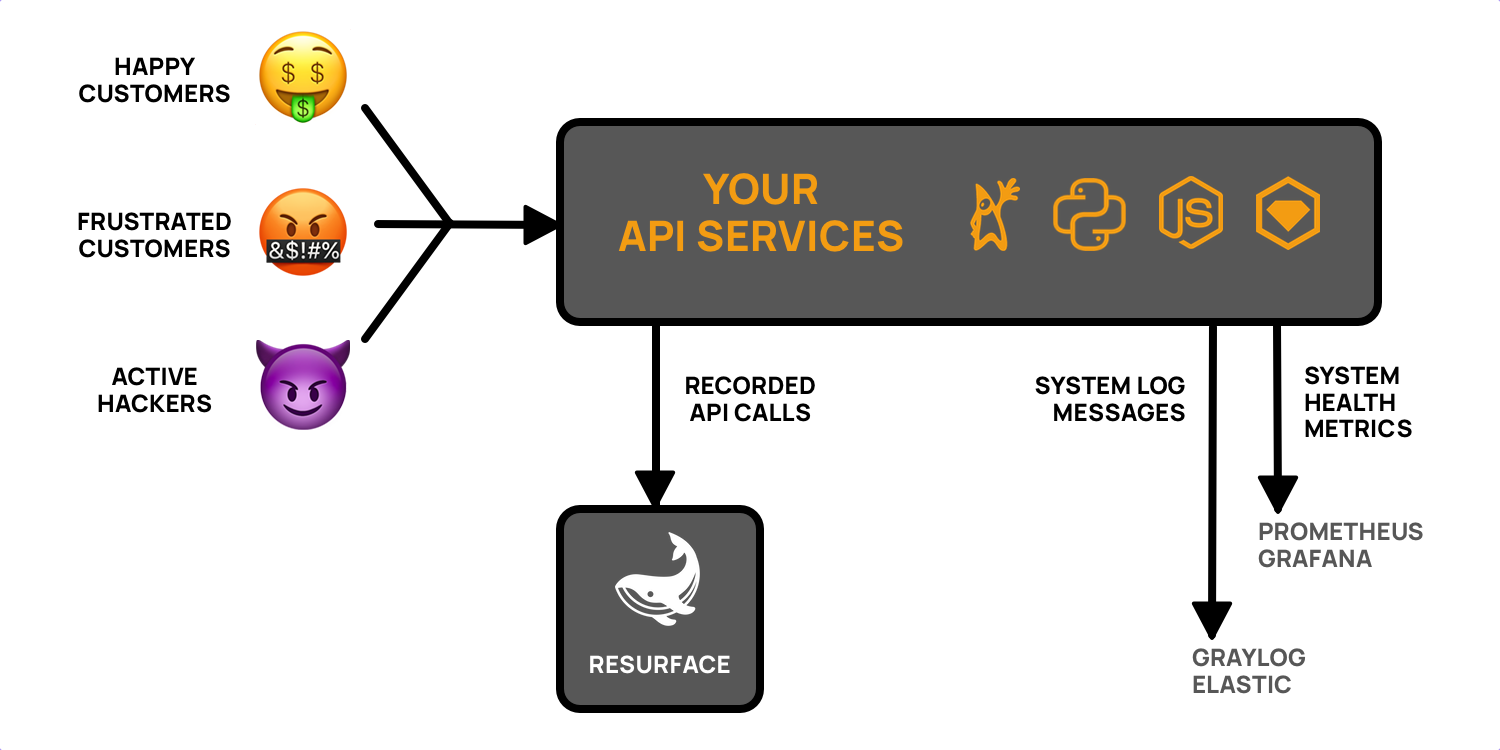
The other obvious way to compare Resurface against other tools is to look at the data model. System monitoring gives you time-series metrics, or timestamped log messages with a severity and detail string. Resurface gives you all the request and response data fields, including headers and payloads, in a schema where all of those fields are discrete and searchable. Plus it adds a bunch of helpful virtual and computed columns.

The indexing Problem
Resurface has a very descriptive data model, but there’s a problem here – how to partition and index this data for efficient searching. Partitioning based on time is the obvious starting point, but within a time range, what then? Index everything?
Most databases work best when a subset of the columns are constrained at once – but in their case, they have strong reasons for wanting to use all columns at once. A system monitoring tool might give you a count of “500 codes” – but they want to detect silent failures, like malformed JSON payloads or airline tickets selling for less than twenty dollars. That means looking at the URL, content type, other headers, and payloads, all at the same time.
They also want to classify kinds of API consumers by their behaviors – are they using or attacking your API? To classify those behaviors. Again, they look at the URL, content type, payloads. If they can query for the yellow region below, they find lost revenue that they can recover.
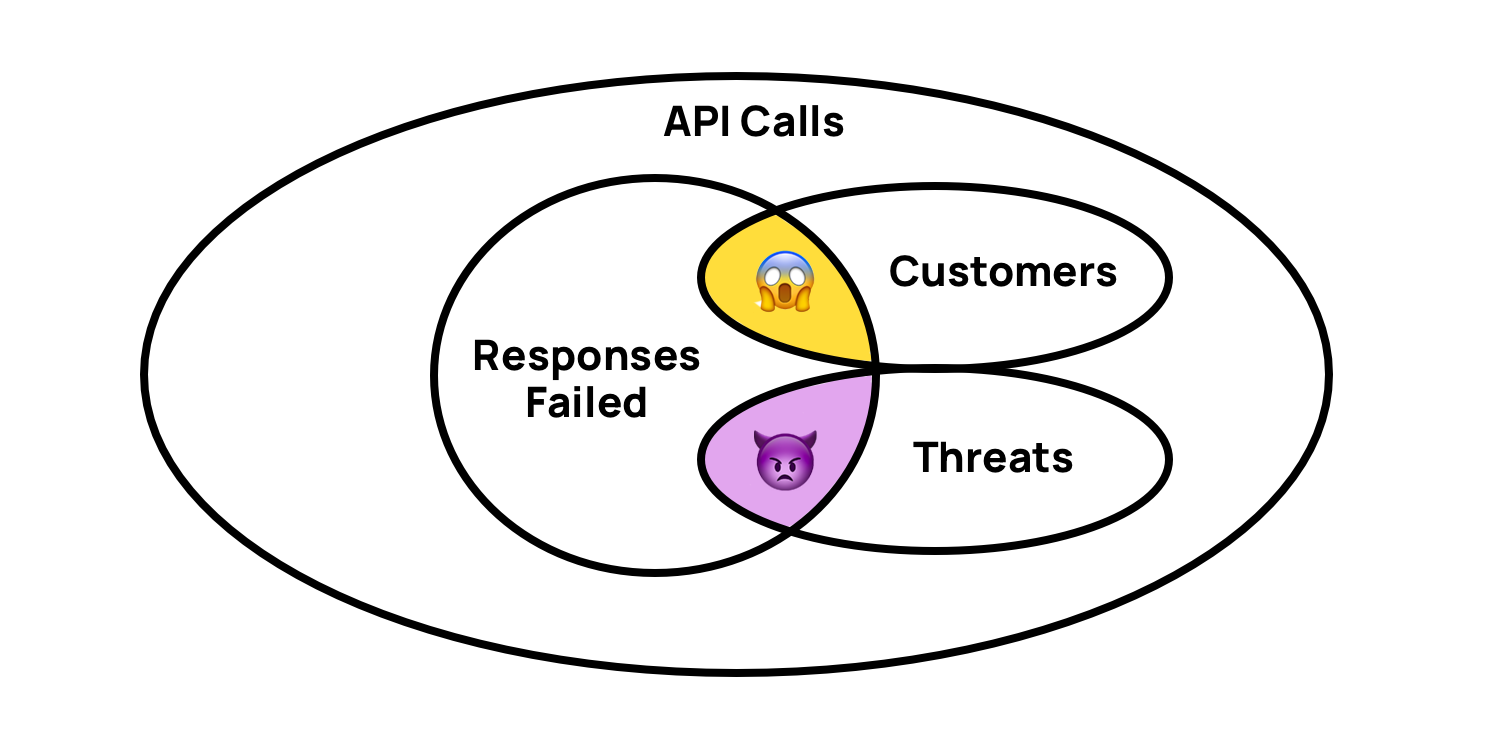
Now you might be thinking – maybe the best solution is to do all this processing when the API calls are captured, but then how would you identify a new zero-day failure or attack? The definition of “responses failed” and “threats” needs to be changeable without having to reprocess any data, which really favors query-time processing.
The example below is pretty much as simple as this gets. I struggled to find one of these queries that actually fits in a reasonable amount of space.

So how to build a database that does these kinds of queries in reasonable time?
The Resurface connector
The first prototype actually used the Trino memory connector, which gave them the kind of query performance that they were looking for, but wasn’t shippable (for obvious reasons).
Then they tried Redis as a replacement in-memory db, but the problem is that the queries are gonna pull all the data in Redis over the network for every query. Not cool.
Trino allows you to move the queries closer to the data, and so that’s what they did. They took inspiration from the “local file” connector, where the connector reads directly from the filesystem instead of over the network.
Then the question was, what file format to use? They tried JSON, CSV, Protocol Buffers, and ultimately found the fastest and simplest approach was just to write a simple binary file format that requires no real parsing. When these files fit in memory, their connector can process SQL queries at 4GB/sec per core. The connector was easy to write because they’re just mapping between fields in the binary files and the columns exposed to Trino. They built the first version of their connector in a weekend!
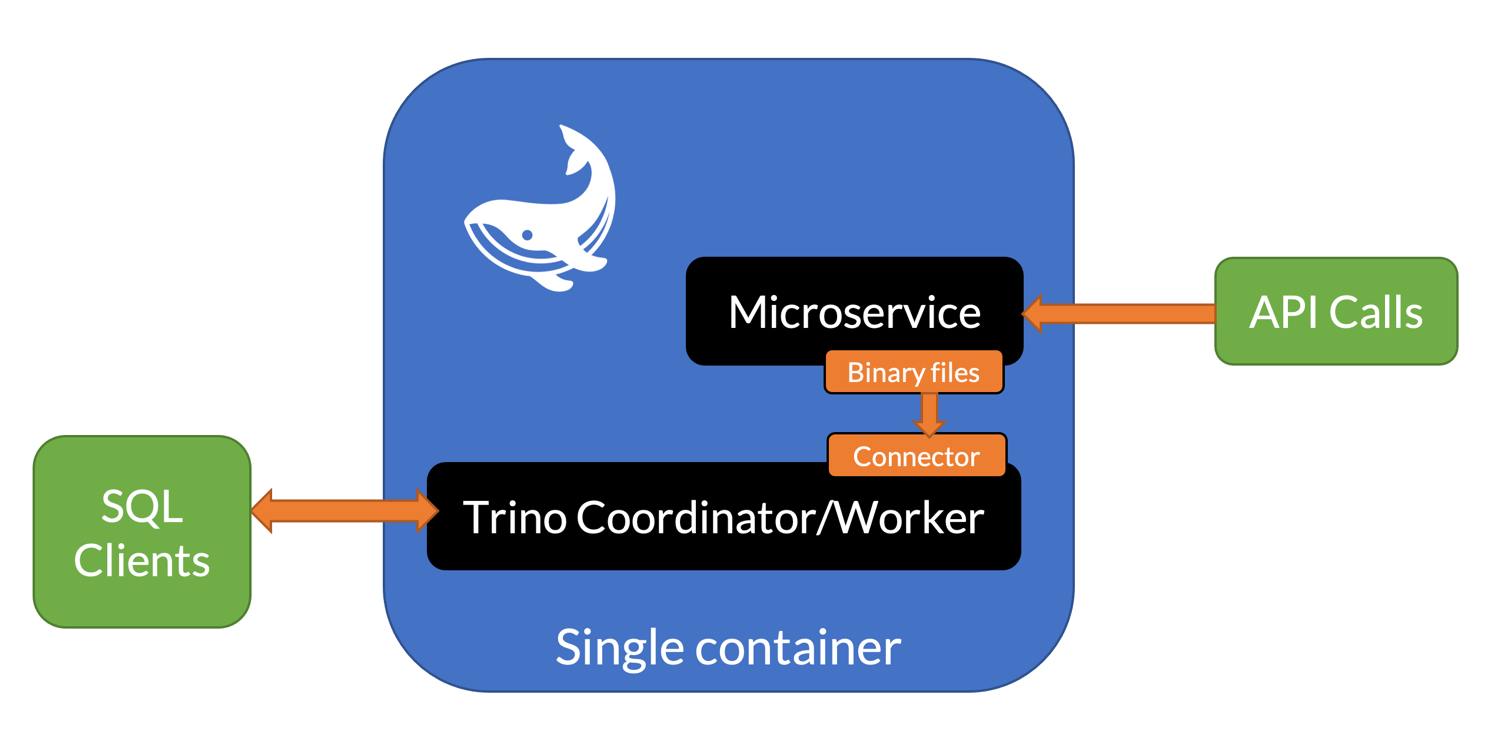
Why not just use Avro?
- Simple requirements – basic versioning, no secondary objects, limited data types
- Zero-allocation reader for fast linear scan – one memcpy per physical column
- Connector can report null/not-null without type conversion
- Connector defers type conversion until getXXX() method
- getSlice() just wraps an existing buffer (zero allocation)
Most of these optimizations were realized by working backwards from the Trino connector API to get the best linear scan performance imaginable.
Combining API calls with other data
Now they can deliver API call data out to all the different kinds of SQL clients out there, and they’re also able to combine API call data with data stored in other databases.
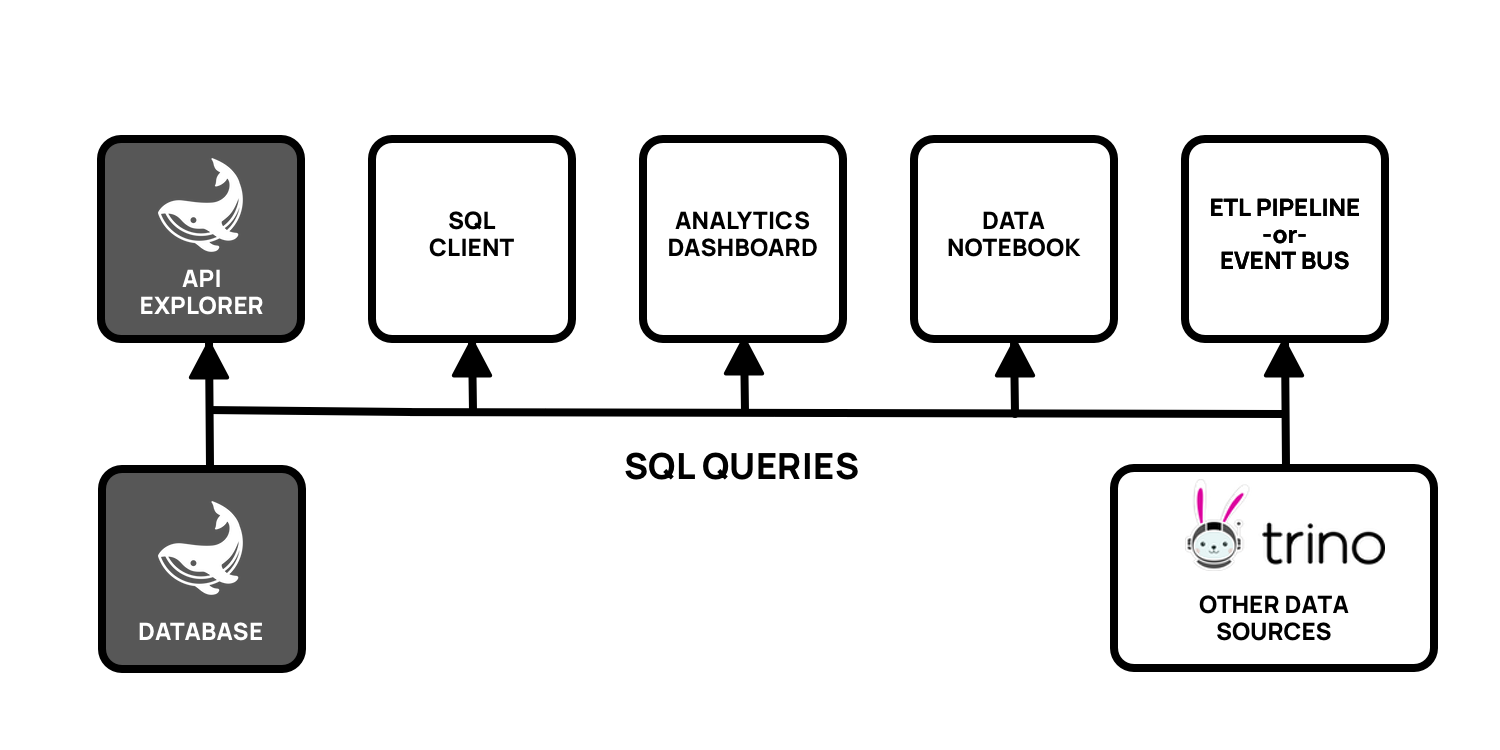
This is really exciting because your Resurface database plays nicely with all your other databases that are bridged together with Trino. That means that actual API traffic can be brought into your customer data mart, or combined with data from any other systems, in real time!
PR of the week: PR 4022 Add Soundex function
A big shoutout to tooptoop4 for their contribution to this weeks PR of the week.
This PR adds the soundex() function,
which is a phonetic function. These functions show up in the WHERE clause of a
query to find words that sound similar. There’s a few examples in the demo
below.
Thanks for this awesome contribution!
Demo: Using the soundex function
SELECT *
FROM (
VALUES
(1, 'Bri'),
(2, 'Bree'),
(3, 'Bryan'),
(4, 'Brian'),
(5, 'Briann'),
(6, 'Brianna'),
(7, 'Briannas'),
(8, 'Bri Jan'),
(9, 'Bri Yan'),
(10, 'Bob')
) names(id, name)
WHERE soundex(name) = soundex('Brian');
# Results:
# |id |name |
# |---|-------|
# |3 |Bryan |
# |4 |Brian |
# |5 |Briann |
# |6 |Brianna|
# |9 |Bri Yan|
SELECT *
FROM (
VALUES
(1, 'Man'),
(2, 'Fred'),
(3, 'Manfred'),
(4, 'Can fed'),
(5, 'Tan bed'),
(6, 'Man Fred'),
(7, 'Man dread'),
(8, 'Bob')
) names(id, name)
WHERE soundex(name) = soundex('Manfred');
# Results:
# |id |name |
# |---|--------|
# |3 |Manfred |
# |6 |Man Fred|
SELECT *
FROM (
VALUES
(1, 'Martin'),
(2, 'Mar teen'),
(3, 'Mar tin'),
(4, 'Marteen'),
(5, 'Mart in')
) names(id, name)
WHERE soundex(name) = soundex('Martin');
# Results:
# |id |name |
# |---|--------|
# |1 |Martin |
# |2 |Mar teen|
# |3 |Mar tin |
# |4 |Marteen |
# |5 |Mart in |
SELECT *
FROM (
VALUES
(1, 'Robert'),
(2, 'Rob'),
(3, 'Bob'),
(4, 'Bobert'),
(5, 'Bobby')
) names(id, name)
WHERE soundex(name) = soundex('Rob');
# Results:
# |id |name|
# |---|----|
# |2 |Rob |
SELECT *
FROM (
VALUES
(1, 'Christ'),
(2, 'Christeen'),
(3, 'Christian'),
(4, 'Christine'),
(5, 'Chris'),
(6, 'Kristine')
) names(id, name)
WHERE soundex(name) = soundex('Christine');
# Results:
# |id |name |
# |---|---------|
# |1 |Christ |
# |2 |Christeen|
# |3 |Christian|
# |4 |Christine|
# What the results actually return
SELECT name, soundex(name)
FROM (
VALUES
(1, 'Christ'),
(2, 'Christeen'),
(3, 'Christian'),
(4, 'Christine'),
(5, 'Chris'),
(6, 'Kristine'),
(6, 'Christine')
) names(id, name);
# Results:
# |name |_col1|
# |---------|-----|
# |Christ |C623 |
# |Christeen|C623 |
# |Christian|C623 |
# |Christine|C623 |
# |Chris |C620 |
# |Kristine |K623 |
Question of the week: How to export query results into a file (e.g. CTAS, but into a single file)?
This is possible using the Trino CLI’s
--execute option in conjunction with the redirect operator (>). You may also
use other options, such as, --output-format to specify the format of the data
going to the file (e.g. if you want a csv, tsv, json, headers, etc…)
Output format for batch mode [ALIGNED, VERTICAL, TSV, TSV_HEADER, CSV, CSV_HEADER, CSV_UNQUOTED, CSV_HEADER_UNQUOTED, JSON, NULL] (default: CSV)
Here is an example of the command you would run using the cli executable trino.
trino --execute "select * from tpch.sf1.customer limit 5" \
--server http://localhost:8080 \
--output-format CSV_HEADER > customer.csv
If you’re running Trino in Docker, here is an example command to run this in a temporary Trino container.
docker run --rm -ti \
--network=trino-hdfs3_trino-network \
--name export-trino-data \
trinodb/trino:latest \
trino --execute "select * from tpch.sf1.customer limit 5" \
--server http://trino-coordinator:8080 \
--output-format CSV_HEADER > customer.csv
If you have a very complex query that takes up multiple lines, or you don’t
want to spend half of your day escaping quotations, you can put your SQL into a
file and reference the query using the -f or --file options. The query
above could be represented as this query:
trino --file query.sql \
--server http://localhost:8080 \
--output-format CSV_HEADER > customer.csv
This query along with the following query.sql file produces an equivalent query:
select *
from tpch.sf1.customer
limit 5;
Finally, one last trick is to stage the data using the memory connector to stage the data and finally export it. The Trino Definitive Guide has example for adding Iris data set into memory connector storage with CLI.
Events, news, and various links
- Apache Iceberg: A table format for data lakes with unforeseen use cases
- Americas meetup
- May 26th, 2021 @ 5:30p EDT
- Link: https://www.meetup.com/trino-americas/events/278103777/
- Trino Summit
- Hybrid event
- September 15th, 2021
- Link: http://starburst.io/trinosummit2021
Blogs
- https://resurface.io/blog/why-we-love-trino
- https://resurface.io/blog/what-is-api-observability
- https://resurface.io/blog/forking-open-source
Trino Meetup groups
- Virtual
- East Coast (US)
- West Coast (US)
- Mid West (US)
Latest training from David, Dain, and Martin(Now with timestamps!):
If you want to learn more about Trino, check out the definitive guide from OReilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.