Video
- Concept of the week: Trino Views, Hive Views and Materialized Views (297s)
- PR of the week: PR 4832 Add Iceberg support for materialized views (3544s)
- Demo: Showing the different views in Trino (3685s)
- Question of the week: Are JDBC drivers backwards compatible with older Trino versions? (4862s)
Audio

Commander Bun Bun enjoying the views...
Guests
- Anjali Norwood, Senior Open Source Software Engineer at Netflix (@AnjaliNorwood)
Concept of the week: Trino Views, Hive Views and Materialized Views
Before diving into views, it can be helpful to take a step back to consider a
well understood abstraction, like tables, to understand the purpose of a view.
Tables contain data in a vertical orientation, referred to as columns. Databases
represent instances of the data in a horizontal orientation, referred to as rows.
See the following tables, customer and orders tables from the TPCH dataset.
customer table
| custkey | name | nationkey | acctbal | mktsegment |
|---|---|---|---|---|
| 376 | Customer#000000376 | 16 | 4231.45 | AUTOMOBILE |
| 377 | Customer#000000377 | 23 | 1043.72 | MACHINERY |
| 378 | Customer#000000378 | 22 | 5718.05 | BUILDING |
orders table
| orderkey | custkey | orderstatus | totalprice | orderdate | orderpriority |
|---|---|---|---|---|---|
| 1 | 376 | O | 172799.49 | 1996-01-02 | 5-LOW |
| 2 | 376 | O | 38426.09 | 1996-12-01 | 1-URGENT |
| 3 | 377 | F | 205654.3 | 1993-10-14 | 5-LOW |
The columns have a schema that enforce particular data types in particular
columns and prevents insertion of invalid data into the table by throwing
an exception. This becomes extremely useful when reading and processing the data
as there are a clear set of operations that can run on certain columns ased on
their type. This information is also useful when deserializing result sets into
various in-memory abstractions. Here is an example of the customer table
schema:
customer table schema
CREATE TABLE customer (
custkey bigint,
name varchar(25),
address varchar(40),
nationkey bigint,
phone varchar(15),
acctbal double,
mktsegment varchar(10),
comment varchar(117)
)
Views and materialized views:
The structure of a view is similar to tables in that they have columns, rows,
and schemas similar to regular database tables. What then do views offer over
tables? Views offer ways to encapsulate complex SQL statements. For example,
take this SQL query that would run over the customer and orders tables
defined before.
SELECT
c.custkey,
name,
nationkey,
mktsegment,
sumtotalprice,
openstatuscount,
failedstatuscount,
partialstatuscount
FROM
customer c
JOIN (
SELECT
custkey,
SUM(totalprice) AS sumtotalprice,
COUNT_IF(orderstatus = 'O') AS openstatuscount,
COUNT_IF(orderstatus = 'F') AS failedstatuscount,
COUNT_IF(orderstatus = 'P') AS partialstatuscount
FROM orders
GROUP BY custkey
) o
ON c.custkey = o.custkey;
This query performs some aggregations on the orders table grouped by customer.
Then there is a join performed on the aggregated orders table and customer table
by custkey.
| custkey | name | nationkey | mktsegment | sumtotalprice | openstatuscount | failedstatuscount | partialstatuscount |
|---|---|---|---|---|---|---|---|
| 376 | Customer#000000376 | 16 | AUTOMOBILE | 1600696.4700000002 | 3 | 6 | 1 |
| 377 | Customer#000000377 | 23 | MACHINERY | 803271.9400000001 | 3 | 6 | 0 |
| 379 | Customer#000000379 | 7 | AUTOMOBILE | 3155009.54 | 7 | 11 | 0 |
From here, there are many ways you could further evaluate the resulting data.
You could filter and look at which market segment is spending the most on your
products. You could also look at where there are the most failed orders by the
nation column to evaluate where shipping lines may need to be improved. The
table above which results from the example query, is a good intermediate state
of the data that can be reused for many future evaluations. Instead of defining
a new table, you can create a view on this data that encapsulates the complex
SQL that was used to calculate it. This is done using the CREATE VIEW
statement.
CREATE VIEW customer_orders_view AS
<complex SQL query above>
Now, when you want to run any further analysis on this intermediate dataset, you simply refer to the view instead of having to rewrite the statement before. As mentioned, this view also has a schema and is treated much like a table when the query engine does its planning. In this way it is also easier to map the data to the application logic by enabling different shapes of the same data. It should be made clear that these views are read-only and do not allow inserts, updates, or deleting from the view.
Another reason why you would want to create a view is to control read access to the data. When running the query, you get to choose which columns and rows get filtered out and that return from when users query the view. The authorization of a user is tied to the view and its content, and that can significantly differ from the complete data in the underlying tables. For example, the views can exclude sensitive data like social security numbers, birth dates, credit card numbers, and many other facts.
When creating a view, there are two modes that the view can run in that will
indicate the user that will run the queries defined in the view during query
runtime. You can either run this query as the DEFINER which indicates to run
the view query as the user that created the view, or as the INVOKER, which
indicates to run the view query as the user that is running the outer query of
the view. The default mode is DEFINER. See more
in the security section of the create view documentation.
There are two types of views; materialized and logical views. The view defined above is the standard logical view that gets expanded into its definition. Logical views do not provide any performance benefit since the data is not stored and instead queried at query time. Materialized views persist the view data upon view creation by storing the query data.
Materialized views make overall queries much faster to run as part of the query
has already been computed. One issue with materialized views is that the data
may become outdated and out of sync with the underlying table data. To keep the
data between the tables and materialized view in sync, you have to refresh the
view. A special refresh command REFRESH MATERIALIZED VIEW is called
periodically to handle this operation, or to schedule the procedure run
automatically.
Trino views: So many views, so little time
Views handling in Trino depends on the connector. In general, most connectors expose views to Trino as if they are another set of tables available for Trino to query. The main exceptions for this is the Hive and Iceberg connectors. The table below lists the current possible Hive and Iceberg views.
| Logical | Materialized | ||
|---|---|---|---|
| Trino Created View | Hive Connector | ✅ | ❌ |
| Iceberg Connector | ✅ (Edit: PR 8540) | ✅ | |
| Hive Created View | ✅ (read-only) | ✅ (read-only) | |
You’ll notice that the materialized views cannot be created through the Hive connector in Trino. You will get the following exception:
Caused by: java.sql.SQLException: Query failed (#...):
This connector does not support creating materialized views.
Also, you cannot create logical views in Iceberg and you will get the following exception:
Caused by: java.sql.SQLException: Query failed (#...):
This connector does not support creating views.
Trino reads Hive views
Before Trino there was Hive. Trino is a replacement for the Hive runtime for many users, and it is very useful for these users to also be able to read data from Hive views in Trino. Trino always aims to be compatible with as many Hive abstractions as possible to make migrating away from Hive to Trino as painless as possible. So Trino supports reading data from Hive Views, though it doesn’t support updates on these views. You have to update these views through Hive and ideally you will gradually migrate these views to Trino over time. Trino also supports reading Hive materialized views, though Trino reads these views as another Hive table rather since they are stored similarly to standard Hive tables. Since Hive views are defined in HiveQL, the view definitions need to be translated to Trino SQL syntax. This is done using LinkedIn’s Coral library.
Coral: the unifier of the bee and the bunny
Coral is a project that allows for translation between views from different SQL syntax. It can process Hive QL statements and convert them to an internal representation using Apache Calcite. It then converts the internal representation to Trino SQL.
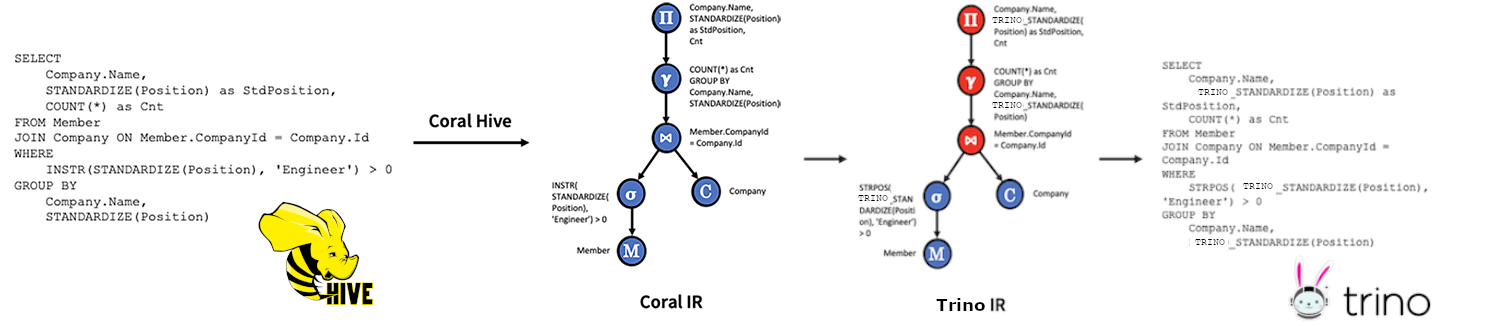
Trino reading Hive view sequence diagrams
In both of these sequence diagrams, notice that the first actions are to create a Hive view. This is created and maintained by the Hive system and it is impossible to create or update a similar view in Trino.
This diagram shows the creation of a Hive view, then shows the sequence of events when Trino reads that view.
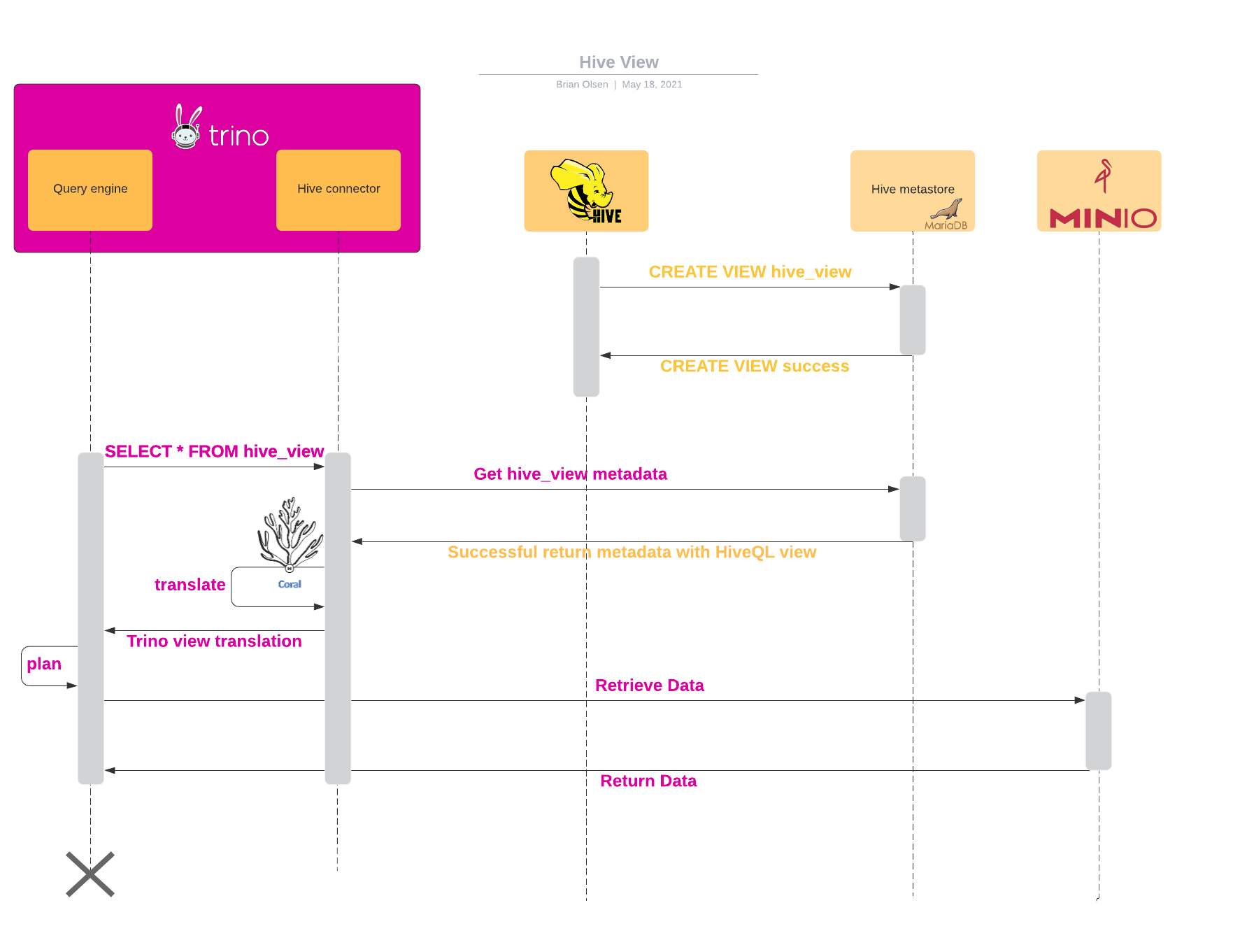
This diagram shows the creation of a Hive materialized view, then shows the sequence of events when Trino reads the materialized view.
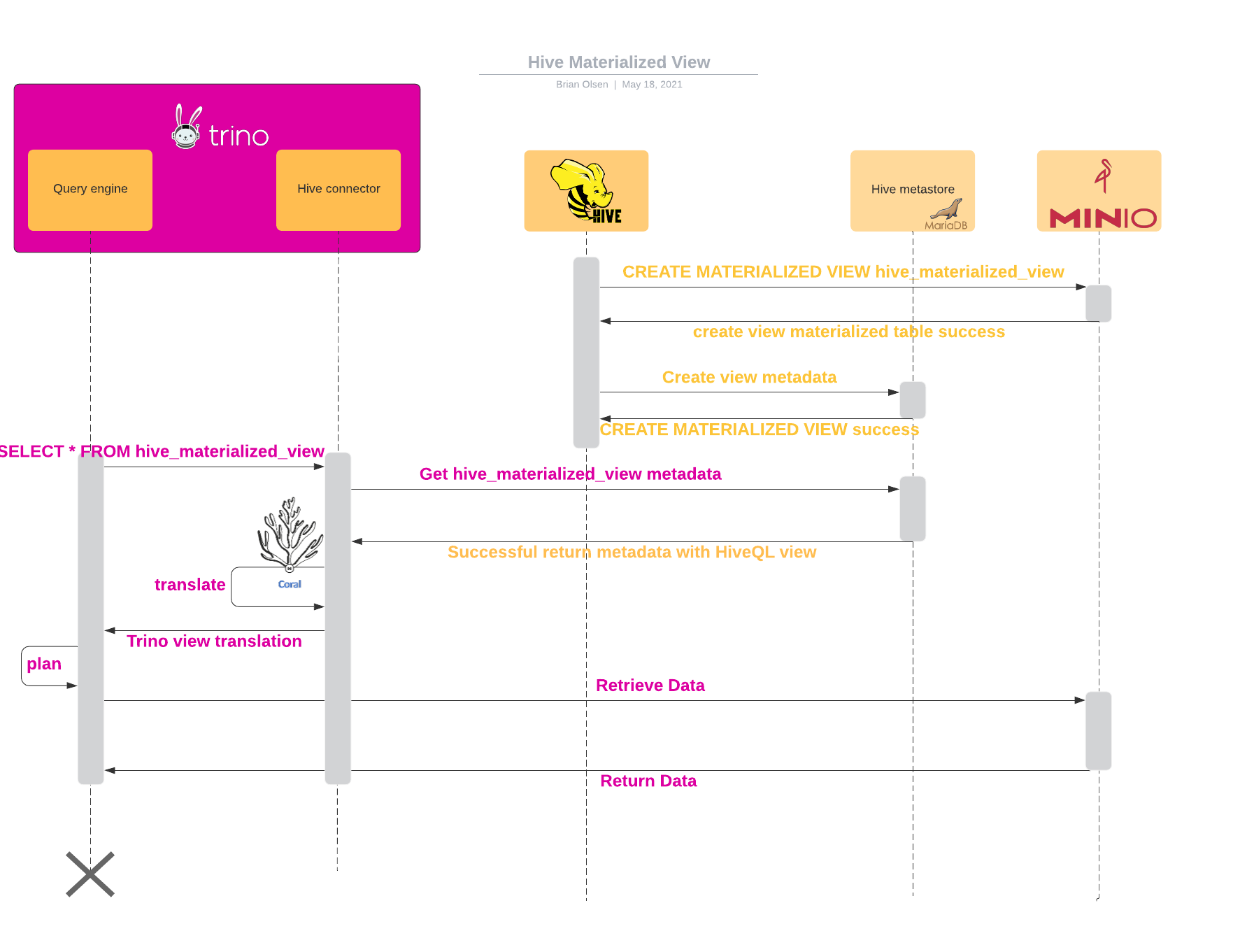
Trino native view sequence diagrams
This diagram shows the sequence diagram for a Trino view that is created using the Hive Connector.
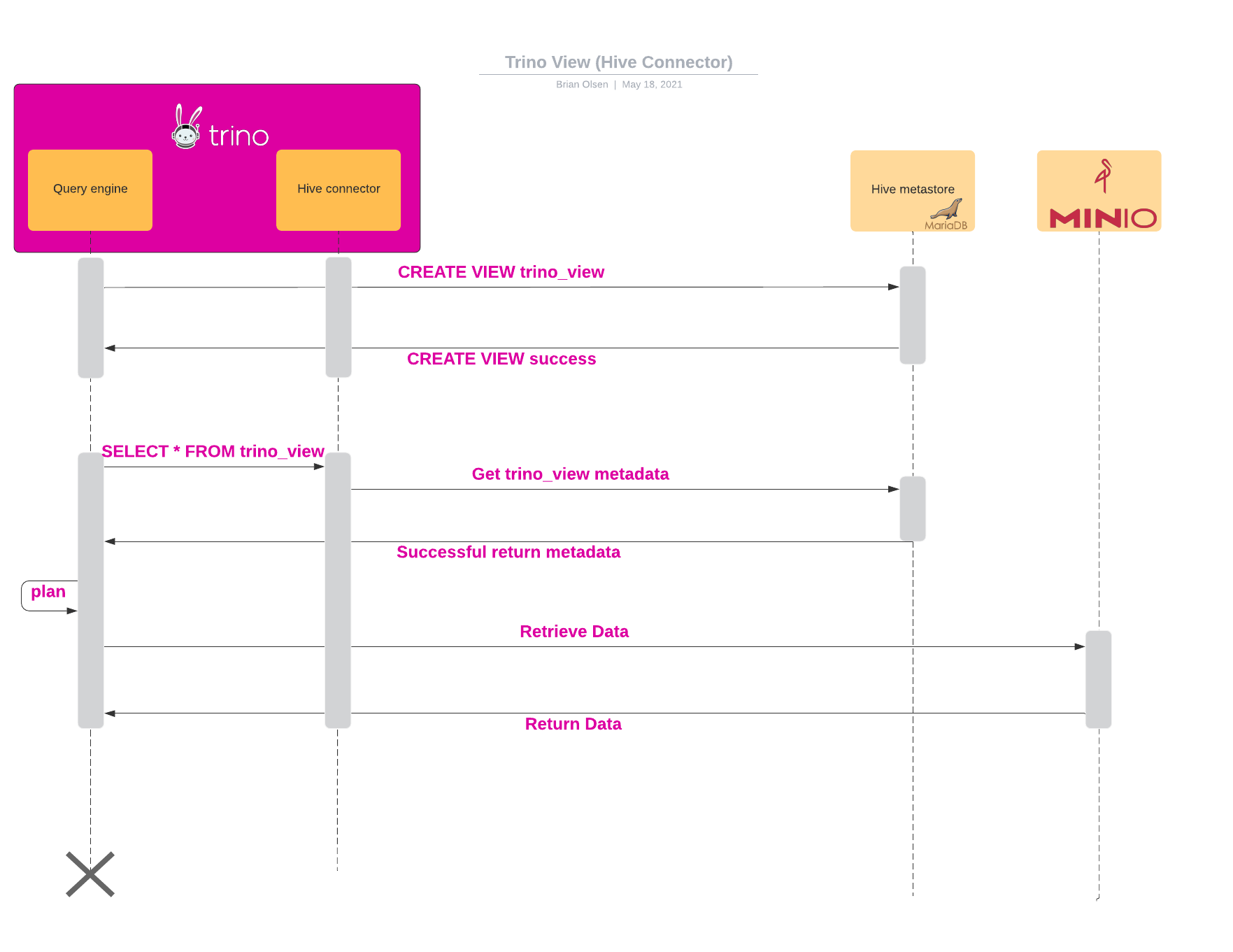
This diagram shows the sequence diagram for a materialized Trino view that is created using the Iceberg Connector.
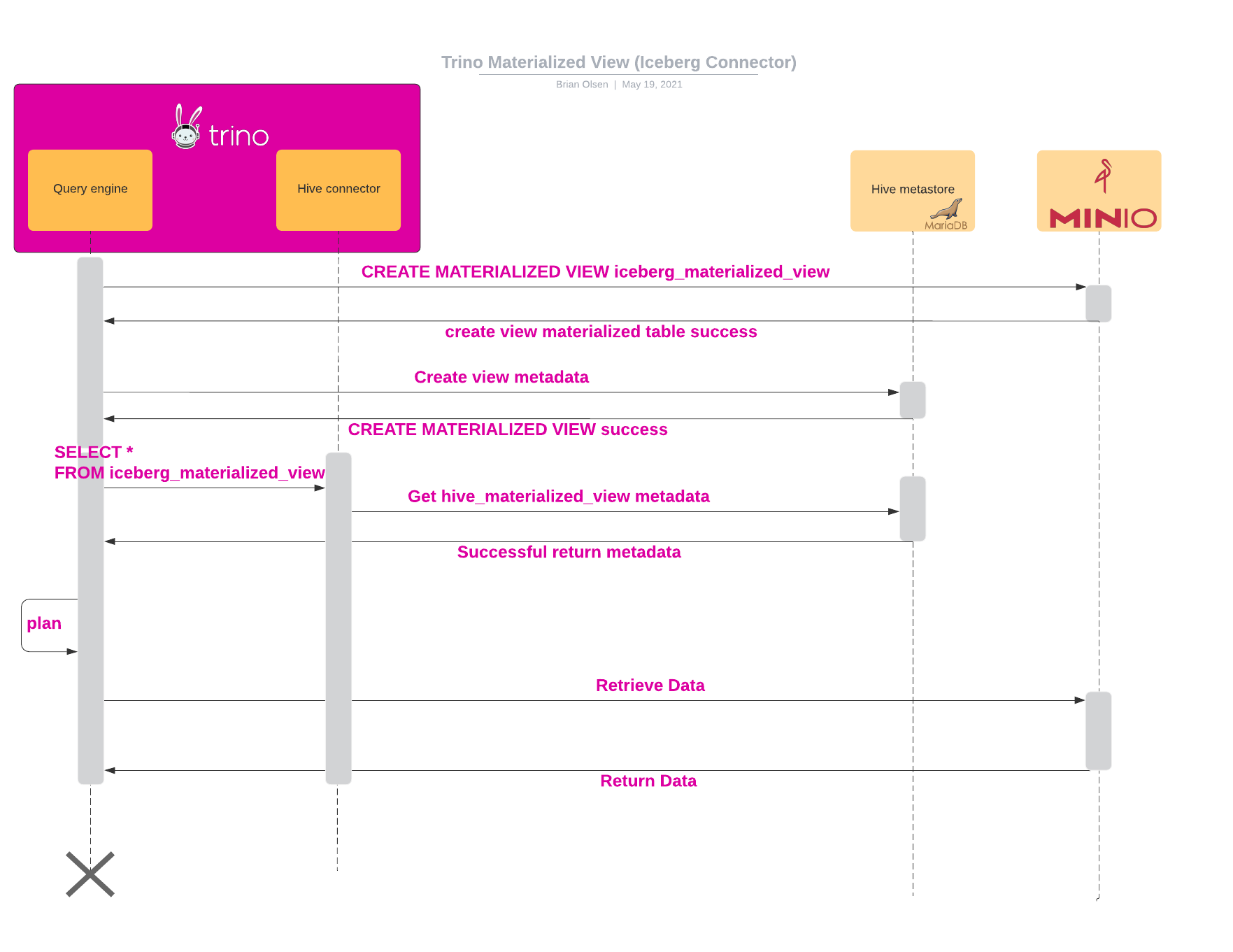
Iceberg materialized view refresh (currently only full refresh in Iceberg connector)
Ideally, as the tables underlying a materialized view change, the materialized view should be automatically and incrementally updated to reflect the results that are in sync with latest data.
Automatically keeping materialized views fresh can be tricky from resource
management point of view since the computation to materialize the materialized
view can be expensive. Trino currently does not support automatic refresh of
materialized views. It instead supports the REFRESH MATERIALIZED VIEW command
that the user can issue to ensure that the materialized view is fresh.
As a part of executing REFRESH MATERIALIZED VIEW command in Trino, existing
data in the materialized view is dropped and new data is inserted if there are
any changes to base data. If the base data has not changed at all, the
REFRESH MATERIALIZED VIEW command is a no-op.
What happens if the user issues a query against the materialized view, and the materialized view is not fresh? Trino detects that the materialized view is stale, so it expands the materialized view definition, much like a logical view and executes that SQL statement. Trino runs the query against the base tables.
Incremental or delta refresh of materialized views is a more efficient way of
keeping the materialized view in sync with the base data. An incremental refresh
means only parts of the data that need to be updated in a materialized view are
updated The rest of the data is left untouched. For example, say you have a base
table, sales, partitioned on date column. The sales table only gets
inserted data for that day. If the materialized view is also partitioned on
date, a new partition for a day can be added and data inserted for that day.
Data for previous days/months is still fresh and can be left untouched.
This is something on Netflix’s roadmap. The incremental refresh of the
materialized view can be a partition level refresh, another can be a more
granular row-level refresh by using functionality similar to SQL MERGE
statement.
Support in Trino and at Netflix:
Netflix materialized views
The main reason Netflix is interested in materialized views is to give analysts an easy way to compute and materialize their frequently used queries and keep the results refreshed without relying on ETL pipeline to create and maintain those result sets. Some materialized views are as simple as queries that project columns and apply filters, selecting data for a time range or for a test-id. Others are more complex that perform multi-level joins and aggregations.
Netflix materialized view cross compatibility extension
Materialized views, much like logical views, are compatible across Trino and Spark, the two main engines used at Netflix. Spark is used at Netflix to do ETL, and creating and populating tables. Trino is the most popular engine with analysts and developers for adhoc and experimental queries as well as audits.
Trino is also used for CREATE TABLE AS SELECT (CTAS) in some use cases. Both
the engines access data from tables using Iceberg and Hive connectors where data
is stored in S3. Netflix built upon the Trino logical views to create common
views that are accessible from both Spark and Trino. The difference between the
Trino logical views and Netflix common views is that the metadata is stored in
the Hive metastore for Trino logical views, while common views store their
metadata in JSON format in S3.
A view object in Hive metastore points to the S3 location of metadata. It tracks evolution of view definition in the form of versions so that you can potentially revert a view to its older version. Main benefit of common views is interoperability between Spark and Trino (can create, replace, query, drop from either engine and can be expanded to other engines). Netflix supports common views through both Hive and Iceberg connectors.
Currently, common views support SQL syntax common to both Spark and Trino. This support can be expanded in future using LinkedIn’s Coral project such that engine specific syntax and semantics can be translated and interpreted by another engine. Netflix materialized views are an extension of Trino materialized views to make them inter-operable between Spark and Trino. The only difference between Trino and Netflix materialized views is where the metadata is stored, very similar to Trino and Netflix logical views.
Roadmap:
- Netflix is looking into caching query results using materialized views and memory connector.
- Incremental refresh ideas.
PR of the week: PR 4832 Add Iceberg support for materialized views
Our guest, Anjali, is the author of this weeks PR of the week, which adds Iceberg support for materialized views. Thanks Anjali!
Honorable PR mentions:
In order for the PR of the week to work, Anjali
added syntax support for Trino
materialized views with commands: CREATE MATERIALIZED VIEW,
REFRESH MATERIALIZED VIEW, and DROP MATERIALIZED VIEW.
Before any of this was done, user laurachenyu integrated Coral with trino to enable querying hive views.
Demo: Showing the different views in Trino
In Trino, create some Hive tables in a hive catalog named hdfs that represents
the underlying storage Trino writes to.
CREATE SCHEMA hdfs.tiny
WITH (location = '/tiny/');
CREATE TABLE hdfs.tiny.customer
WITH (
format = 'ORC',
external_location = '/tiny/customer/'
)
AS SELECT * FROM tpch.tiny.customer;
CREATE TABLE hdfs.tiny.orders
WITH (
format = 'ORC',
external_location = '/tiny/orders/'
)
AS SELECT * FROM tpch.tiny.orders;
Now, create a logical Hive view (hive_view), and a materialized Hive view
(hive_materialized_view) from the Hive CLI.
USE tiny;
CREATE VIEW hive_view AS
SELECT c.custkey, c.name, nationkey, mktsegment, orderstatus, totalprice, orderpriority, orderdate
FROM customer c JOIN orders o ON c.custkey = o.custkey;
CREATE MATERIALIZED VIEW hive_materialized_view AS
SELECT c.custkey, c.name, nationkey, mktsegment, orderstatus, totalprice, orderpriority, orderdate
FROM customer c JOIN orders o ON c.custkey = o.custkey;
As you create the views, you should check the state in the hive metastore.
SELECT t.TBL_NAME, t.TBL_TYPE, t.VIEW_EXPANDED_TEXT, t.VIEW_ORIGINAL_TEXT
FROM DBS d
JOIN TBLS t ON d.DB_ID = t.DB_ID
WHERE d.NAME = 'tiny';
Once the Hive views exist, you can then query them from Trino.
CREATE VIEW hdfs.tiny.trino_view AS
SELECT c.custkey, c.name, nationkey, mktsegment, orderstatus, totalprice, orderpriority, orderdate
FROM hdfs.tiny.customer c JOIN hdfs.tiny.orders o ON c.custkey = o.custkey;
/* Fails: Caused by: java.sql.SQLException: Query failed (#20210516_032433_00002_6syuw):
This connector does not support creating materialized views */
CREATE MATERIALIZED VIEW hdfs.tiny.trino_materialized_view AS
SELECT c.custkey, c.name, nationkey, mktsegment, orderstatus, totalprice, orderpriority, orderdate
FROM hdfs.tiny.customer c JOIN hdfs.tiny.orders o ON c.custkey = o.custkey;
/* Fails: Caused by: java.sql.SQLException: Query failed (#20210516_101856_00009_ihjur):
This connector does not support creating views */
CREATE VIEW iceberg.tiny.iceberg_view AS
SELECT c.custkey, c.name, nationkey, mktsegment, orderstatus, totalprice, orderpriority, orderdate
FROM hdfs.tiny.customer c JOIN hdfs.tiny.orders o ON c.custkey = o.custkey;
CREATE MATERIALIZED VIEW iceberg.tiny.iceberg_materialized_view AS
SELECT c.custkey, c.name, nationkey, mktsegment, orderstatus, totalprice, orderpriority, orderdate
FROM hdfs.tiny.customer c JOIN hdfs.tiny.orders o ON c.custkey = o.custkey;
/*
This REFRESH call failed during the show due to the fact that I created the
materialized Trino view in the Iceberg (`iceberg`) catalog using tables from the
Hive(`hdfs`) catalog. I should have created the materialized view using the
iceberg catalog:
CREATE MATERIALIZED VIEW iceberg.tiny.iceberg_materialized_view AS
SELECT c.custkey, c.name, nationkey, mktsegment, orderstatus, totalprice, orderpriority, orderdate
FROM iceberg.tiny.customer c JOIN iceberg.tiny.orders o ON c.custkey = o.custkey;
*/
REFRESH MATERIALIZED VIEW iceberg.tiny.iceberg_materialized_view;
/* query tables */
SELECT * FROM hdfs.tiny.customer LIMIT 3;
SELECT * FROM hdfs.tiny.orders LIMIT 3;
/* query views */
SELECT * FROM hdfs.tiny.trino_view LIMIT 3;
SELECT * FROM hdfs.tiny.hive_view LIMIT 3;
SELECT * FROM hdfs.tiny.hive_materialized_view LIMIT 3;
SELECT * FROM iceberg.tiny.iceberg_materialized_view LIMIT 3;
Question of the week: Are JDBC drivers backwards compatible with older Trino versions?
Full question: Are JDBC drivers backwards compatible with older Trino versions? I’m trying to install the 354 driver on a multi-tenanted Tableau server where there might be older Trino versions in play. Do I need to upgrade my Trino clients right away when upgrading my server to Trino version from <=350 to >350?
For this particular users case, the answer is that they won’t need to upgrade their clients assuming they are on Trino servers. If their server versions are PrestoSQL version <= 350 then they will need to hold off on upgrading to a Trino client.
Trino’s JDBC drivers typically maintain compatibility with older server versions (and vice versa). However, the project was renamed from PrestoSQL to Trino starting version 351, and as a consequence, JDBC drivers with version >= 351 are not compatible with servers with version <= 350. More details at: https://trino.io/blog/2021/01/04/migrating-from-prestosql-to-trino.html.
In short, you can have a PrestoSQL client with a Trino server, but you can’t have a Trino client with an PrestoSQL server.
Events, news, and various links
Events
- Join for an awesome event on May 26th as Iceberg Creator, Ryan Blue, dives into some interesting and less conventional use cases of Apache Iceberg. Trino Americas meetup
Blogs
Videos
Trino Meetup groups
- Virtual
- East Coast (US)
- West Coast (US)
- Mid West (US)
Latest training from David, Dain, and Martin(Now with timestamps!):
If you want to learn more about Trino, check out the definitive guide from OReilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.