Video
- Question of the week: Can dbt connect to different databases in the same project? (1098s)
- Concept of the week: Trino + dbt = a match made in SQL heaven? (1288s)
- Demo: Querying Trino from a dbt project (2841s)
- PR of the week: PR 8283 Externalised destination table cache expiry duration for BigQuery Connector (4873s)
Audio
Guests
- Amy Chen, Partner Solutions Architect at dbt Labs (formerly Fishtown Analytics) (@yuanamychen)
- Victor Coustenoble, Solutions Architect at Starburst (@victorcouste)
Release 359
Martin:
- Row pattern recognition for window functions
- Support for
SET TIME ZONE - Support for
timestamp(n)with precision higher than 3 in MySQL - ARM64-compatible docker image
- Support for granting
UPDATEprivilege
Manfred:
SET TIME ZONEis a feature from our guest Marius from last time!- ARM64 compatible docker image as well as already existing tar.gz and rpm means usage of Graviton and other ARM64 processors is now available also for Kubernetes users, there are significant cost/performance benefits, try it out
- wow .. this time it took a whole month from 358 to 359
- breaking change - need Java 11.0.11
- more materialized view stuff, and I am working on docs!
- Fix handling of multiple LDAP user bind patterns - for those of us in larger orgs..
- network logging in CLI
- rename
connector.namefromhive-hadoop2tohive
More info at https://trino.io/docs/current/release/release-359.html.
Question of the week: Can dbt connect to different databases in the same project?
This week we are going a little out of order from our usual sequence on this show. The question really gets to the heart of the concept of the week. We’ll cover this first then jump into the concept.
This question was asked on StackOverflow:
It seems dbt only works for a single database. If my data is in a different database, will that still work? For example, if my datalake is using delta, but I want to run dbt using Redshift, would dbt still work for this case?
Our guest Victor replied:
You can use Trino with dbt to connect to multiple databases in the same project.
The GitHub example project https://github.com/victorcouste/trino-dbt-demo contains a fully working setup, that you can replicate and adapt to your needs.
Concept of the week:
What is dbt?
dbt is a transformation workflow tool that lets teams quickly and collaboratively deploy analytics code, following software engineering best practices like modularity, CI/CD, testing, and documentation. It enables anyone who knows SQL to build production-grade data pipelines.
When referring to dbt, it can mean two slightly different things. dbt core is the open source framework that provides the SQL compiler and framework to manage your SQL workflow. You can interact with it via a command line interface. In addition, dbtlabs offers the fully managed SaaS product dbt Cloud. You can use it to handle all of your dbt projects from development to deployment in a single browser based tool. It provides useful features like a full IDE to develop and test code, orchestration, logging, and alerting. At the moment, dbt Cloud is not available for Trino users.
The framework allows you to check the quality of results, document the lineage, manage the changes/versions in the SQL scripts and orchestrate the queries, like a CI/CD framework but for your data. dbt is not an extract and load tool. The focus is on transforming what is already in your data warehouse/data lake.
Check out these links to learn more:
Goals of dbt and how that differs from Trino
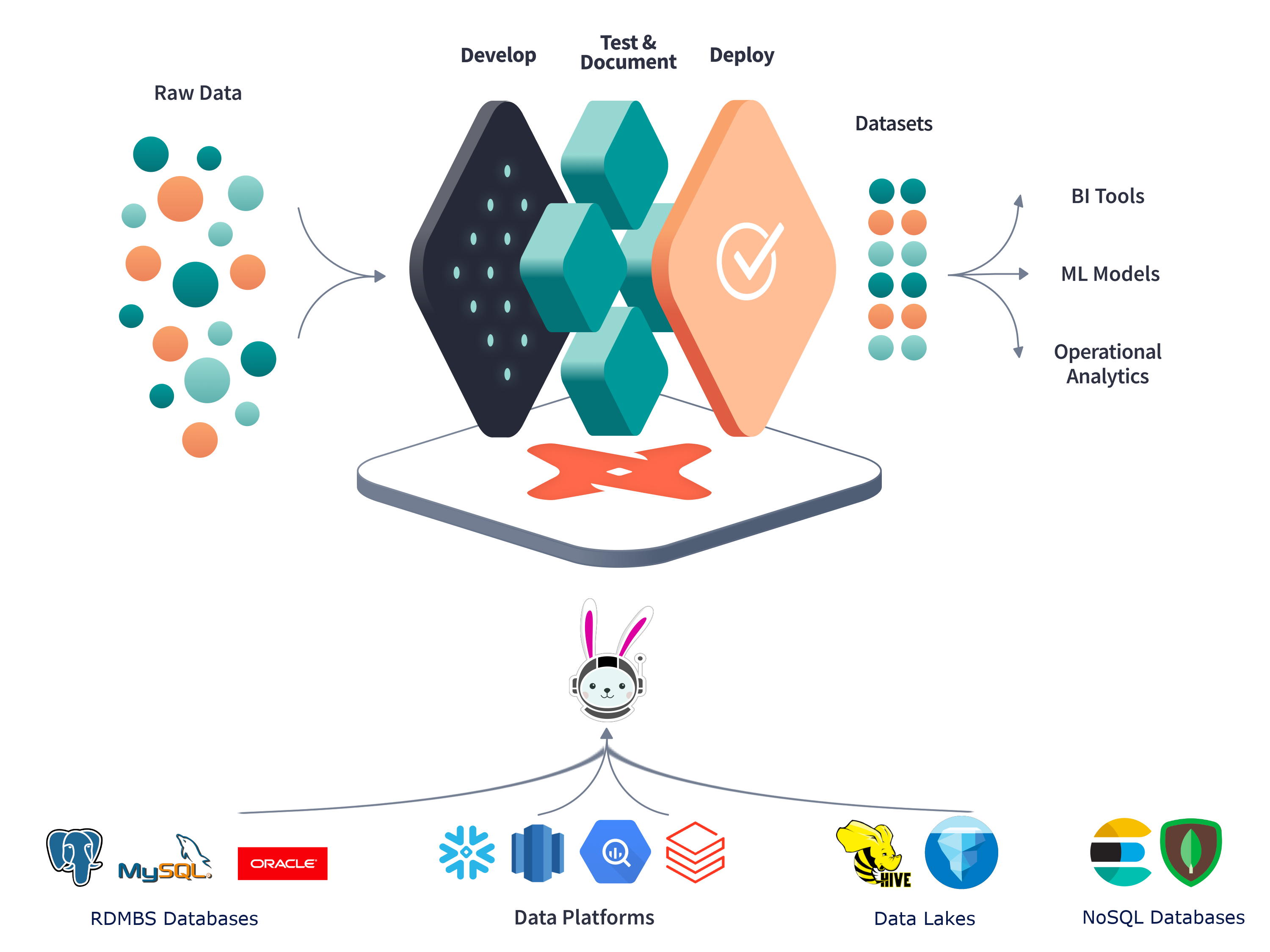
Trino is the execution SQL engine and dbt is the framework to manage your SQL statements. dbt won’t execute the SQL itself, rather it pushes all of the compute down to the SQL engine. This SQL engine can be Trino, or an engine included in the data source like the database itself. Using Trino as the SQL execution engine allows you to use the same SQL dialect for all connected data sources. This includes data sources that natively do not support SQL like object storage systems, Kafka, Elasticsearch, and many others.
Transformation vs ad-hoc joins
Transformations done by dbt are in general used to clean and prepare data for analytics purposes. It’s often used to go from the raw data to a ready-to-use data for reporting and analysis. dbt creates database objects like tables or views to be consumed by business users and analytics tools.
On the other hand, even if Trino can also execute SQL to create tables and views, these SQL queries are not managed but just executed. Trino doesn’t have, like dbt, all the framework to version, audit, document and orchestrate SQL script and execution. Trino is more used to execute SQL SELECT statements generated by users or BI tools to analyze data in an interactive way.
Cases for why you need both
Trino and dbt are complementary when you need to access different sources from a single SQL query or when you need to run SQL query with good performance on object storage systems like S3, GCS, ADLS, or HDFS.
It’s where Trino can complement dbt, as dbt can only access a single data warehouse connection in a SQL query. In dbt there is no way to query multiple storage systems at the same time.
Trino is recognized for great performance with object storage/data lake processing. With dbt it can transform and prepare data at scale. Trino also allows you to run dbt on a traditional, on-premise data warehouse where normally dbt only runs on a modern cloud data warehouse like Snowflake, BigQuery, or Redshift.
dbt basics
dbtlabs offers a good tutorial which covers the fundamental topics of dbt for you to learn:
- Project: A directory of SQL and YAML files defined with a single project file.
- Models: A model is a single SQL file where you define your transformations to create a table or a view.
- Profile: To define connections to your data sources.
Then you have other resources like seeds, macros, tests, sources, snapshots.
Demo: Querying Trino from a dbt project
Victor shows us a demo from his blog post that inspired this episode.
If you looked at the code, you may have noticed that the code used an adapter
called db-presto-trino. This adapter derives from the outdated presto naming and is
still there for interaction with legacy Presto clusters. Although it can work
it uses an outdated python client to interact with Trino and there is an open
issue to create an official dbt-trino adapter
that uses the updated trino-python-client.
If you want to help with this, reach out on the issue itself and join the
#db-presto-trino channel on the dbt Slack.
https://community.getdbt.com/
After the show Marius Grama, started work on dbt-trino in his own repository. Thanks for the quick turnaround Marius!
PR of the week: PR 8283 Externalised destination table cache expiry duration for BigQuery Connector
The PR of the week, was committed by Ayush Bilala(Twitter), (LinkedIn), a Staff Software Engineer at Walmart Global Tech.
This fixes issue 8263 by adding
a new configuration for the Big Query connector, bigquery.views-cache-ttl
to allow configuring the cache expiration for BigQuery views.
Thanks Ayush!
Events, news, and various links
News
- The “frog” book has been translated to Chinese! Keep your eyes peeled for the rebrand into Trino for the translation.
Trino Meetup groups
- Virtual
- East Coast (US)
- West Coast (US)
- Mid West (US)
Latest training from David, Dain, and Martin(Now with timestamps!):
If you want to learn more about Trino, check out the definitive guide from OReilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.