What a great year for the Presto community! We started with the year with the launch of the Presto Software Foundation, with the long term goal of ensuring the project remains collaborative, open and independent from any corporate interest, for years to come.
Since then, the community around Presto has grown and consolidated. We’ve seen contributions from more than 120 people across over 20 companies. Every week, 280 users and developers interact in the project’s Slack channel. We’d like to take the opportunity to thank everyone that contributed the project in one way or another. Presto wouldn’t be what it is without your help.
With the collaboration of companies such as Starburst, Qubole, Varada, Twitter, ARM Treasure Data, Wix, Red Hat, and the Big Things community, we ran several Presto summits across the world:
- Tel Aviv, Israel, April 2019
- San Francisco, USA, June 2019
- Tokyo, Japan, July 2019
- Bangalore, India, September, 2019
- New York, USA, December 2019
All these events were a huge success and brought thousands of Presto users, contributors and other community members together to share their knowledge and experiences.
The project has been more active than ever. We completed 28 releases comprised of more than 2850 commits in over 1500 pull requests. Of course, that alone is not a good measure of progress, so let’s take a closer look at everything that went in. And there is a lot to look at!
Language Features #
-
FETCH FIRST n ROWS [ONLY | WITH TIES]standard syntax. TheWITH TIESclause is particularly useful when some of the rows have the same value for the columns being used to order the results of a query. Consider a case where you want to list top 5 students with highest score on an exam. If the 6th person has the same score as the 5th, you want to know this as well, instead of getting an arbitrary and non-deterministic result:SELECT student_name, score FROM student JOIN exam_result USING (student_id) ORDER BY score FETCH FIRST 5 ROWS WITH TIES OFFSETsyntax, which is especially useful in ad-hoc queries.COMMENT ON <table>syntax to set or remove table comments. Comments can be shown viaDESCRIBEor the newsystem.metadata.table_commentstable.- Support for
LATERALin the context of an outer join. -
Support for
UNNESTin the context ofLEFT JOIN. With this feature, it is now possible to preserve the outer row when the array contains zero elements or isNULL. Most common usages ofUNNESTin aCROSS JOINshould actually be using this form.SELECT * FROM t LEFT JOIN UNNEST(t.a) u (v) ON true IGNORE NULLSclause for window functions. This is useful when combined with functions such aslead,lag,first_value,last_valueandnth_valueif the dataset contains nulls.ROWexpansion using.*operator.CREATE SCHEMAsyntax and support in various connectors (Hive, Iceberg, MySQL, PostgreSQL, Redshift, SQL Server, Phoenix).- Support for correlated subqueries containing
LIMITorORDER BY+LIMIT. -
Subscript operator to access
ROWtype fields by index. This greatly improves usability and readability of queries when dealing withROWtypes containing anonymous fields.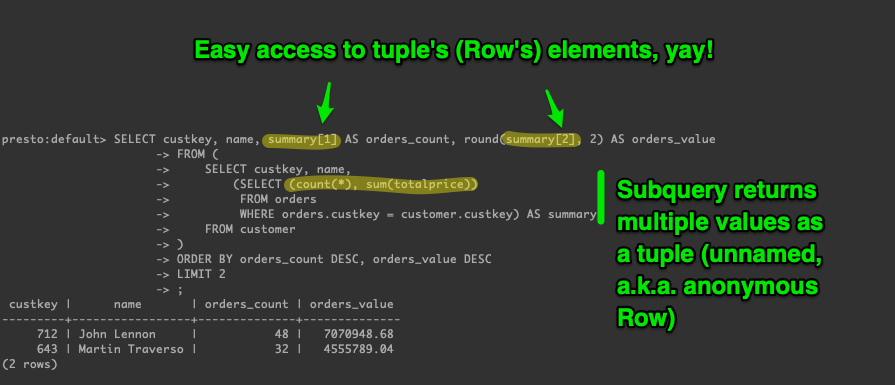
Query Engine #
- Generalize conditional, lazy loading and processing (a.k.a., Late Materialization) beyond Table Scan, Filter and Projection to support Join, Window, TopN and SemiJoin operators. This can dramatically reduce latency, CPU and I/O for highly selective queries. This is one of the most important performance optimizations in recent times and we will be blogging about this more in coming weeks.
- Unwrap cast/predicate pushdown optimizations.
- Connector pushdown during planning for operations such as limit, table sample, or projections. This allows connectors to optimize how data is accessed before it’s provided to the Presto engine for further processing.
- Dynamic filtering.
- Cost-Based Optimizer can now consider estimated query peak memory footprint. This is especially useful for optimizing bigger queries, where not all parts of the query can be run concurrently.
- Improved handling of projections, aggregations and cross joins in cost based optimizer.
- Improved accounting and reporting of physical and network data read or transmitted during query processing.
Performance #
- 10x performance improvement for
UNNEST. - 2-7x improvement in performance of ORC decoders, resulting in a 10% global CPU improvement for the TPC-DS benchmark.
- Improvements when reading small Parquet files, files with large number of columns, or files with small row groups. We found this very useful, for example, when working with data exported from Snowflake.
- Support for new ORC bloom filters.
- Remove redundant
ORDER BYclauses. - Improvements for
INandNOT-INwith subquery expressions (i.e., semijoin). - Huge performance improvements when reading from
information_schema. - Reduce query latency and Hive metastore load, for both
SELECTandINSERTqueries. - Improve metadata handling during planning. This can result in dramatic improvements in latency,
especially for connectors such as MySQL, PostgreSQL, Redshift, SQL Server, etc. Some queries like
SHOW SCHEMASorSHOW TABLESthat could take several minutes to complete now finish in a few seconds. - Improved stability, performance, and security when spilling is enabled.
Functions #
combinationsformatUUIDtype and related functions.all_match,any_matchandnone_match.- Support flexible aggregation with lambda expressions using
reduce_agg. - New date and time functions:
last_day_of_month,at_timezoneandwith_timezone.
Security #
- Role-based access control and related commands.
- INVOKER security mode for views, which allows views to be run using the permissions of the current user.
- Prevent replay attacks and result hijacking in client APIs.
- JWT-based internal communication authentication, which obsoletes the need to use Kerberos or certificates and greatly simplifies secure setups.
- Credential passthrough, which allows Presto to authenticate with the underlying data source with credentials provided by the user running a query. This especially useful when dealing with Google Storage in GCP or SQL databases that manage user authentication and authorization on their own.
- Impersonation for Hive metastore.
- Support for reading and writing encrypted files in HDFS using Hadoop KMS.
- Support for encrypting spilled data.
Geospatial #
- New geospatial functions:
ST_Points,ST_Length,ST_Area,line_interpolate_pointandline_interpolate_points. SphericalGeographytype and related functions to support spatial features in geographic coordinates (latitude / longitude) using a spherical model of the earth.- Support for Google Maps Polyline format via
to_encoded_polylineandfrom_encoded_polylinefunctions. geometry_from_hadoop_shapeto decode geometry objects in Spatial Framework for Hadoop representation
Cloud Integration #
- Support for Azure Data Lake Blob and ADLS Gen2 storage.
- Support for Google Cloud Storage.
- Several performance improvements for AWS S3.
CLI and JDBC Driver #
- JSON output format and improvements to CSV output format.
- Support and stability improvements for running the CLI and JDBC driver with Java 11.
- Improve compatibility of JDBC driver with third-party tools.
-
Syntax highlighting and multi-line editing.
New Connectors #
- Elasticsearch
- Google Sheets
- Amazon Kinesis
- Apache Phoenix
- MemSQL
- Apache Iceberg (preview version still under development)
Other Improvements #
Presto Docker image that provides an out-of-the-box single node cluster with the JMX, memory, TPC-DS, and TPC-H catalogs. It can be deployed as a full cluster by mounting in configuration and can be used for Kubernetes deployments.
- Support for LZ4 and Zstd compression in Parquet and ORC. LZ4 is currently the recommended algorithm for fast, lightweight compression, and Zstd otherwise.
- Support for insert-only Hive transactional tables and Hive bucketing v2 as part of making Presto compatible with Hive 3.
- Improvements in
ANALYZEstatement for Hive connector. - Support for multiple files per bucket for Hive tables. This allows inserting data into bucketed tables without having to rewrite entire partitions and improves Presto compatibility with Hive and other tools.
- Support for upper- and mixed-case table and column names in JDBC-based connectors.
- New features and improvements in type mappings in PostgreSQL, MySQL, SQL Server and Redshift
connectors. This includes support for PostgreSQL arrays and
timestamp with time zonetype, and the ability to read columns of unsupported types. - Improvements in Hive compatibility with Hive version 2.3 and with Cloudera (CDH)’s Hive.
- Connector provided view definitions, which allow connectors to generate the definition dynamically at query time. For example, the connector can provide a union of two tables filtered on a disjoint time range, with the cutoff time determined at resolution time.
- Lots and lots of bug fixes!
Coming Up… #
These are some of the projects that are currently in progress and are likely to land in the short term.
- Support for pushing down row dereference expressions into connectors. This will help reduce the amount of data and CPU needed to process highly nested columnar formats such as ORC and Parquet.
- Extend dynamic filtering to support distributed joins and other operators. Use dynamic filters for pruning partitions at runtime when querying Hive.
- Extended Late Materialization support to queries involving complex correlated subqueries.
- Finalize Hive 3 support.
- Improved INSERT into partitioned tables, which will help with large ETL queries.
- Improvements and features in Iceberg connector.
- Pinot connector.
- Oracle connector.
- Influx connector.
- Prometheus connector.
- Salesforce connector.
- Support for Confluent registry in Kafka connector.
- Revamp of the function registry and function resolution to support dynamically-resolved functions and SQL-defined functions.
- A new Parquet writer optimized to work efficiently within Presto.
… and many, many more.