Video
- Concept of the week: Query Planning (1231s)
- PR of the week: PR 730 Remove duplicate predicates (1795s)
- PR Demo: EXPLAIN LOGICAL and DISTRIBUTED demo (2027s)
- Question of the week: How should I allocate memory properties? (3289s)
Audio
Release 347
We discuss the Trino 347 release notes: https://trino.io/docs/current/release/release-347.html
Official release announcement from Martin Traverso:
We’re happy to announce the release of Presto 347! This version includes:
- Support for EXCEPT ALL and INTERSECT ALL
- New syntax for changing the owner of a view
- Performance improvements when inserting data into Hive tables
Notes from Manfred:
- contains_sequence function for arrays.
- CentOS 8 on docker image.
- Kudu get dynamic filtering.
Concept of the week: Query planning
- All happening on coordinator in cluster.
- Before a query can be planned, the coordinator receives a SQL query and passes it to a parser.
Parser/Analyzer
- The Parser parses the sql query into an AST (abstract syntax tree).
- Then the analyzer checks for valid SQL including functions and such.
Planner/Optimizer
- Request metadata about structure from catalogs.
- Do the tables and columns exist?
- What data types are used?
- Request metadata about content (table stats, data location).
- Create logical plan
- Are function parameters using right data types?
- What catalogs/schema/tables/columns need to be accessed?
- Are joins using compatible field data types?
- Optimize
- Eliminate redundant conditions.
- Figure best order of operations.
- Decide on filtering early.
- Create distributed plan (More on this in the next episode!)
- Break logical plan up.
- Adapt to parallel access by multiple workers to data source.
- Break up operations so workers aggregate and process data from other workers.
Use EXPLAIN to learn what is planned.
Also refer to chapter 4 in
Trino: The Definitive Guide
pg. 50.
PR of the week: PR 730 Remove duplicate predicates
In this week’s pull request https://github.com/trinodb/trino/pull/730, came from one of the co-creators Martin Traverso. This pull request removes duplicate predicates in logical binary expressions (AND, OR) and canonicalizes commutative arithmetic expressions and comparisons to handle a larger number of variants. Canonicalize is a big word but all it is saying is that if there are multiple representations of the same logic or data, then simplify it to a simpler or agreed upon normal form.
For example the statement COALESCE(a * (2 * 3), 1 - 1) is
equivalent to COALESCE(6 * a, 0) as the expression 2 * 3 can
be simplified to static integer.
This is an example of a logical plan because we are talking about the query syntax by optimizing the SQL. It differs from the distributed plan as we are not determining how the plan will be distributed, where this plan will run and it does not run further optimizations that are handled by the cost based optimizer such as pushdown predicates. We’ll talk about this step more in the next episode. For now let’s cover a few examples
Demo: PR 730 Remove duplicate predicates
The format of the EXPLAIN used is graphviz. The online tool used during the show is Viz.js. You can paste the output of your EXPLAIN queries to visualize the query in a tree form.
EXPLAIN (
FORMAT GRAPHVIZ,
TYPE LOGICAL
)
SELECT * FROM (VALUES 1) t(a) WHERE a = 1 OR 1 = a OR a = 1;
EXPLAIN (
FORMAT GRAPHVIZ,
TYPE LOGICAL
)
SELECT * FROM (VALUES 1) t(a) WHERE a = 2 OR 1 = a OR a = 3;
EXPLAIN (
FORMAT GRAPHVIZ,
TYPE DISTRIBUTED
)
SELECT * FROM tpch.tiny.orders
WHERE custkey > 100 and custkey > 50 and custkey > 50 and custkey > 50 and custkey > 50;
SELECT *
FROM tpch.tiny.orders o
JOIN tpch.tiny.customer c
ON o.custkey = c.custkey AND o.custkey > 50
WHERE c.custkey > 100 AND c.custkey > 50 LIMIT 10;Question of the week: How should I allocate memory properties?
In this week’s question, we answer:
How should I allocate memory properties? CPU : 16Core MEM:64GB
Before answering this, we should make sure a few things about memory are clear.
User memory
Space needed that the user is capable of reasoning about:
- Input Data
- Hash tables execution
- Sorting
Settings
query.max-memory-per-node- maximum amount of user memory that a query is allowed to use on a given worker.query.max-memory(without the -per-node at the end) - This config caps the amount of user memory used by a single query over all worker nodes in your cluster.
System memory
Memory needed to facilitate internal usage
- Shuffle buffers
NOTE: There are no settings for this memory as it is implicitly set by the user and total memory settings. Use this to calculate system memory:
- max system memroy per node =
query.max-total-memory-per-node-query.max-memory-per-node - max system memory =
query.max-total-memory-query.max-memory
Total memory
Total Memory = System + User, but there are only properties for total and user memory.
Settings
query.max-total-memory-per-node- maximum amount of total memory that a query is allowed to use on a given worker.query.max-total-memory(without the -per-node at the end) - This config caps the total memory used by a single query over all worker nodes in your cluster.
Heap headroom
The final setting I would like to cover is the
memory.heap-headroom-per-node. This config sets aside memory for the
JVM heap for allocations that are not tracked by Presto. You can typically go
with the default on this setting which is 30% of the JVM’s max heap size
(-Xmx setting).
JVM heap memory (-Xmx setting)
Now knowing that Presto is a java application means it runs on the JVM. None of these memory settings mean anything until we actually have the JVM that Presto is running on set aside sufficient memory. So how do I know I am setting sufficient memory based on my settings?
query.max-total-memory-per-node + memory.heap-headroom-per-node <
-Xmx setting (Java heap)
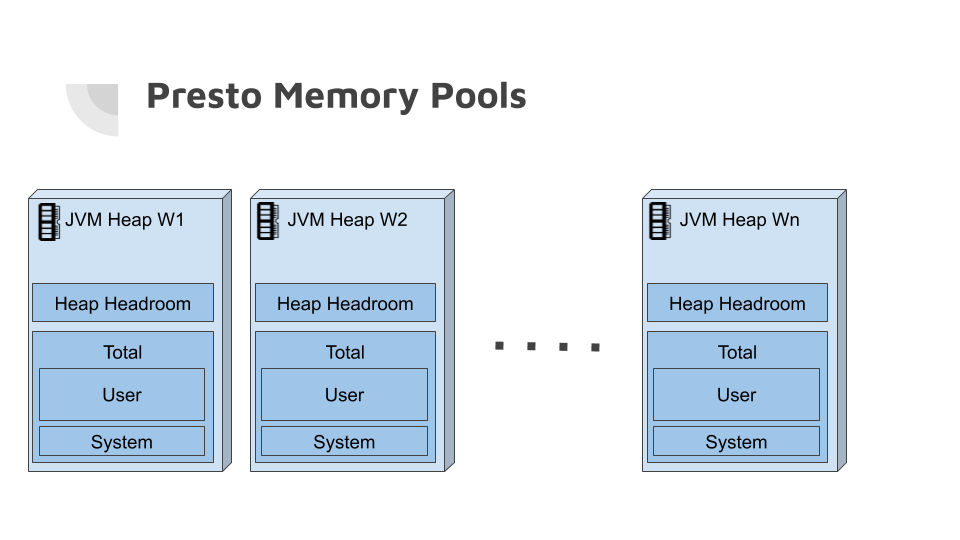
Dain really covers the proportions well in detail on the recent training videos. Here’s a snippet of what he recommends.
All in all, try to estimate the amount of memory needed by your max anticipated query load, and if possible try to get even more than your estimate. Once Presto is discovered by users, they will start to use it even more and demands on the system will grow.
Events, news, and various links
Blogs
- https://trino.io/blog/2019/05/21/optimizing-the-casts-away.html
- https://towardsdatascience.com/statistics-in-spark-sql-explained-22ec389bf71b
- https://www.infoworld.com/article/3597971/on-premises-data-warehouses-are-dead.html
- https://www.javahelps.com/2019/11/presto-sql-join-algorithms.html
Upcoming events
- Dec 8 https://www.meetup.com/Warsaw-Data-Engineering/events/274939817/
- Dec 9 https://techtalksummits.com/event/virtual-commercial-it-providence-ri/
- Dec 10 https://techtalksummits.com/event/virtual-commercial-it-denver-co/
- Dec 10 https://www.evanta.com/cdo/san-francisco/2020-san-francisco-cdo-virtual-executive-summit
- Dec 16 https://www.evanta.com/cdo/boston/2020-boston-cdo-virtual-executive-summit
Latest training from David, Dain, and Martin(Now with timestamps!):
- https://trino.io/blog/2020/07/15/training-advanced-sql.html
- https://trino.io/blog/2020/07/30/training-query-tuning.html
- https://trino.io/blog/2020/08/13/training-security.html
- https://trino.io/blog/2020/08/27/training-performance.html
Presto Summit Series - Real world usage
- https://trino.io/blog/2020/05/15/state-of-presto.html
- https://trino.io/blog/2020/06/16/presto-summit-zuora.html
- https://trino.io/blog/2020/07/06/presto-summit-arm-td.html
- https://trino.io/blog/2020/07/22/presto-summit-pinterest.html
Podcasts:
- Presto with Martin Traverso, Dain Sundstrom and David Phillips
- Simplify Your Data Architecture With The Presto Distributed SQL Engine
- How Open Source Presto Unlocks a Single Point of Access to Data
- The Data Access Struggle is Real
- Presto with Justin Borgman
- The infrastructure renaissance and how it will power the modernization of analytics platforms
- Uber’s Data Platform with Zhenxiao Luo
If you want to learn more about Presto yourself, you should check out the O’Reilly Trino Definitive guide. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.