Video
- Concept of the week: Apache Iceberg and the table format (1034s)
- PR of the week: PR 1067 Add Iceberg connector (3562s)
- Demo: Creating tables with Iceberg and reading the data in Trino (3844s)
- Question of the week: Why does Trino still depend on the Hive metastore if metadata for Iceberg saves to the filesystem? (4719s)
Audio

March of the Trinos! Be careful Commander Bun Bun! That Iceberg doesn't look stable!
https://joshdata.me/iceberger.html
Iceberg links
Guests
- David Phillips, creator of Trino/Presto, and CTO at Starburst (@electrum32)
Release 354
Release notes discussed: https://trino.io/docs/current/release/release-354.html
Martin’s list:
- Support for OAuth 2.0 in CLI
- Support for MemSQL 3.2
- Pushdown of ORDER BY … LIMIT for MemSQL, MySQL and SQL Server connectors
- Support for time(p) in SQL Server
Manfred’s notes:
- LEFT, RIGHT and FULL JOIN
- Preferred write partitioning on by default (needs statistics)
- Small but useful fix on Elasticsearch (single value array)
- Hive connector
- Fix ACID table DELETE and UPDATE - critical fix is in! Boom!
- Avro format improvement
- CSV and Glue metadata improvement
- Iceberg - date and timestamp improvement
- CREATE SCHEMA fixes in MySQL, PostgreSQL, Redshift and SQL Server
- Bunch of other fixes in those connectors
Concept of the week: Apache Iceberg and the table format
The Hive table format
For the last decade or so, big data professionals’ only option to query their data was to, in some way shape or form, use the Hive model. The Hive model is very simple, but it enabled running queries over files in a distributed file system.
To accomplish this, Hive uses a metastore service which stores and manages metadata. For Hive and Trino, this metadata acts as a pointer to the files containing the data, contains the file format, and has the column structure and types. This enabled Hive to query the correct files and data within those files for a SQL query. For more information on Hive’s architecture, read the Gentle Introduction to Hive blog. After the initial model gained adoption, Hive added other features such as partitioning. It uses the directory structures of the filesystems to split the files of data partitioned on a special column into different directories. We talk about this in more depth a few episodes back.
The Hive model solved some initial issues facing engineers in big data, but there were quite a few issues with this model. It is very rigid and not able to adapt to your needs as requirements change. For example, if you started partitioning your data splitting by date and segmenting by month, that table is stuck with that partitioning forever. The only way to update it is to create a new table with your new partition values, and migrate all of your data from the old table to the new table. With the common data sizes such a migration is often a long process, sometimes even impossible. Another issue stems from the separation of data stored in the metastore and data stored in the file system. The source of many issues in Hive is caused by the Hive metastore getting out of sync. A third but not final issue, is that running operations against the metastore is a timely process when running operations like list files on more modern object storage.
As all these problems amassed over the years, clearly something needed to be done. In the last few years, a few candidate table formats have come to the forefront of data engineering trends. Examples are, Apache Iceberg, Apache Hudi, and the proprietary Databricks’ Deltalake. The goal of these systems is to modernize the old Hive data structure. To Trino, Iceberg is particularly promising due to the list of promising features like schema versioning support and hidden partitioning that made it particularly attractive. Let’s talk about some of these features in detail.
The Iceberg table format
Iceberg, is a new table format developed at Netflix that aims to replace older table formats like Hive to add better flexibility as the schema evolves, atomic operations, speed, and just dependability. To be clear, it’s not a new file format, as it still uses ORC, Parquet, and Avro, but a table format. Netflix donated Iceberg to the Apache Software Foundation and it is now a top level project!
Iceberg handles both the data on disk just like Hive, but instead it stores the metadata in manifest files on disk along with the data itself. These manifest files are AVRO files that contain table metadata that lists a subset of data files. Manifest lists are a special type of manifest file that point to other manifest files. Snapshots contain a manifest list that points to all the manifest files that belong to the snapshot. Another huge difference from Hive is that the manifest files keep track of table data at the file level as opposed to directory level that Hive uses. By doing so, Iceberg avoids having to list all files in a directory, which becomes a very common and expensive operation.
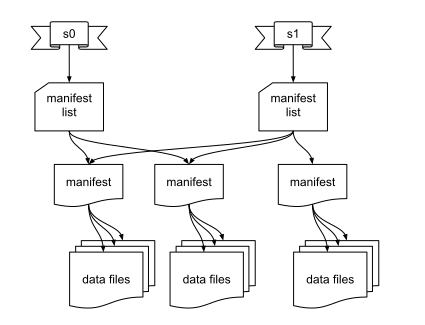
By tracking files this way, we not only get better performance from object storage, it also enables serializable isolation. This addresses the lack of consistency between the metadata and file state experienced in Hive.
One of the greater advantages to Iceberg over Hive is the in-place table evolution. This means that you can add, drop, or rename a column, as well as, reorder and update a column without any expensive refactoring of tables or moving data around and there is no adverse effects on your data or metadata.
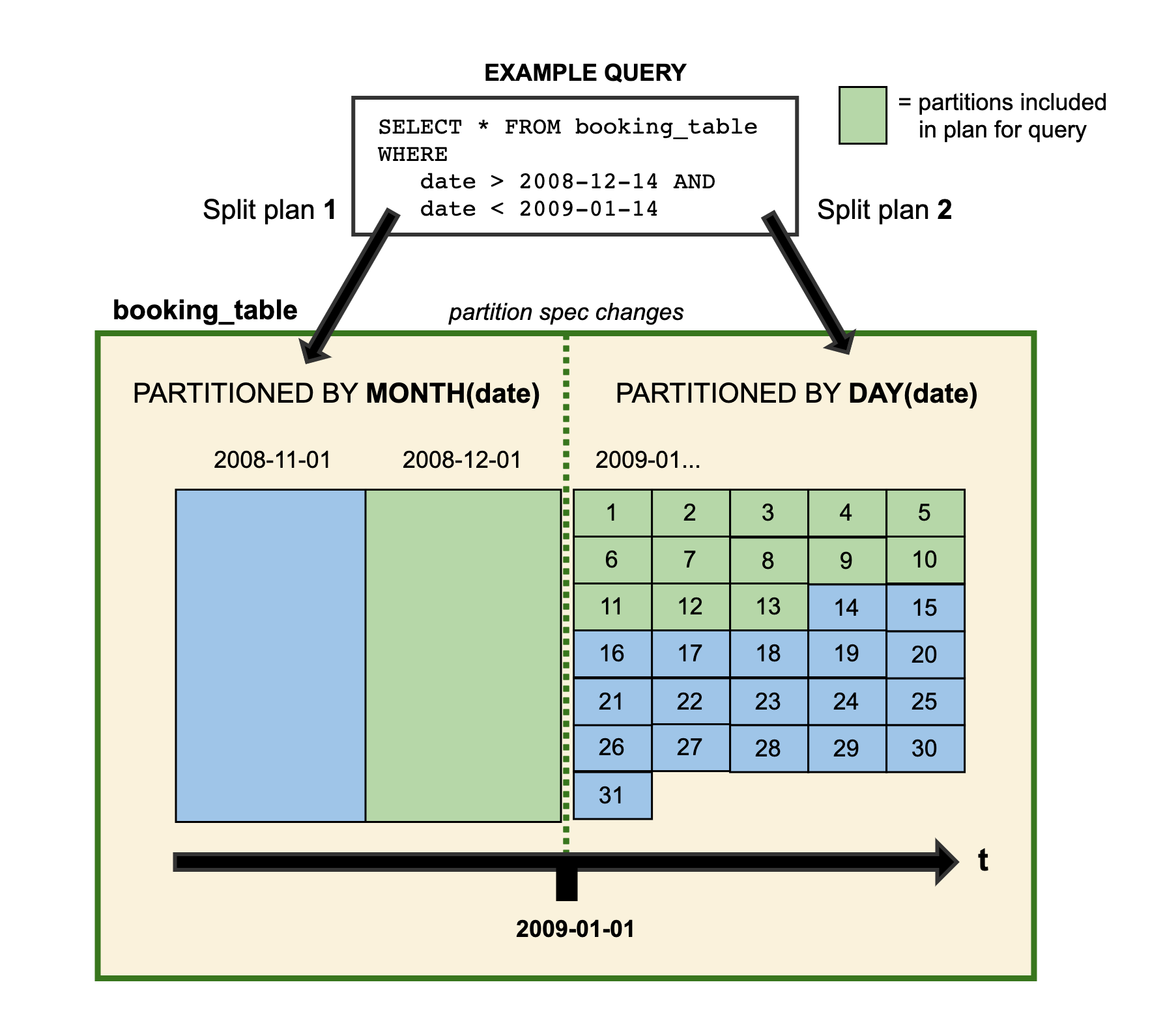
Partition evolution and hidden partitions are particularly invaluable. In Iceberg, the partition spec is a description of how to partition data in a table consisting of a list of source columns and transforms. Once the spec is created, it generates a partition tuple that is applied uniformly to the files created with that spec. Unlike Hive, that requires you to modify and send a special column that acts as the partition value, Iceberg stores partition values unmodified. Here’s an example partition spec generated in the Java API.
PartitionSpec spec = PartitionSpec.builderFor(schema)
.hour("event_time")
.identity("level")
.build();
This example creates a separate hourly partition on the event_time field and
use the identity() function on level to generate another level of partitioning
on the level field. If at a later time, you decide you are getting too many
small files because your partitions are too small, then you can update the
partition spec and Iceberg starts writing new files by the updated spec.
Again, this is all without creating a new table and moving data around and all
the queries return correctly. This kind of evolution is a problem with Hive.
If all that isn’t enough, you can also do time travel and version rollback with Iceberg. As we mentioned above, Iceberg keeps track of various snapshots of your data in time through manifest files. As long as you keep those older snapshots around, the files associated with those snapshots stick around as well. This allows you to move around to previous views of the data. This is useful for testing, recovery, and many other purposes. Just as you can time travel, you can make the time travel permanent by rolling back any unintended changes and deleting the undesired snapshot.
Iceberg is also able to offer fast scan planning by filtering out the metadata files that are irrelevant to the scan, and using the partition spec to only find files containing responses to the data. Iceberg filters the metadata using partition value ranges and seeing if that is contained within the files of the metadata. Then while processing the list of manifest files, Iceberg will filter files by query predicates included in the partition, then apply column stats to help prune out files that don’t match. Iceberg also uses multiple concurrent writers to speed things up as a final measure.
Saving the best for last; Iceberg is a community standard and has a full written specification which is a nice change from Hive which is an ad-hoc specification that people adhere to in some ways. There have been many issues over the years due to the variance of how the unwritten specification gets interpreted. This not only enables people to understand how to use it, but documents how others can implement the same features with an entirely different systems. Let’s wait to do a deep dive on the spec for the next episode when we bring on Ryan Blue, creator of Iceberg, to dig into these details.
PR of the week: PR 1067 Add Iceberg connector
A huge shoutout goes to Parth Brahmbhatt, a Senior Software Engineer at Netflix who created this weeks’ PR of the week.
Release 318, introduced this code that supported querying tables from Apache Iceberg in Trino. While the code existed, the Iceberg connector code wasn’t officially released or documented until a little over a year later in release 341 once the connector reached maturity.
Future development for the Trino Iceberg connector
Still, some strange artifacts that we’re still facing today in the connector. For example, if you create a table with the Iceberg Java API, it creates Iceberg tables with <table_type, ICEBERG> but Trino creates and reads with <table_type, iceberg>. See Issue 1592 for status and details. In general, we can track some of the broader changes that are being made to the Iceberg connector here.
Demo: Creating tables with Iceberg and reading the data in Trino
For this weeks’ demo, I wanted to play around with the Iceberg Java API directly. You also have the option to use Trino, Spark, or other to ingest and query the data, but I wanted to use vanilla Iceberg API’s to experience the API and hopefully solidify my learning of Iceberg concepts in the process. Make sure you follow the instructions in the repository if you don’t have Docker or Java installed.
Let’s start up a local Trino coordinator and Hive metastore. Clone this
repository and navigate to the iceberg/trino-iceberg-minio directory. Then
start up the containers using Docker Compose.
git clone [email protected]:bitsondatadev/trino-getting-started.git
cd iceberg/trino-iceberg-minio
docker-compose up -d
In your favorite IDE, open the files under iceberg/iceberg-java into your
project and run the IcebergMain class.
This class creates a logging table if it doesn’t exist. Once you run this code,
you can check to see that the table in Trino exists in the metastore under
TABLE_PARAMS. But, if run SHOW TABLES IN iceberg.logging; you’ll notice that
the table doesn’t show up due to the issue we discussed above.
Let’s update the TABLE_PARAMS entry in the metastore db and then query the table again.
Question of the week: Why does Trino still depend on the Hive metastore if metadata for Iceberg saves to the filesystem?
We kept the metastore as many tests run around using the metastore that exist for the Hive connector, and we want to give the Iceberg connector ample time to mature before we migrate entirely away from the metastore. We also wanted to make the metastore the initial method of use in Iceberg that got developed as most developers initially would be migrating from their existing Hive catalog, and we wanted this transition to use existing tested components.
Currently, the metastore isn’t used the same way as in Hive. Trino stores a top-level directory that points to the metadata manifest file location and other statistics around the table in the TABLE_PARAMS table of the metastore. There is a pull request created by Jack Ye to migrate away from the requirement to use the Hive metastore when using Iceberg with Trino.
Tip of the Iceberg
Last bit of some fun with Iceberg. Let’s do a little experiment called, “Will the iceberg tip?”:
- Go to https://iceberg.apache.org/ and take a look at the logo.
- Now go to https://joshdata.me/iceberger.html.
- Draw the Apache Iceberg logo and see what happens.
- Now draw the iceberg in the image above that Commander Bun Bun is on.
When drawing the iceberg like the image with Commander Bun Bun, the iceberg tips over. Careful Commander Bun Bun! It looks like the Apache logo wins! Shout out to Joshua Tauberer for the web page. Shout out to Megan Thompson-Munson for the tweet that started the page. Shout out to Barton Wright from Manfred’s team of writers for being the geek to find this. Shout out to Ali for being a good sport and setting Command Bun Bun on the iceberg.
Events, news, and various links
Come join us for the inaugural Virtual Trino meetup on April 21st in the virtual meetup group in your region!
At this meetup, the four Trino/Presto founders will be updating everyone on the state of Trino. We’ll discuss the rebrand, talk about the recent features, and discuss the trajectory of the project. Then we will host a hangout and AMA. Hope to see you all there!
Blogs
- Trino on ice I: A gentle introduction to Iceberg
- Trino on ice II: In-place table evolution and cloud compatibility with Iceberg
- Trino on ice III: Iceberg concurrency model, snapshots, and the Iceberg spec
- Trino on ice IV: Deep dive into Iceberg internals
- https://medium.com/expedia-group-tech/a-short-introduction-to-apache-iceberg-d34f628b6799
- https://engineering.linkedin.com/blog/2021/fastingest-low-latency-gobblin
- https://medium.com/adobetech/iceberg-at-adobe-88cf1950e866
- https://medium.com/adobetech/high-throughput-ingestion-with-iceberg-ccf7877a413f
- https://medium.com/adobetech/taking-query-optimizations-to-the-next-level-with-iceberg-6c968b83cd6f
- https://thenewstack.io/apache-iceberg-a-different-table-design-for-big-data/
Videos
- https://www.youtube.com/watch?v=mf8Hb0coI6o
- https://www.youtube.com/watch?v=Kxbzr7UP1dI&t=1274s
- https://www.youtube.com/watch?v=QNmSXMQ-gY4
Trino Meetup Groups
- Virtual
- East Coast (US)
- West Coast (US)
- Mid West (US)
Latest training from David, Dain, and Martin(Now with timestamps!):
- https://trino.io/blog/2020/07/15/training-advanced-sql.html
- https://trino.io/blog/2020/07/30/training-query-tuning.html
- https://trino.io/blog/2020/08/13/training-security.html
- https://trino.io/blog/2020/08/27/training-performance.html
If you want to learn more about Trino, check out the definitive guide from OReilly. You can download the free PDF or buy the book online.
Music for the show is from the Megaman 6 Game Play album by Krzysztof Słowikowski.